AI for Audio
Audio Toolbox™ provides functionality to develop machine and deep learning solutions for audio, speech, and acoustic applications including speaker identification, speech command recognition, speech separation, acoustic scene recognition, denoising, and many more.
Use
audioDatastoreto ingest large audio data sets and process files in parallel.Use Signal Labeler to build audio data sets by annotating audio recordings manually and automatically.
Use
audioDataAugmenterto create randomized pipelines of built-in or custom signal processing methods for augmenting and synthesizing audio data sets.Use
audioFeatureExtractorto extract combinations of different features while sharing intermediate computations.
Audio Toolbox also provides access to third-party APIs for text-to-speech and speech-to-text, and it includes pretrained models so that you can perform transfer learning, classify sounds, and extract feature embeddings. Using pretrained networks requires Deep Learning Toolbox™.
Categories
- Applications
Apply AI workflows to audio applications
- Dataset Management and Labeling
Ingest, create, and label large data sets
- Feature Extraction
Mel spectrogram, MFCC, pitch, spectral descriptors
- Data Augmentation
Augmentation pipelines, shift pitch and time, stretch time, control volume and noise
- Segmentation
Detect and isolate speech and other sounds
- Pretrained Models
Transfer learning, sound classification, feature embeddings, pretrained audio deep learning networks
- Speech Transcription and Synthesis
Use pretrained models or third-party APIs for text-to-speech and speech-to-text
- Code Generation and GPU Support
Generate portable C/C++/MEX functions and use GPUs to deploy or accelerate processing
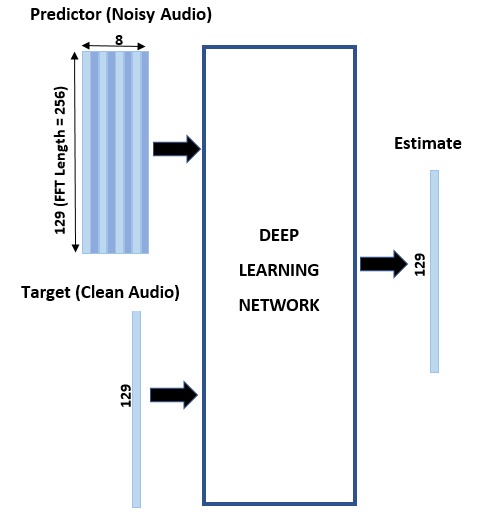
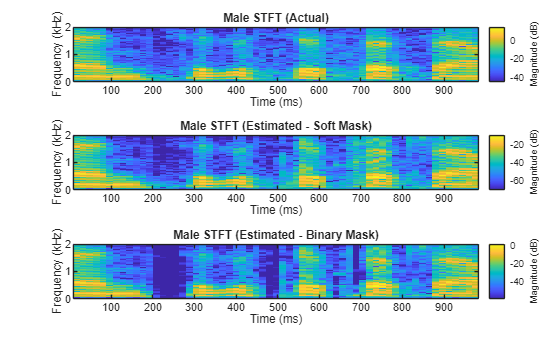
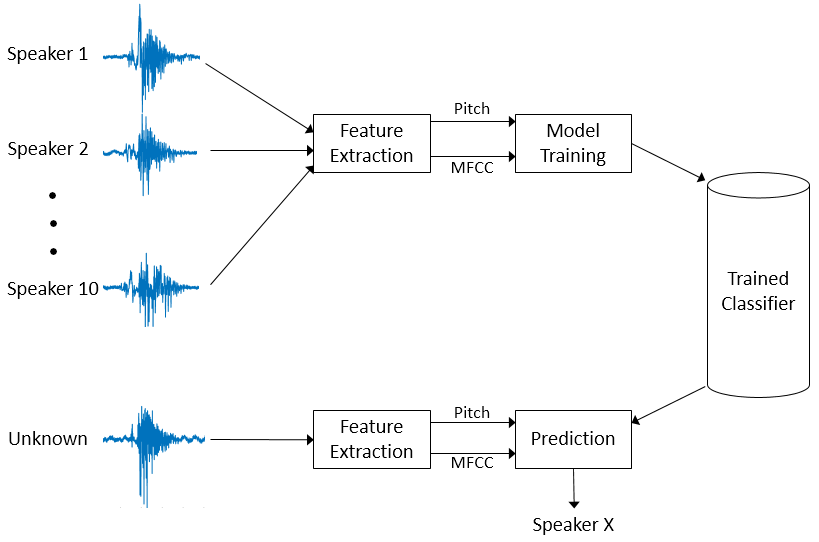
Featured Examples








You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)