kstest
Prueba de Kolmogorov-Smirnov para una muestra
Descripción
h = kstest(x)x proceden de una distribución normal estándar, frente a la alternativa de que no procede de tal distribución, usando la prueba de Kolmogorov-Smirnov de una muestra. El resultado h es 1 si la prueba rechaza la hipótesis nula al nivel de significación del 5%, o 0 en el caso contrario.
h = kstest(x,Name,Value)
Ejemplos
Prueba de la distribución normal estándar
Realice la prueba de Kolmogorov-Smirnov de una muestra mediante kstest. Confirme la decisión de la prueba comparando visualmente la función de distribución acumulativa (cdf) empírica con la cdf normal estándar.
Cargue el conjunto de datos examgrades. Cree un vector que contenga la primera columna de los datos de notas de exámenes.
load examgrades
test1 = grades(:,1);Pruebe la hipótesis nula de que los datos provienen de una distribución normal con una media de 75 y una desviación estándar de 10. Utilice estos parámetros para centrar y ampliar cada elemento del vector de datos, ya que kstest comprueba una distribución normal estándar de manera predeterminada.
x = (test1-75)/10; h = kstest(x)
h = logical
0
El valor devuelto de h = 0 indica que kstest no rechaza la hipótesis nula al nivel de significación predeterminado del 5%.
Represente la cdf empírica y la cdf normal estándar para compararlas visualmente.
cdfplot(x) hold on x_values = linspace(min(x),max(x)); plot(x_values,normcdf(x_values,0,1),'r-') legend('Empirical CDF','Standard Normal CDF','Location','best')
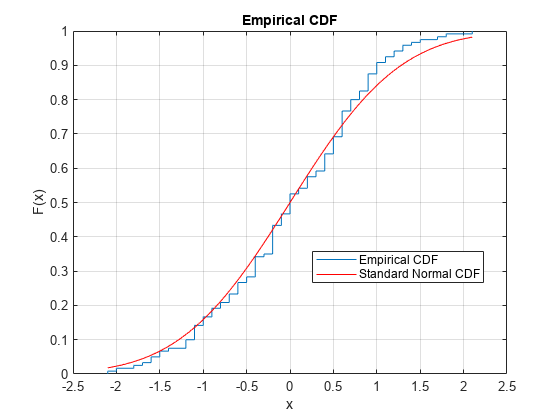
La figura muestra la similitud entre la cdf empírica del vector de datos centrado y ampliado y la cdf de la distribución normal estándar.
Especificar la distribución hipotética utilizando una matriz de dos columnas
Cargue los datos de muestra. Cree un vector que contenga la primera columna de los datos de las notas de los alumnos en un examen.
load examgrades;
x = grades(:,1);Especifique la distribución hipotética como una matriz de dos columnas. La columna 1 contiene el vector de datos x. La columna 2 contiene los valores de la cdf evaluados en cada valor de x para una distribución hipotética de Student con un parámetro de ubicación de 75, un parámetro de escala de 10 y un grado de libertad.
test_cdf = [x,cdf('tlocationscale',x,75,10,1)];Pruebe si los datos proceden de la distribución hipotética.
h = kstest(x,'CDF',test_cdf)h = logical
1
El valor devuelto de h = 1 indica que kstest rechaza la hipótesis nula al nivel de significación predeterminado del 5%.
Especificar la distribución hipotética utilizando un objeto de distribución de probabilidad
Cargue los datos de muestra. Cree un vector que contenga la primera columna de los datos de las notas de los alumnos en un examen.
load examgrades;
x = grades(:,1);Cree un objeto de distribución de probabilidad para probar si los datos proceden de una distribución de Student con un parámetro de ubicación de 75, un parámetro de escala de 10 y un grado de libertad.
test_cdf = makedist('tlocationscale','mu',75,'sigma',10,'nu',1);
Pruebe la hipótesis nula de que los datos proceden de la distribución hipotética.
h = kstest(x,'CDF',test_cdf)h = logical
1
El valor devuelto de h = 1 indica que kstest rechaza la hipótesis nula al nivel de significación predeterminado del 5%.
Probar la hipótesis con distintos niveles de significación
Cargue los datos de muestra. Cree un vector que contenga la primera columna con las notas de los alumnos en un examen.
load examgrades;
x = grades(:,1);Cree un objeto de distribución de probabilidad para probar si los datos proceden de una distribución de Student con un parámetro de ubicación de 75, un parámetro de escala de 10 y un grado de libertad.
test_cdf = makedist('tlocationscale','mu',75,'sigma',10,'nu',1);
Pruebe la hipótesis nula de que los datos proceden de la distribución hipotética a un nivel de significación del 1%.
[h,p] = kstest(x,'CDF',test_cdf,'Alpha',0.01)
h = logical
1
p = 0.0021
El valor devuelto de h = 1 indica que kstest rechaza la hipótesis nula al nivel de significación del 1%.
Realizar una prueba de hipótesis unilateral
Cargue los datos de muestra. Cree un vector que contenga la tercera columna de la matriz de datos sobre rentabilidad de acciones.
load stockreturns;
x = stocks(:,3);Pruebe la hipótesis nula de que los datos proceden de una distribución normal estándar, frente a la hipótesis alternativa de que la cdf de la población de los datos es mayor que la cdf normal estándar.
[h,p,k,c] = kstest(x,'Tail','larger')
h = logical
1
p = 5.0854e-05
k = 0.2197
c = 0.1207
El valor devuelto de h = 1 indica que kstest rechaza la hipótesis nula a favor de la hipótesis alternativa en el nivel de significación predeterminado del 5%.
Represente la cdf empírica y la cdf normal estándar para compararlas visualmente.
[f,x_values] = ecdf(x); J = plot(x_values,f); hold on; K = plot(x_values,normcdf(x_values),'r--'); set(J,'LineWidth',2); set(K,'LineWidth',2); legend([J K],'Empirical CDF','Standard Normal CDF','Location','SE');
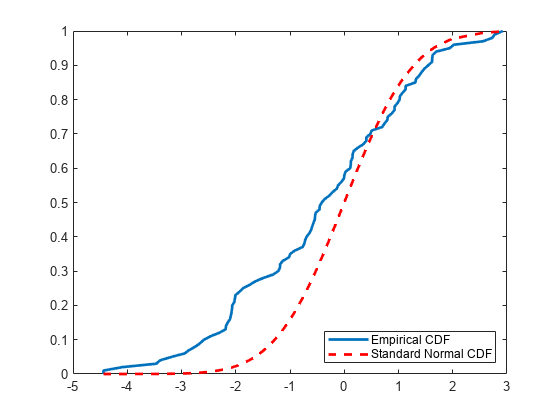
En la gráfica se muestra la diferencia entre la cdf empírica del vector de datos x y la cdf de la distribución normal estándar.
Argumentos de entrada
Argumentos de salida
Más acerca de
Algoritmos
kstest decide rechazar la hipótesis nula comparando el valor p p con el nivel de significación Alpha, no comparando la estadística de prueba ksstat con el valor crítico cv. Puesto que cv es aproximado, comparar ksstat con cv ocasionalmente lleva a una conclusión distinta que comparar p con Alpha.
Referencias
[1] Massey, F. J. “The Kolmogorov-Smirnov Test for Goodness of Fit.” Journal of the American Statistical Association. Vol. 46, No. 253, 1951, pp. 68–78.
[2] Miller, L. H. “Table of Percentage Points of Kolmogorov Statistics.” Journal of the American Statistical Association. Vol. 51, No. 273, 1956, pp. 111–121.
[3] Marsaglia, G., W. Tsang, and J. Wang. “Evaluating Kolmogorov’s Distribution.” Journal of Statistical Software. Vol. 8, Issue 18, 2003.
Historial de versiones
Introducido antes de R2006a
Consulte también
kstest2 | lillietest | adtest
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)