R =
Resultados de
If you use tables extensively to perform data analysis, you may at some point have wanted to add new functionalities suited to your specific applications. One straightforward idea is to create a new class that subclasses the built-in table class. You would then benefit from all inherited existing methods.
One workaround is to create a new class that wraps a table as a Property, and re-implement all the methods that you need and are already defined for table. The is not too difficult, except for the subsref method, for which I’ll provide the code below.
Class definition
Defining a wrapper of the table class is quite straightforward. In this example, I call the class “Report” because that is what I intend to use the class for, to compute and store reports. The constructor just takes a table as input:
classdef Rapport
methods
function obj = Report(t)
if isa(t, 'Report')
obj = t;
else
obj.t_ = t;
end
end
end
properties (GetAccess = private, SetAccess = private)
t_ table = table();
end
end
I designed the constructor so that it converts a table into a Report object, but also so that if we accidentally provide it with a Report object instead of a table, it will not generate an error.
Reproducing the behaviour of the table class
Implementing the existing methods of the table class for the Report class if pretty easy in most cases.
I made use of a method called “table” in order to be able to get the data back in table format instead of a Report, instead of accessing the property t_ of the object. That method can also be useful whenever you wish to use the methods or functions already existing for tables (such as writetable, rowfun, groupsummary…).
classdef Rapport
...
methods
function t = table(obj)
t = obj.t_;
end
function r = eq(obj1,obj2)
r = isequaln(table(obj1), table(obj2));
end
function ind = size(obj, varargin)
ind = size(table(obj), varargin{:});
end
function ind = height(obj, varargin)
ind = height(table(obj), varargin{:});
end
function ind = width(obj, varargin)
ind = width(table(obj), varargin{:});
end
function ind = end(A,k,n)
% ind = end(A.t_,k,n);
sz = size(table(A));
if k < n
ind = sz(k);
else
ind = prod(sz(k:end));
end
end
end
end
In the case of horzcat (same principle for vertcat), it is just a matter of converting back and forth between the table and Report classes:
classdef Rapport
...
methods
function r = horzcat(obj1,varargin)
listT = cell(1, nargin);
listT{1} = table(obj1);
for k = 1:numel(varargin)
kth = varargin{k};
if isa(kth, 'Report')
listT{k+1} = table(kth);
elseif isa(kth, 'table')
listT{k+1} = kth;
else
error('Input must be a table or a Report');
end
end
res = horzcat(listT{:});
r = Report(res);
end
end
end
Adding a new method
The plus operator already exists for the table class and works when the table contains all numeric values. It sums columns as long as the tables have the same length.
Something I think would be nice would be to be able to write t1 + t2, and that would perform an outerjoin operation between the tables and any sizes having similar indexing columns.
That would be so concise, and that's what we’re going to implement for the Report class as an example. That is called “plus operator overloading”. Of course, you could imagine that the “+” operator is used to compute something else, for example adding columns together with regard to the keys index. That depends on your needs.
Here’s a unittest example:
classdef ReportTest < matlab.unittest.TestCase
methods (Test)
function testPlusOperatorOverload(testCase)
t1 = array2table( ...
{ 'Smith', 'Male' ...
; 'JACKSON', 'Male' ...
; 'Williams', 'Female' ...
} , 'VariableNames', {'LastName' 'Gender'} ...
);
t2 = array2table( ...
{ 'Smith', 13 ...
; 'Williams', 6 ...
; 'JACKSON', 4 ...
}, 'VariableNames', {'LastName' 'Age'} ...
);
r1 = Report(t1);
r2 = Report(t2);
tRes = r1 + r2;
tExpected = Report( array2table( ...
{ 'JACKSON' , 'Male', 4 ...
; 'Smith' , 'Male', 13 ...
; 'Williams', 'Female', 6 ...
} , 'VariableNames', {'LastName' 'Gender' 'Age'} ...
) );
testCase.verifyEqual(tRes, tExpected);
end
end
end
And here’s how I’d implement the plus operator in the Report class definition, so that it also works if I add a table and a Report:
classdef Rapport
...
methods
function r = plus(obj1,obj2)
table1 = table(obj1);
table2 = table(obj2);
result = outerjoin(table1, table2 ...
, 'Type', 'full', 'MergeKeys', true);
r = reportingits.dom.Rapport(result);
end
end
end
The case of the subsref method
If we wish to access the elements of an instance the same way we would with regular tables, whether with parentheses, curly braces or directly with the name of the column, we need to implement the subsref and subsasgn methods. The second one, subsasgn is pretty easy, but subsref is a bit tricky, because we need to detect whether we’re directing towards existing methods or not.
Here’s the code:
classdef Rapport
...
methods
function A = subsasgn(A,S,B)
A.t_ = subsasgn(A.t_,S,B);
end
function B = subsref(A,S)
isTableMethod = @(m) ismember(m, methods('table'));
isReportMethod = @(m) ismember(m, methods('Report'));
switch true
case strcmp(S(1).type, '.') && isReportMethod(S(1).subs)
methodName = S(1).subs;
B = A.(methodName)(S(2).subs{:});
if numel(S) > 2
B = subsref(B, S(3:end));
end
case strcmp(S(1).type, '.') && isTableMethod (S(1).subs)
methodName = S(1).subs;
if ~isReportMethod(methodName)
error('The method "%s" needs to be implemented!', methodName)
end
otherwise
B = subsref(table(A),S(1));
if istable(B)
B = Report(B);
end
if numel(S) > 1
B = subsref(B, S(2:end));
end
end
end
end
end
Conclusion
I believe that the table class is Sealed because is case new methods are introduced in MATLAB in the future, the subclass might not be compatible if we created any or generate unexpected complexity.
The table class is a really powerful feature.
I hope this example has shown you how it is possible to extend the use of tables by adding new functionalities and maybe given you some ideas to simplify some usages. I’ve only happened to find it useful in very restricted cases, but was still happy to be able to do so.
In case you need to add other methods of the table class, you can see the list simply by calling methods(’table’).
Feel free to share your thoughts or any questions you might have! Maybe you’ll decide that doing so is a bad idea in the end and opt for another solution.
The challenge:
You are given a string of lowercase letters 'a' to 'z'.
Each character represents a base-26 digit:
- 'a' = 0
1. Understand the Base-26 Conversion Process:
Let the input be s = 'aloha'.
Convert each character to a digit:
digits = double(s) - double('a');
This works because:
double('a') = 97
double('b') = 98
So:
double('a') - 97 = 0
double('l') - 97 = 11
double('o') - 97 = 14
double('h') - 97 = 7
double('a') - 97 = 0
Now you have:
[0 11 14 7 0]
2. Interpret as Base-26:
For a number with n digits:
d1 d2 d3 ... dn
Value = d1*26^(n-1) + d2*26^(n-2) + ... + dn*26^0
So for 'aloha' (5 chars):
0*26^4 + 11*26^3 + 14*26^2 + 7*26^1 + 0*26^0
MATLAB can compute this automatically.
3. Avoid loops — Use MATLAB vectorization:
You can compute the weighted sum using dot
digits = double(s) - 'a';
powers = 26.^(length(s)-1:-1:0);
result = dot(digits, powers);
This is clean, short, and vectorized.
4.Test with the examples:
char2num26('funfunfun')
→ 1208856210289
char2num26('matlab')
→ 142917893
char2num26('nasa')
→ 228956
To track the current leader after each match, you can use cumulative scores. First, calculate the cumulative sum for each player across the matches. Then, after eaayer with the highest score.
Hint: Use cumsum(S, 1) to get cumulative scores along the rows (matches). Loop through each row to keep track of the leader. If multiple players tie, pick the lowest index.
Example:
If S = [5 3 4; 2 6 2; 3 5 7], after match 3, the cumulative scores are [10 14 13]. Player 2 leads with 14 hilbs.
This method keeps your code clean and avoids repeatedly summing rows.
Congratulations to all the Cool Coders who have completed the problem set. I hope you weren't too cool to enjoy the silliness I put into the problems.
If you've solved the whole problem set, don't forget to help out your teammates with suggestions, tips, tricks, etc. But also, just for fun, I'm curious to see which of my many in-jokes and nerdy references you noticed. Many of the problems were inspired by things in the real world, then ported over into the chaotic fantasy world of Nedland.
I guess I'll start with the obvious real-world reference: @Ned Gulley (I make no comment about his role as insane despot in any universe, real or otherwise.)
Extracting the digits of a number will be useful to solve many Cody problems.
Instead of iteratively dividing by 10 and taking the remainder, the digits of a number can be easily extracted using String operations.
%Extract the digits of N
N = 1234;
d = num2str(N)-'0';
d =
1 2 3 4
Instead of looping with if-statements, use logical indexing:
A(A < 0) = 0;
One line, no loops, full clarity.
Whenever a problem repeats in cycles (like indexing or angles), mod() keeps your logic clean:
idx = mod(i-1, n) + 1;
No if-else chaos!
The toughest problem in the Cody Contest 2025 is Clueless - Lord Ned in the Game Room. Thank you Matt Tearle for such as wonderful problem. We can approach this clueless(!) tough problem systematically.
Initialize knowledge Matrix
Based on the hints provided in the problem description, we can initialize a knowledge matrix of size n*3 by m+1. The rows of the knowledge matrix represent the different cards and the columns represent the players. In the knowledge matrix, the first n rows represent category 1 cards, the next n rows, category 2 and the next category 3. We can initialize this matrix with zeros. On the go, once we know that a player holds the card, we can make that entry as 1 and if a player doesn't have the card, we can make that entry as -1.
yourcards processing
These are cards received by us.
- In the knowledge matrix, mark the entries as 1 for the cards received. These entries will be the some elements along the column pnum of the knowledge matrix.
- Mark all other entries along the column pnum as -1, as we don't receive other cards.
- Mark all other entries along the rows corresponding to the received cards as -1, as other players cannot receive the cards that are with us.
commoncards processing
These are the common cards kept open.
- In the knowledge matrix, mark the entries as 1 for the common cards. These entries will be some elements along the column (m+1) of the knowledge matrix.
- Mark all other entries along the column (m+1) as -1, as other cards are not common.
- Mark all other entries along the rows corresponding to the common cards as -1, as other players cannot receive the cards that are common.
Result -1 processing
In the turns input matrix, the result (5th column) value -1 means, the corresponding player doesn't have the 3 cards asked.
- Find all the rows with result as -1.
- For those corresponding players (1st element in each row of turns matrix), mark -1 entries in the knowledge matrix for those 3 absent cards.
pnum turns processing
These are our turns, so we get definite answers for the asked cards. Make sure to traverse only the rows corresponding to our turn.
- The results with -1 are already processed in the previous step.
- The results other than -1 means, that particular card is present with the asked player. So mark the entry as 1 for the corresponding player in the knowledge matrix.
- Mark all other entries along the row corresponding to step 2 as -1, as other players cannot receive this card.
Result 0 processing
So far, in the yourcards processing, commoncards processing, result -1 processing and pnum turns processing, we had very straightforward definite knowledge about the presence/absence of the card with a player. This step onwards, the tricky part of the problem begins.
result 0 means, any one (or more) of the asked cards are present with the asked player. We don't know exactly which card.
- For the asked player, if we have a definite no answer (-1 value in the knowledge matrix) for any two of the three asked cards, then we are sure about the card that is present with the player.
- Mark the entry as 1 for the definitely known card for the corresponding player in the knowledge matrix.
- Mark all other entries along the row corresponding to step 2 as -1, as other players cannot receive this card.
Cards per Player processing
Based on the number of cards present in the yourcards, we know the ncards, the number of cards per player.
Check along each column of the knowledge matrix, that is for each player.
- If the number of ones (definitely present cards) is equal to ncards, we can make all other entries along the column as -1, as this player cannot have any other card.
- If the sum of number of ones (definitely present cards) and the number of zeros (unknown cards) is equal to ncards, we can (i) mark the zero entries as one, as the unknown cards have become definitely present cards, (ii) mark all other entries along the column as -1, as other players cannot have any other card.
Category-wise cards checking
For each category, we must get a definite card to be present in the envelope.
- In each category (For every group of n rows of knowledge matrix), check for a row with all -1s. That is a card which is definitely not present with any of the players. Then this card will surely be present in the envelope. Add it to the output.
- If we could not find an all -1 row, then in that category, check each row for a 1 to be present. Note down the rows which doesn't have a 1. Those cards' players are still unknown. If we have only one such row (unknown card), then it must be in the envelope, as from each category one card is present in the envelope. Add it to the output.
- For the card identified in Step 2, mark all the entries along that row in the knowledge matrix as -1, as this card doesn't belong to any player.
Looping Over
In our so far steps, we could note that, the knowledge matrix got updated even after "Result 0 processing" step. This updation in the knowledge matrix may help the "Result 0 processing" step, if we perform it again. So, we can loop over the steps, "Result 0 processing", "Cards per Player processing" and "Category-wise cards checking" again. This ensures that, we will get the desired number of envelop cards (three in our case) as output.
Instead of growing arrays inside a loop, preallocate with zeros(), ones(), or nan(). It avoids memory fragmentation and speeds up Cody solutions.
A = zeros(1,1000);
Cody often hides subtle hints in example outputs — like data shape, rounding, or format. Matching those exactly saves you a lot of debugging time.
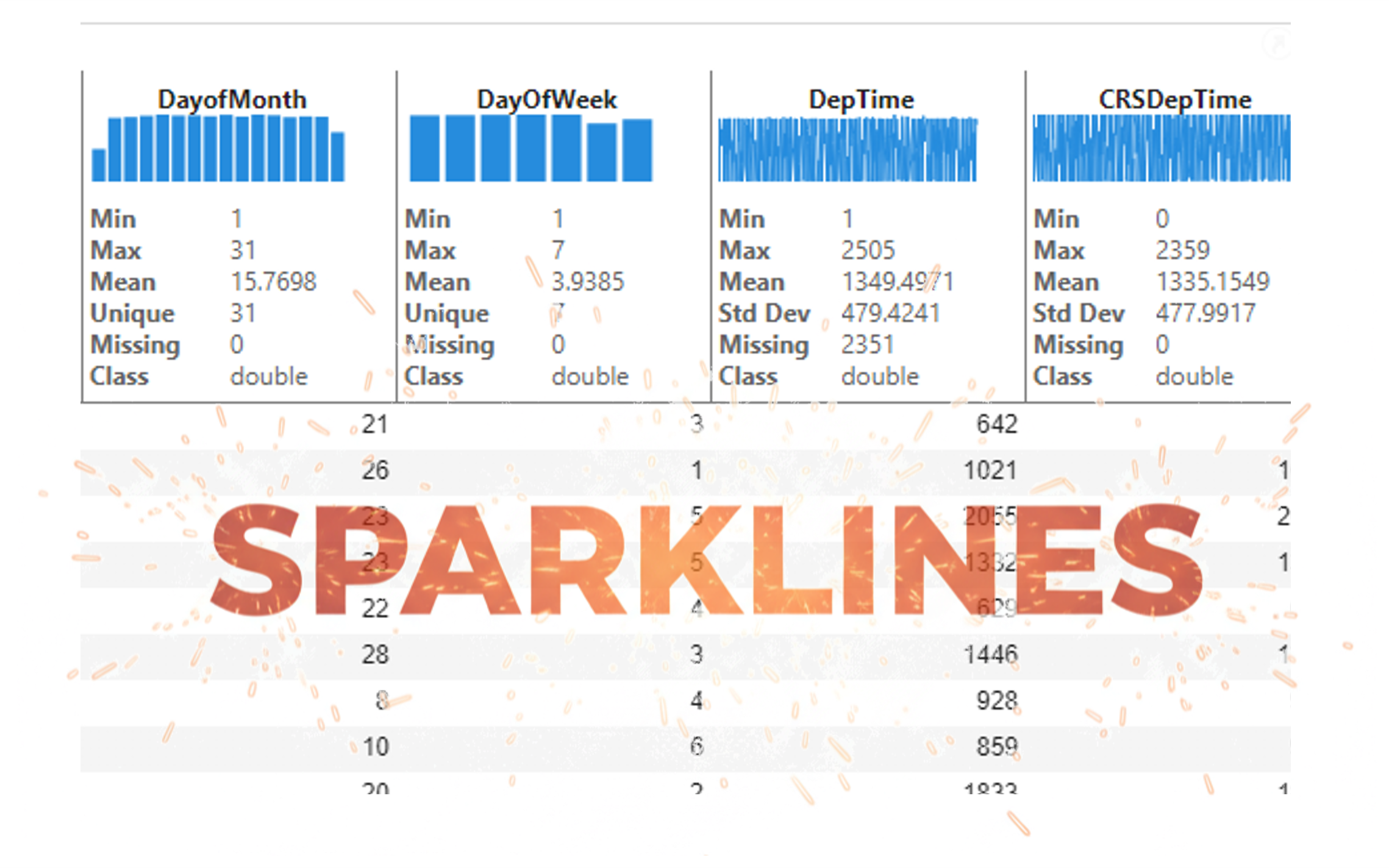
It’s exciting to dive into a new dataset full of unfamiliar variables but it can also be overwhelming if you’re not sure where to start. Recently, I discovered some new interactive features in MATLAB live scripts that make it much easier to get an overview of your data. With just a few clicks, you can display sparklines and summary statistics using table variables, sort and filter variables, and even have MATLAB generate the corresponding code for reproducibility.
The Graphics and App Building blog published an article that walks through these features showing how to explore, clean, and analyze data—all without writing any code.
If you’re interested in streamlining your exploratory data analysis or want to see what’s new in live scripts, you might find it helpful:
If you’ve tried these features or have your own tips for quick data exploration in MATLAB, I’d love to hear your thoughts!
isequal() is your best friend for Cody! It compares arrays perfectly without rounding errors — much safer than == for matrix outputs.
When Cody hides test cases, test your function with random small inputs first. If it works for many edge cases, it will almost always pass the grader.
I realized that using vectorized logic instead of nested loops makes Cody problems run much faster and cleaner. Functions like any(), all(), and logical indexing can replace multiple for-loops easily !
Hi cool guys,
I hope you are coding so cool!
FYI, in Problem 61065. Convert Hexavigesimal to Decimal in Cody Contest 2025 there's a small issue with the text:
[ ... For example, the text ‘aloha’ would correspond to a vector of values [0 11 14 7 0], thus representing the base-26 value 202982 = 11*263 + 14*262 + 7*26 ...]
The bold section should be:
202982 = 11*26^3 + 14*26^2 + 7*26
Hey Cool Coders! 😎
Let’s get to know each other. Drop a quick intro below and meet your teammates! This is your chance to meet teammates, find coding buddies, and build connections that make the contest more fun and rewarding!
You can share:
- Your name or nickname
- Where you’re from
- Your favorite coding topic or language
- What you’re most excited about in the contest
Let’s make Team Cool Coders an awesome community—jump in and say hi! 🚀
Welcome to the Cody Contest 2025 and the Cool Coders team channel! 🎉
You stay calm under pressure. No panic, no chaos—just smooth problem-solving. This is your space to connect with like-minded coders, share insights, and help your team win. To make sure everyone has a great experience, please keep these tips in mind:
- Follow the Community Guidelines: Take a moment to review our community standards. Posts that don’t follow these guidelines may be flagged by moderators or community members.
- Ask Questions About Cody Problems: When asking for help, show your work! Include your code, error messages, and any details needed to reproduce your results. This helps others provide useful, targeted answers.
- Share Tips & Tricks: Knowledge sharing is key to success. When posting tips or solutions, explain how and why your approach works so others can learn your problem-solving methods.
- Provide Feedback: We value your feedback! Use this channel to report issues or share creative ideas to make the contest even better.
Have fun and enjoy the challenge! We hope you’ll learn new MATLAB skills, make great connections, and win amazing prizes! 🚀
I just learned you can access MATLAB Online from the following shortcut in your web browser: https://matlab.new
Thanks @Yann Debray
From his recent blog post: pip & uv in MATLAB Online » Artificial Intelligence - MATLAB & Simulink
What if you had no isprime utility to rely on in MATLAB? How would you identify a number as prime? An easy answer might be something tricky, like that in simpleIsPrime0.
simpleIsPrime0 = @(N) ismember(N,primes(N));
But I’ll also disallow the use of primes here, as it does not really test to see if a number is prime. As well, it would seem horribly inefficient, generating a possibly huge list of primes, merely to learn something about the last member of the list.
Looking for a more serious test for primality, I’ve already shown how to lighten the load by a bit using roughness, to sometimes identify numbers as composite and therefore not prime.
https://www.mathworks.com/matlabcentral/discussions/tips/879745-primes-and-rough-numbers-basic-ideas
But to actually learn if some number is prime, we must do a little more. Yes, this is a common homework problem assigned to students, something we have seen many times on Answers. It can be approached in many ways too, so it is worth looking at the problem in some depth.
The definition of a prime number is a natural number greater than 1, which has only two factors, thus 1 and itself. That makes a simple test for primality of the number N easy. We just try dividing the number by every integer greater than 1, and not exceeding N-1. If any of those trial divides leaves a zero remainder, then N cannot be prime. And of course we can use mod or rem instead of an explicit divide, so we need not worry about floating point trash, as long as the numbers being tested are not too large.
simpleIsPrime1 = @(N) all(mod(N,2:N-1) ~= 0);
Of course, simpleIsPrime1 is not a good code, in the sense that it fails to check if N is an integer, or if N is less than or equal to 1. It is not vectorized, and it has no documentation at all. But it does the job well enough for one simple line of code. There is some virtue in simplicity after all, and it is certainly easy to read. But sometimes, I wish a function handle could include some help comments too! A feature request might be in the offing.
simpleIsPrime1(9931)
simpleIsPrime1(9932)
simpleIsPrime1 works quite nicely, and seems pretty fast. What could be wrong? At some point, the student is given a more difficult problem, to identify if a significantly larger integer is prime. simpleIsPrime1 will then cause a computer to grind to a distressing halt if given a sufficiently large number to test. Or it might even error out, when too large a vector of numbers was generated to test against. For example, I don't think you want to test a number of the order of 2^64 using simpleIsPrime1, as performing on the order of 2^64 divides will be highly time consuming.
uint64(2)^63-25
Is it prime? I’ve not tested it to learn if it is, and simpleIsPrime1 is not the tool to perform that test anyway.
A student might realize the largest possible integer factors of some number N are the numbers N/2 and N itself. But, if N/2 is a factor, then so is 2, and some thought would suggest it is sufficient to test only for factors that do not exceed sqrt(N). This is because if a is a divisor of N, then so is b=N/a. If one of them is larger than sqrt(N), then the other must be smaller. That could lead us to an improved scheme in simpleIsPrime2.
simpleIsPrime2 = @(N) all(mod(N,2:sqrt(N)));
For an integer of the size 2^64, now you only need to perform roughly 2^32 trial divides. Maybe we might consider the subtle improvement found in simpleIsPrime3, which avoids trial divides by the even integers greater than 2.
simpleIsPrime3 = @(N) (N == 2) || (mod(N,2) && all(mod(N,3:2:sqrt(N))));
simpleIsPrime3 needs only an approximate maximum of 2^31 trial divides even for numbers as large as uint64 can represent. While that is large, it is still generally doable on the computers we have today, even if it might be slow.
Sadly, my goals are higher than even the rather lofty limit given by UINT64 numbers. The problem of course is that a trial divide scheme, despite being 100% accurate in its assessment of primality, is a time hog. Even an O(sqrt(N)) scheme is far too slow for numbers with thousands or millions of digits. And even for a number as “small” as 1e100, a direct set of trial divides by all primes less than sqrt(1e100) would still be practically impossible, as there are roughly n/log(n) primes that do not exceed n. For an integer on the order of 1e50,
1e50/log(1e50)
It is practically impossible to perform that many divides on any computer we can make today. Can we do better? Is there some more efficient test for primality? For example, we could write a simple sieve of Eratosthenes to check each prime found not exceeding sqrt(N).
function [TF,SmallPrime] = simpleIsPrime4(N)
% simpleIsPrime3 - Sieve of Eratosthenes to identify if N is prime
% [TF,SmallPrime] = simpleIsPrime3(N)
%
% Returns true if N is prime, as well as the smallest prime factor
% of N when N is composite. If N is prime, then SmallPrime will be N.
Nroot = ceil(sqrt(N)); % ceil caters for floating point issues with the sqrt
TF = true;
SieveList = true(1,Nroot+1); SieveList(1) = false;
SmallPrime = 2;
while TF
% Find the "next" true element in SieveList
while (SmallPrime <= Nroot+1) && ~SieveList(SmallPrime)
SmallPrime = SmallPrime + 1;
end
% When we drop out of this loop, we have found the next
% small prime to check to see if it divides N, OR, we
% have gone past sqrt(N)
if SmallPrime > Nroot
% this is the case where we have now looked at all
% primes not exceeding sqrt(N), and have found none
% that divide N. This is where we will drop out to
% identify N as prime. TF is already true, so we need
% not set TF.
SmallPrime = N;
return
else
if mod(N,SmallPrime) == 0
% smallPrime does divide N, so we are done
TF = false;
return
end
% update SieveList
SieveList(SmallPrime:SmallPrime:Nroot) = false;
end
end
end
simpleIsPrime4 does indeed work reasonably well, though it is sometimes a little slower than is simpleIsPrime3, and everything is hugely faster than simpleIsPrime1.
timeit(@() simpleIsPrime1(111111111))
timeit(@() simpleIsPrime2(111111111))
timeit(@() simpleIsPrime3(111111111))
timeit(@() simpleIsPrime4(111111111))
All of those times will slow to a crawl for much larger numbers of course. And while I might find a way to subtly improve upon these codes, any improvement will be marginal in the end if I try to use any such direct approach to primality. We must look in a different direction completely to find serious gains.
At this point, I want to distinguish between two distinct classes of tests for primality of some large number. One class of test is what I might call an absolute or infallible test, one that is perfectly reliable. These are tests where if X is identified as prime/composite then we can trust the result absolutely. The tests I showed in the form of simpleIsPrime1, simpleIsPrime2, simpleIsPrime3 and aimpleIsprime4, were all 100% accurate, thus they fall into the class of infallible tests.
The second general class of test for primality is what I will call an evidentiary test. Such a test provides evidence, possibly quite strong evidence, that the given number is prime, but in some cases, it might be mistaken. I've already offered a basic example of a weak evidentiary test for primality in the form of roughness. All primes are maximally rough. And therefore, if you can identify X as being rough to some extent, this provides evidence that X is also prime, and the depth of the roughness test influences the strength of the evidence for primality. While this is generally a fairly weak test, it is a test nevertheless, and a good exclusionary test, a good way to avoid more sophisticated but time consuming tests.
These evidentiary tests all have the property that if they do identify X as being composite, then they are always correct. In the context of roughness, if X is not sufficiently rough, then X is also not prime. On the other side of the coin, if you can show X is at least (sqrt(X)+1)-rough, then it is positively prime. (I say this to suggest that some evidentiary tests for primality can be turned into truth telling tests, but that may take more effort than you can afford.) The problem is of course that is literally impossible to verify that degree of roughness for numbers with many thousands of digits.
In my next post, I'll look at the Fermat test for primality, based on Fermat's little theorem.
I saw an interesting problem on a reddit math forum today. The question was to find a number (x) as close as possible to r=3.6, but the requirement is that both x and 1/x be representable in a finite number of decimal places.
The problem of course is that 3.6 = 18/5. And the problem with 18/5 has an inverse 5/18, which will not have a finite representation in decimal form.
In order for a number and its inverse to both be representable in a finite number of decimal places (using base 10) we must have it be of the form 2^p*5^q, where p and q are integer, but may be either positive or negative. If that is not clear to you intuitively, suppose we have a form
2^p*5^-q
where p and q are both positive. All you need do is multiply that number by 10^q. All this does is shift the decimal point since you are just myltiplying by powers of 10. But now the result is
2^(p+q)
and that is clearly an integer, so the original number could be represented using a finite number of digits as a decimal. The same general idea would apply if p was negative, or if both of them were negative exponents.
Now, to return to the problem at hand... We can obviously adjust the number r to be 20/5 = 4, or 16/5 = 3.2. In both cases, since the fraction is now of the desired form, we are happy. But neither of them is really close to 3.6. My goal will be to find a better approximation, but hopefully, I can avoid a horrendous amount of trial and error. It would seem the trick might be to take logs, to get us closer to a solution. That is, suppose I take logs, to the base 2?
log2(3.6)
I used log2 here because that makes the problem a little simpler, since log2(2^p)=p. Therefore we want to find a pair of integers (p,q) such that
log2(3.6) + delta = p + log2(5)*q
where delta is as close to zero as possible. Thus delta is the error in our approximation to 3.6. And since we are working in logs, delta can be viewed as a proportional error term. Again, p and q may be any integers, either positive or negative. The two cases we have seen already have (p,q) = (2,0), and (4,-1).
Do you see the general idea? The line we have is of the form
log2(3.6) = p + log2(5)*q
it represents a line in the (p,q) plane, and we want to find a point on the integer lattice (p,q) where the line passes as closely as possible.
[Xl,Yl] = meshgrid([-10:10]);
plot(Xl,Yl,'k.')
hold on
fimplicit(@(p,q) -log2(3.6) + p + log2(5)*q,[-10,10,-10,10],'g-')
plot([2 4],[0,-1],'ro')
hold off
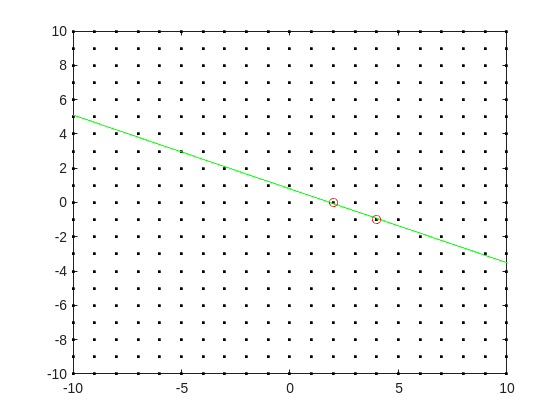
Now, some might think in terms of orthogonal distance to the line, but really, we want the vertical distance to be minimized. Again, minimize abs(delta) in the equation:
log2(3.6) + delta = p + log2(5)*q
where p and q are integer.
Can we do that using MATLAB? The skill about about mathematics often lies in formulating a word problem, and then turning the word problem into a problem of mathematics that we know how to solve. We are almost there now. I next want to formulate this into a problem that intlinprog can solve. The problem at first is intlinprog cannot handle absolute value constraints. And the trick there is to employ slack variables, a terribly useful tool to emply on this class of problem.
Rewrite delta as:
delta = Dpos - Dneg
where Dpos and Dneg are real variables, but both are constrained to be positive.
prob = optimproblem;
p = optimvar('p',lower = -50,upper = 50,type = 'integer');
q = optimvar('q',lower = -50,upper = 50,type = 'integer');
Dpos = optimvar('Dpos',lower = 0);
Dneg = optimvar('Dneg',lower = 0);
Our goal for the ILP solver will be to minimize Dpos + Dneg now. But since they must both be positive, it solves the min absolute value objective. One of them will always be zero.
r = 3.6;
prob.Constraints = log2(r) + Dpos - Dneg == p + log2(5)*q;
prob.Objective = Dpos + Dneg;
The solve is now a simple one. I'll tell it to use intlinprog, even though it would probably figure that out by itself. (Note: if I do not tell solve which solver to use, it does use intlinprog. But it also finds the correct solution when I told it to use GA offline.)
solve(prob,solver = 'intlinprog')
The solution it finds within the bounds of +/- 50 for both p and q seems pretty good. Note that Dpos and Dneg are pretty close to zero.
2^39*5^-16
and while 3.6028979... seems like nothing special, in fact, it is of the form we want.
R = sym(2)^39*sym(5)^-16
vpa(R,100)
vpa(1/R,100)
both of those numbers are exact. If I wanted to find a better approximation to 3.6, all I need do is extend the bounds on p and q. And we can use the same solution approch for any floating point number.