Esta página es para la versión anterior. La página correspondiente en inglés ha sido eliminada en la versión actual.
Diseñar redes neuronales de retroalimentación NARX para series de tiempo
Para ver ejemplos del uso de redes NARX aplicadas en forma de lazo abierto, lazo cerrado y predicción de pasos múltiples de lazo abierto/cerrado, consulte .
Nota
Para diseñar un modelo NARX, también puede utilizar System Identification Toolbox™. Se recomienda este flujo de trabajo por las siguientes ventajas:
Extiende modelos ARX lineales y modela comportamiento no lineal complejo mediante funciones no lineales flexibles como redes wavelet, algoritmos de machine learning y redes neuronales.
Incluye información detallada y física en el sistema eligiendo regresores adecuados y comenzando con un modelo lineal.
Hasta ahora, todas las redes dinámicas específicas que hemos comentado han sido redes enfocadas, con la dinámica solo en la capa de entrada, o redes prealimentadas. La red autorregresiva no lineal con entradas exógenas (NARX) es una red dinámica recurrente, con conexiones de retroalimentación que rodean varias capas de la red. El modelo NARX se basa en el modelo lineal ARX, que se suele utilizar en el modelado de series de tiempo.
La ecuación de definición del modelo NARX es
donde el siguiente valor de la señal de salida dependiente y(t) vuelve a tener los valores previos de la señal de salida y los valores previos de una señal de entrada independiente (exógena). Puede implementar el modelo NARX utilizando una red neuronal prealimentada para aproximar la función f. A continuación se muestra un diagrama de la red resultante, donde se utiliza una red prealimentada de dos capas para la aproximación. Esta implementación también permite un modelo ARX vectorial, donde tanto la entrada como la salida pueden ser multidimensionales.
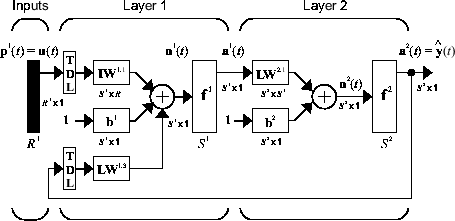
Existen muchas aplicaciones para la red NARX. Puede utilizarse como un predictor, para predecir el siguiente valor de la señal de entrada. También se puede utilizar para el filtrado no lineal, en el que la salida deseada es una versión sin ruido de la señal de entrada. El uso de la red NARX se muestra en otra aplicación importante, el modelado de sistemas dinámicos no lineales.
Antes de mostrar el entrenamiento de la red NARX, es necesario explicar una configuración importante que es útil en el entrenamiento. Puede considerar que la salida de la red NARX es una estimación de la salida de algún sistema dinámico no lineal que está intentando modelar. La salida se retroalimenta a la entrada de la red neuronal prealimentada como parte de la arquitectura estándar NARX, como se muestra en la figura de la izquierda a continuación. Puesto que la salida verdadera está disponible durante el entrenamiento de la red, puede crear una arquitectura paralela de serie (consulte [NaPa91]), en la que se utiliza la salida verdadera en lugar de retroalimentar la salida estimada, como se muestra en la figura de la derecha a continuación. Esto presenta dos ventajas. La primera es que la entrada a la red prealimentada es más precisa. La segunda es que la red resultante tiene una arquitectura puramente prealimentada y se puede utilizar la retropropagación estática para el entrenamiento.
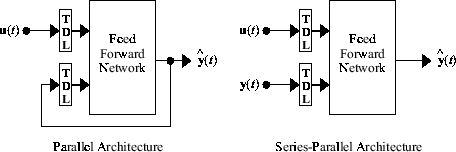
A continuación se muestra el uso de la arquitectura paralela de serie para entrenar una red NARX para modelar un sistema dinámico.
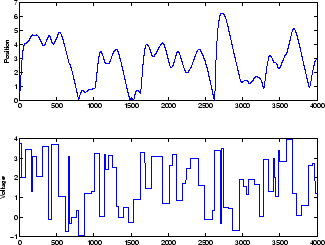
El ejemplo de la red NARX es el sistema de levitación magnética descrito que empieza en . En la gráfica inferior de la figura siguiente se muestra el voltaje aplicado al electroimán, y en la gráfica superior se muestra la posición del imán permanente. Los datos se han recopilado con un intervalo de muestreo de 0,01 segundos para formar dos series de tiempo.
El objetivo es desarrollar un modelo NARX para este sistema de levitación magnética.
Primero, cargue los datos de entrenamiento. Use líneas de retardo en pulsación con dos retardos tanto para la entrada como para la salida, por lo que el entrenamiento empieza con el tercer punto de datos. Hay dos entradas para la red paralela de serie, la secuencia u(t) y la secuencia y(t).
[u,y] = maglev_dataset;
Cree la red NARX paralela de serie con la función narxnet. Utilice 10 neuronas en la capa oculta y la función trainlm para el entrenamiento, y luego prepare los datos con preparets:
d1 = [1:2];
d2 = [1:2];
narx_net = narxnet(d1,d2,10);
narx_net.divideFcn = '';
narx_net.trainParam.min_grad = 1e-10;
[p,Pi,Ai,t] = preparets(narx_net,u,{},y);
(Observe que la secuencia y se considera una señal de retroalimentación, que es una entrada que también es una salida [objetivo]. Después, cuando se cierre el lazo, la salida apropiada se conectará a la entrada apropiada). Ahora todo está listo para entrenar la red.
narx_net = train(narx_net,p,t,Pi);

Ahora puede simular la red y representar los errores resultantes de la implementación paralela de serie.
yp = sim(narx_net,p,Pi); e = cell2mat(yp)-cell2mat(t); plot(e)

Verá que los errores son muy pequeños. Sin embargo, debido a la configuración paralela de serie, estos son solo errores para una predicción del siguiente paso. Una prueba más rigurosa sería reordenar la red en su forma paralela original (en lazo cerrado) y, luego, realizar una predicción iterada durante muchas unidades de tiempo. Ahora se muestra la operación en paralelo.
Hay una función de la toolbox (closeloop) que se utiliza para convertir redes NARX (y otras) desde la configuración paralela de serie (lazo abierto), que es útil para el entrenamiento, a la configuración paralela (lazo cerrado), que es útil para la predicción de pasos múltiples. En el comando siguiente se muestra cómo convertir la red que acaba de entrenar a la forma paralela:
narx_net_closed = closeloop(narx_net);
Para ver las diferencias entre las dos redes, puede usar el comando view:
view(narx_net)

view(narx_net_closed)
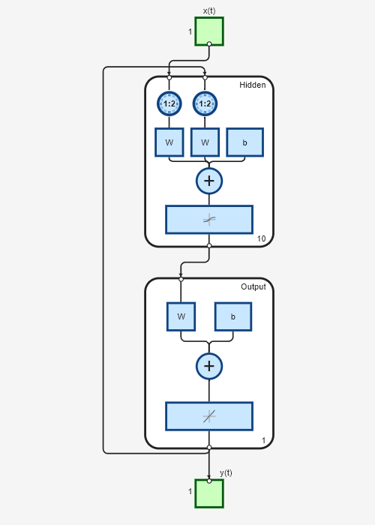
Todo el entrenamiento se realiza en lazo abierto (también denominado arquitectura paralela de serie), incluidos los pasos de validación y prueba. El flujo de trabajo habitual es crear completamente la red en lazo abierto, y solo cuando se ha entrenado (lo que incluye pasos de validación y prueba), se transforma a lazo cerrado para la predicción de pasos múltiples. Del mismo modo, los valores R de la interfaz gráfica se calculan en función de los resultados del entrenamiento en lazo abierto.
Ahora puede usar la configuración de lazo cerrado (paralela) para realizar una predicción iterada de 900 unidades de tiempo. En esta red, debe cargar las dos entradas iniciales y las dos salidas iniciales como condiciones iniciales. Puede utilizar la función preparets para preparar los datos. Usará la estructura de la red para determinar cómo dividir y desplazar los datos apropiadamente.
y1 = y(1700:2600);
u1 = u(1700:2600);
[p1,Pi1,Ai1,t1] = preparets(narx_net_closed,u1,{},y1);
yp1 = narx_net_closed(p1,Pi1,Ai1);
TS = size(t1,2);
plot(1:TS,cell2mat(t1),'b',1:TS,cell2mat(yp1),'r')
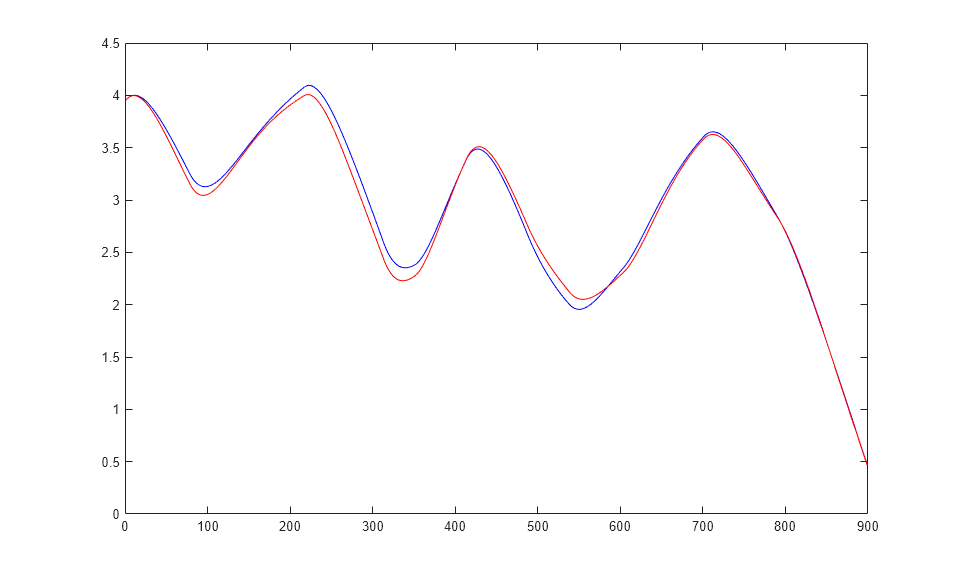
La figura ilustra la predicción iterada. La línea azul es la posición real del imán, y la línea roja es la posición predicha por la red neuronal NARX. Aunque la red está prediciendo 900 unidades de tiempo, la predicción es muy precisa.
Para que la respuesta en paralelo (predicción iterada) sea precisa, es importante que la red neuronal se entrene de tal manera que los errores en la configuración paralela de serie (predicción de un solo paso) sean muy pequeños.
Puede crear también una red NARX paralela (lazo cerrado) utilizando el comando narxnet con el cuarto argumento de entrada establecido en 'closed' y entrenar directamente esa red. Por lo general, el entrenamiento tarda más y el rendimiento resultante no es tan bueno como el obtenido con el entrenamiento paralelo de serie.
Cada vez que se entrena una red neuronal, puede dar como resultado una solución diferente debido a diferentes valores iniciales de pesos y sesgos, así como a diferentes divisiones de los datos en conjuntos de entrenamiento, validación y prueba. Como resultado, diferentes redes neuronales entrenadas para el mismo problema pueden dar diferentes salidas para la misma entrada. Para asegurarse de que se ha encontrado una red neuronal con una buena precisión, vuelva a entrenarla varias veces.
Existen varias técnicas para mejorar las soluciones iniciales si se desea una mayor precisión. Para obtener más información, consulte .
Múltiples variables externas
En el ejemplo de maglev se ha mostrado cómo modelar una serie de tiempo con un único valor de entrada externa a lo largo del tiempo. Pero la red NARX funcionará para problemas con múltiples elementos de entrada externos y predecirá series con múltiples elementos. En estos casos, la entrada y el objetivo consisten en arreglos de celdas de fila que representan el tiempo, pero cada elemento de la celda es un vector de N por 1 para los N elementos de la señal de entrada u objetivo.
Por ejemplo, aquí hay un conjunto de datos que consiste en variables externas de 2 elementos que predicen una serie de 1 elemento.
[X,T] = ph_dataset;
Las entradas externas X se formatean como un arreglo de celdas de fila de vectores de 2 elementos, donde cada vector representa el flujo de solución ácida y básica. Los objetivos representan el pH resultante de la solución con el tiempo.
Puede volver a establecer el formato de sus propios datos de series de varios elementos de la forma de matriz al formato de serie de tiempo de red neuronal con la función con2seq.
El proceso de entrenamiento de una red continúa tal como se hizo anteriormente para el problema de maglev.
net = narxnet(10);
[x,xi,ai,t] = preparets(net,X,{},T);
net = train(net,x,t,xi,ai);
y = net(x,xi,ai);
e = gsubtract(t,y); Para ver ejemplos del uso de redes NARX aplicadas en forma de lazo abierto, lazo cerrado y predicción de pasos múltiples de lazo abierto/cerrado, consulte .