Computer Vision Toolbox
Diseñe y pruebe sistemas de procesamiento de vídeos, visión artificial y visión en 3D
¿Tiene preguntas? Comuníquese con ventas.
¿Tiene preguntas? Comuníquese con ventas.
Computer Vision Toolbox proporciona algoritmos, funciones y apps para diseñar y probar sistemas de procesamiento de vídeos, visión artificial y visión en 3D. Puede realizar detección y seguimiento de objetos, así como detección, extracción y coincidencia de características. Puede automatizar los flujos de trabajo de calibración de cámaras simples, estéreo y ojo de pez. En el caso de la visión en 3D, la toolbox soporta SLAM visual y de nubes de puntos, visión estéreo, estructura a partir del movimiento y procesamiento de nubes de puntos. Las apps de visión artificial automatizan los flujos de trabajo de etiquetado de validación ground-truth y de calibración de cámaras.
Puede entrenar detectores de objetos personalizados utilizando algoritmos de Deep Learning y Machine Learning tales como YOLO, SSD y ACF. Para la segmentación semántica y de instancias, puede utilizar algoritmos de Deep Learning tales como U-Net y Mask R-CNN. La toolbox ofrece algoritmos de detección y segmentación de objetos para analizar imágenes que son demasiado grandes para la capacidad de la memoria. Los modelos previamente entrenados permiten el reconocimiento facial y detección de peatones y otros objetos comunes.
Puede acelerar los algoritmos ejecutándolos en procesadores multinúcleo y GPU. Los algoritmos de esta toolbox soportan la generación de código C/C++ para su integración con el código existente, el prototipado de escritorio y el despliegue de sistemas de visión artificial integrada.
Automatice el etiquetado para detección de objetos, segmentación semántica, segmentación de instancias y clasificación de escenas con las apps Video Labeler e Image Labeler.

Entrene o utilice redes previamente entrenadas de segmentación y detección de objetos basadas en Deep Learning y Machine Learning. Evalúe el rendimiento de esas redes y despliéguelas como código C/C++ o CUDA®.

Utilice la librería Automated Visual Inspection de Computer Vision Toolbox para identificar anomalías o defectos a fin de ayudar y mejorar los procesos de control de calidad en la industria de la fabricación.

Estime los parámetros intrínsecos, extrínsecos y de distorsión de lentes de cámaras monoculares y estereoscópicas con las apps Camera Calibrator y Stereo Camera Calibrator.

Extraiga la estructura en 3D de una escena a partir de varias vistas en 2D. Estime el movimiento y la posición de la cámara mediante odometría visual. Ajuste las estimaciones de posición con SLAM visual.
Realice segmentación, agrupación en cluster, disminución de la tasa de muestreo, eliminación de ruido, registro y ajuste de formas geométricas con datos de nube de puntos de sensores LiDAR, estéreo o RGBD. Lidar Toolbox ofrece funcionalidades adicionales para diseñar, analizar y probar sistemas de procesamiento de datos de LiDAR.

Detecte, identifique coincidencias y extraiga características, tales como blobs, bordes y esquinas, en diversas imágenes. Las características identificadas en las imágenes se pueden utilizar para registro o identificación de objetos, o en flujos de trabajo complejos tales como SLAM.

Estime el movimiento y realice el seguimiento de objetos en secuencias de vídeos e imágenes.
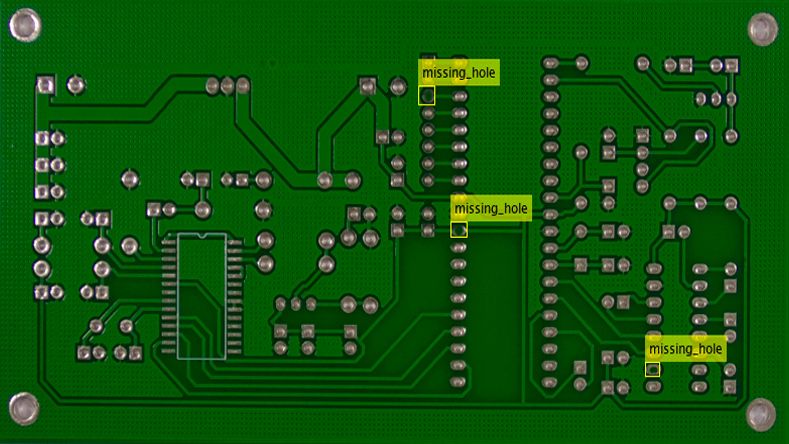
Integre el desarrollo de algoritmos de visión artificial con flujos de trabajo de prototipado rápido, implementación y verificación. Integre funciones y proyectos basados en OpenCV en MATLAB y Simulink.

“MATLAB incluye todas las herramientas que necesitamos para anotar datos, y seleccionar, entrenar, probar y ajustar un modelo de Deep Learning. Con GPU Coder, pudimos desplegar rápidamente en GPU de NVIDIA, a pesar de tener poca experiencia con GPU”.
Valerio Imbriolo, Drass Group
30 días de exploración a su alcance.
Obtenga información sobre precios y explore productos relacionados.
Es posible que su centro educativo ya ofrezca acceso a MATLAB, Simulink y otros productos complementarios mediante una infraestructura Campus-Wide License.
También puede seleccionar uno de estos países/idiomas:
América
Europa
Asia-Pacífico



