detect
(Not recommended) Detect objects using Fast R-CNN object detector
The detect function and Fast R-CNN object detectors are not
recommended. Use a different type of object detector instead. For more information, see Version History.
Syntax
Description
bboxes = detect(detector,I)I, using
a Fast R-CNN (regions with convolutional neural networks) object detector. The locations
of objects detected are returned as a set of bounding boxes.
When using this function, use of a CUDA® enabled NVIDIA® GPU is highly recommended. The GPU reduces computation time significantly. Usage of the GPU requires Parallel Computing Toolbox™. For information about the supported compute capabilities, see GPU Computing Requirements (Parallel Computing Toolbox).
[___,
also returns a categorical array of labels assigned to the bounding boxes, using either of
the preceding syntaxes. The labels used for object classes are defined during training
using the labels] = detect(detector,I)trainFastRCNNObjectDetector
function.
[___] = detect(___,
detects objects within the rectangular search region specified by
roi)roi.
detectionResults = detect(detector,ds)read function
of the input datastore.
[___] = detect(___,
specifies options using one or more name-value arguments in addition to any combination of
arguments from previous syntaxes.Name=Value)
Examples
Detect vehicles within an image by using a Faster R-CNN object detector.
Load a Faster R-CNN object detector pretrained to detect vehicles.
data = load('fasterRCNNVehicleTrainingData.mat', 'detector'); detector = data.detector;
Read in a test image.
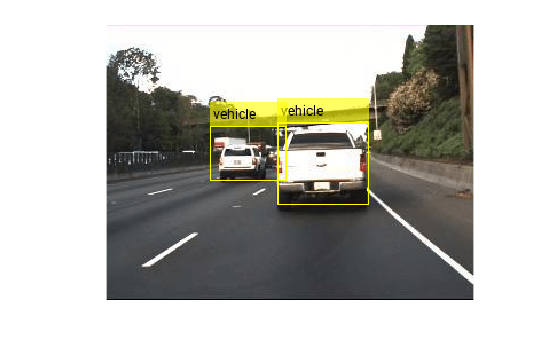
I = imread('highway.png');
imshow(I)
Run the detector on the image and inspect the results. The labels come from the ClassNames property of the detector.
[bboxes,scores,labels] = detect(detector,I)
bboxes = 2×4
150 86 80 72
91 89 67 48
scores = 2×1 single column vector
1.0000
0.9001
labels = 2×1 categorical
vehicle
vehicle
The detector has high confidence in the detections. Annotate the image with the bounding boxes for the detections and the corresponding detection scores.
detectedI = insertObjectAnnotation(I,'Rectangle',bboxes,cellstr(labels));
figure
imshow(detectedI)