Modelos de regresión de procesos gaussianos
Los modelos de regresión de procesos gaussianos (GPR) son modelos probabilísticos no paramétricos basados en kernels. Puede entrenar un modelo GPR utilizando la función fitrgp.
Considere el conjunto de entrenamiento , donde e , extraído de una distribución desconocida. Un modelo GPR resuelve la cuestión de predecir el valor de una variable de respuesta , dado el nuevo vector de entrada y los datos de entrenamiento. Un modelo de regresión lineal tiene el formato
donde . La varianza del error σ2 y los coeficientes β se estiman a partir de los datos. Un modelo GPR explica la respuesta introduciendo variables latentes, , de un proceso gaussiano (GP), y funciones de base explícitas, h. La función de covarianza de las variables latentes captura la suavidad de la respuesta y las funciones de base proyectan las entradas en un espacio de características de p dimensiones.
Un GP es un conjunto de variables aleatorias, de modo que cualquier número finito de ellas tiene una distribución gaussiana conjunta. Si es un GP, dadas n observaciones , la distribución conjunta de las variables aleatorias es gaussiana. Un GP está definido por su función de media y su función de covarianza . Es decir, si es un proceso gaussiano, entonces y
Ahora considere el siguiente modelo.
donde , es decir, f(x) procede de un GP de media cero con función de covarianza, . h(x) son un conjunto de funciones de base que transforman el vector de características original x en Rd en un nuevo vector de características h(x) en p. β es un vector de p por 1 de coeficientes de funciones de base. Este modelo representa un modelo GPR. Una instancia de respuesta y puede modelarse como
Por tanto, un modelo GPR es un modelo probabilístico. Hay una variable latente f(xi) introducida para cada observación , lo que hace que el modelo GPR sea no paramétrico. En el formato vector, este modelo es equivalente a
donde
La distribución conjunta de las variables latentes del modelo GPR es la siguiente:
cerca de un modelo de regresión lineal, donde tiene el siguiente aspecto:
Normalmente, la función de covarianza está parametrizada por un conjunto de parámetros o hiperparámetros de kernel, . A menudo, se escribe como para indicar de manera explícita la dependencia de .
fitrgp estima los coeficientes de la función de base, , la varianza de ruido, , y los hiperparámetros, , de la función de kernel a partir de los datos mientras entrena el modelo GPR. Puede especificar la función de base, la función de kernel (covarianza) y los valores iniciales de los parámetros.
Dado que un modelo GPR es probabilístico, es posible calcular los intervalos de predicción usando el modelo entrenado (consulte predict y resubPredict).
También puede calcular el error de regresión usando el modelo GPR entrenado (consulte loss y resubLoss).
Comparar intervalos de predicción de modelos GPR
Este ejemplo ajusta modelos GPR a un conjunto de datos sin ruido y a un conjunto de datos con ruido. El ejemplo compara las respuestas pronosticadas y los intervalos de predicción de los dos modelos GPR ajustados.
Genere dos conjuntos de datos de observación a partir de la función .
rng('default') % For reproducibility x_observed = linspace(0,10,21)'; y_observed1 = x_observed.*sin(x_observed); y_observed2 = y_observed1 + 0.5*randn(size(x_observed));
Los valores de y_observed1 no tienen ruido y los valores de y_observed2 incluyen algo de ruido aleatorio.
Ajuste los modelos GPR a los conjuntos de datos observados.
gprMdl1 = fitrgp(x_observed,y_observed1); gprMdl2 = fitrgp(x_observed,y_observed2);
Calcule las respuestas pronosticadas y los intervalos de predicción del 95% usando los modelos ajustados.
x = linspace(0,10)'; [ypred1,~,yint1] = predict(gprMdl1,x); [ypred2,~,yint2] = predict(gprMdl2,x);
Cambie el tamaño de una figura para que muestre dos gráficas en una figura.
fig = figure; fig.Position(3) = fig.Position(3)*2;
Cree un diseño de gráfica en mosaico de 1 por 2.
tiledlayout(1,2,'TileSpacing','compact')
Para cada mosaico, represente una gráfica de dispersión de los puntos de datos observados y una gráfica de función de . Después, añada una gráfica de respuestas pronosticadas de GP y un parche de intervalos de predicción.
nexttile hold on scatter(x_observed,y_observed1,'r') % Observed data points fplot(@(x) x.*sin(x),[0,10],'--r') % Function plot of x*sin(x) plot(x,ypred1,'g') % GPR predictions patch([x;flipud(x)],[yint1(:,1);flipud(yint1(:,2))],'k','FaceAlpha',0.1); % Prediction intervals hold off title('GPR Fit of Noise-Free Observations') legend({'Noise-free observations','g(x) = x*sin(x)','GPR predictions','95% prediction intervals'},'Location','best') nexttile hold on scatter(x_observed,y_observed2,'xr') % Observed data points fplot(@(x) x.*sin(x),[0,10],'--r') % Function plot of x*sin(x) plot(x,ypred2,'g') % GPR predictions patch([x;flipud(x)],[yint2(:,1);flipud(yint2(:,2))],'k','FaceAlpha',0.1); % Prediction intervals hold off title('GPR Fit of Noisy Observations') legend({'Noisy observations','g(x) = x*sin(x)','GPR predictions','95% prediction intervals'},'Location','best')
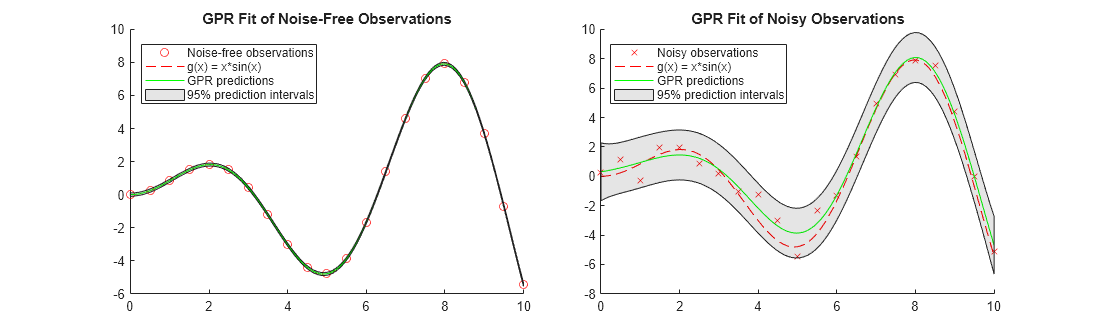
Cuando las observaciones no tienen ruido, las respuestas pronosticadas del ajuste de la GPR coinciden con las observaciones. La desviación estándar de la respuesta pronosticada es casi cero. Por consiguiente, los intervalos de predicción son muy estrechos. Cuando las observaciones incluyen ruido, las respuestas pronosticadas no coinciden con las observaciones y los intervalos de predicción se vuelven amplios.
Referencias
[1] Rasmussen, C. E. and C. K. I. Williams. Gaussian Processes for Machine Learning. MIT Press. Cambridge, Massachusetts, 2006.
Consulte también
fitrgp | RegressionGP | predict