Información sobre la diferenciación automática
¿Qué es la diferenciación automática?
La diferenciación automática (también conocida como autodiff, AD o diferenciación algorítmica) es una herramienta muy utilizada en deep learning. Resulta especialmente útil para crear y entrenar modelos de deep learning complejos sin necesidad de calcular derivadas manualmente para la optimización. Para obtener ejemplos que muestren cómo crear y personalizar modelos, bucles de entrenamiento y funciones de pérdida de deep learning, consulte Custom Training Loops.
La diferenciación automática es un conjunto de técnicas para evaluar derivadas (gradientes) numéricamente. El método utiliza reglas simbólicas para la diferenciación, que son más precisas que las aproximaciones de diferencias finitas. A diferencia de un enfoque puramente simbólico, la diferenciación automática evalúa numéricamente expresiones al comienzo de los cálculos en lugar de llevar a cabo cálculos simbólicos grandes. En otras palabras, la diferenciación automática evalúa derivadas en determinados valores numéricos; no crea expresiones simbólicas para derivadas.
El modo directo evalúa una derivada numérica realizando operaciones elementales con derivadas y operaciones de evaluación de la propia función de manera simultánea. Tal como se detalla en la siguiente sección, el software realiza estos cálculos en un grafo computacional.
La diferenciación automática en modo inverso utiliza una extensión del grafo computacional del modo directo para habilitar el cálculo de un gradiente mediante un recorrido inverso por el grafo. A medida que el software ejecuta el código para calcular la función y su derivada, registra operaciones en una estructura de datos que se conoce como rastreo.
Tal como han observado muchos investigadores (como Baydin, Pearlmutter, Radul y Siskind [1]), para una función escalar de muchas variables, el modo inverso calcula el gradiente de manera más eficiente que el modo directo. Dado que una función de pérdida de deep learning es una función escalar de todos los pesos, la diferenciación automática de Deep Learning Toolbox™ utiliza el modo inverso.
Modo directo
Considere el problema de evaluar esta función y su gradiente:
La diferenciación automática funciona en puntos concretos. En este caso, tome x1 = 2, x2 = 1/2.
El siguiente grafo computacional codifica el cálculo de la función f(x).
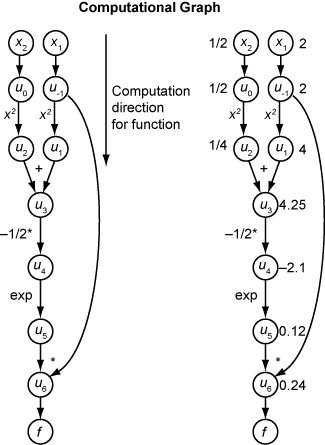
Para calcular el gradiente de f(x) usando el modo directo, puede calcular el mismo grafo en la misma dirección, pero debe modificar el cálculo en función de las normas elementales de diferenciación. Para simplificar más el cálculo, puede rellenar el calor de la derivada de cada subexpresión ui a medida que avance. Para calcular el gradiente completo, debe recorrer el grafo dos veces, una vez para la derivada parcial respecto a cada una de las variables independientes. Cada subexpresión de la regla de la cadena tiene un valor numérico, por lo que toda la expresión tiene la misma clase de grafo de evaluación que la propia función.
El cálculo es una aplicación repetida de la regla de la cadena. En este ejemplo, la derivada de f respecto a x1 se expande a esta expresión:
Sea la representación de la derivada de la expresión ui con respecto a x1. Usar los valores evaluados de ui de la evaluación de la función permite calcular la derivada parcial de f con respecto a x1, como se muestra en la siguiente figura. Observe que todos los valores de se convierten en disponibles a medida que recorre el grafo de arriba abajo.
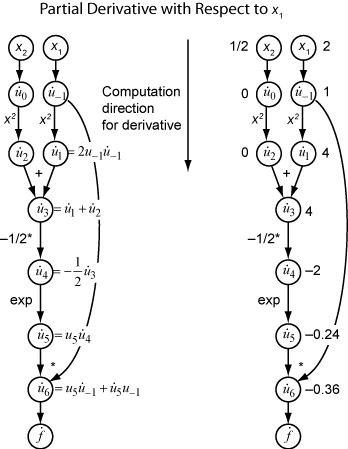
Para calcular la derivada parcial con respecto a x2, puede recorrer un grafo computacional similar. Por lo tanto, cuando calcula el gradiente de la función, el número de recorridos por el grafo es el mismo que el número de variables. Este proceso es demasiado lento para las aplicaciones de deep learning habituales, que tienen miles o millones de variables.
Modo inverso
El modo inverso usa un recorrido directo por un grafo computacional para configurar el rastreo. Después, calcula el gradiente completo de la función en un recorrido por el grafo en la dirección opuesta. Para aplicaciones de deep learning, este modo es mucho más eficiente.
La teoría que sustenta el modo inverso también se basa en la regla de la cadena, junto con variables adjuntas asociadas denotadas por una barra situada encima de ellas. La variable adjunta para ui es
En términos del grafo computacional, cada flecha saliente de una variable contribuye a la variable adjunta correspondiente por su término en la regla de la cadena. Por ejemplo, la variable u–1 tiene flechas salientes hacia dos variables, u1 y u6. El grafo tiene la ecuación asociada
En este cálculo, dado que y u6 = u5u–1, se obtiene
Durante el recorrido directo por el grafo, el software calcula las variables intermedias ui. Durante el recorrido inverso, comenzando desde el valor de la semilla , el cálculo en modo inverso obtiene los valores adjuntos para todas las variables. Por lo tanto, el modo inverso calcula el gradiente en un solo cálculo, lo que ahorra una gran cantidad de tiempo en comparación con el modo directo.
La siguiente figura muestra el cálculo del gradiente en el modo inverso para la función
De nuevo, el cálculo toma x1 = 2, x2 = 1/2. El cálculo en modo inverso depende de los valores de ui que se obtienen durante el cálculo de la función en el grafo computacional original. En la parte derecha de la figura, los valores calculados de las variables adjuntas aparecen junto a los nombres de las variables adjuntas usando las fórmulas de la parte izquierda de la figura.

Los valores del gradiente final aparecen como y .
Para obtener más detalles, consulte Baydin, Pearlmutter, Radul y Siskind [1] o el artículo de Wikipedia sobre la diferenciación automática [2].
Referencias
[1] Baydin, A. G., B. A. Pearlmutter, A. A. Radul, and J. M. Siskind. "Automatic Differentiation in Machine Learning: a Survey." The Journal of Machine Learning Research, 18(153), 2018, pp. 1–43. Available at https://arxiv.org/abs/1502.05767.
[2] Automatic differentiation. Wikipedia. Available at https://en.wikipedia.org/wiki/Automatic_differentiation.
Consulte también
dlarray | dlgradient | dlfeval | dlnetwork | dljacobian | dldivergence | dllaplacian
Temas
- Custom Loss Functions
- Custom Training Loops
- Custom Training Loop Model Loss Functions
- Entrenar redes generativas antagónicas (GAN)
- Entrenar una red con un bucle de entrenamiento personalizado
- Specify Training Options in Custom Training Loop
- Train Network Using Model Function
- Initialize Learnable Parameters for Model Function
- List of Functions with dlarray Support