Análisis de valores residuales
Representar y analizar valores residuales
Los valores residuales de un modelo ajustado se definen como las diferencias entre los datos de respuesta y el ajuste de los datos de respuesta en cada valor de predicción.
valor residual = dato – ajuste
Puede mostrar los valores residuales en la app Curve Fitter haciendo clic en Residuals Plot en la sección Visualization, dentro de la pestaña Curve Fitter.
En términos matemáticos, el valor residual de un valor de predicción concreto es la diferencia entre el valor de respuesta y y el valor de respuesta predicho ŷ.
r = y – ŷ
Si el modelo que ajusta a los datos es correcto, los valores residuales son una aproximación a los errores aleatorios. Por lo tanto, si los valores residuales parecen comportarse de manea aleatoria, esto sugiere que el modelo se ajusta bien a los datos. Sin embargo, si los valores residuales muestran un patrón sistemático, está claro que el modelo se ajusta mal a los datos. Tenga en cuenta en todo momento que muchos resultados de ajuste de modelos, como los intervalos de confianza, no serán válidos si el modelo es notablemente inadecuado para los datos.
A continuación, puede ver una demostración gráfica de los valores residuales de un ajuste polinomial de primer grado. La gráfica superior muestra que los valores residuales se calculan como la distancia vertical del punto de datos a la curva ajustada. La gráfica inferior muestra los valores residuales relativos al ajuste, representado por la línea cero.
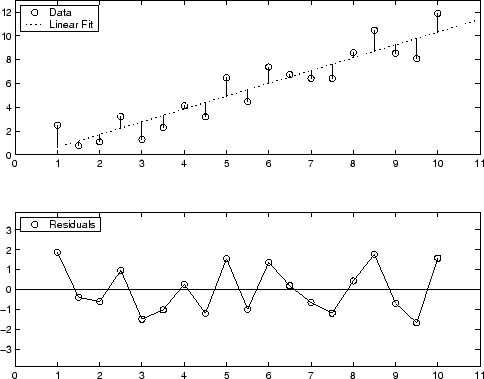
Los valores residuales muestran una dispersión aleatoria alrededor del cero, lo que indica que el modelo describe bien los datos.
A continuación puede ver una demostración gráfica de los valores residuales de un ajuste polinomial de segundo grado. El modelo solo incluye el término cuadrático y no incluye los términos lineal ni constante.
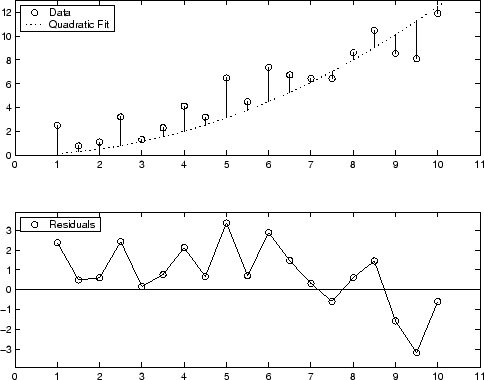
Los valores residuales son positivos de forma sistemática en gran parte del rango de datos, lo que indica que el modelo se ajusta mal a los datos.
Ejemplo: Análisis de valores residuales
Este ejemplo ajusta varios modelos polinomiales a unos datos generados y evalúa si los modelos se ajustan bien a los datos y qué precisión pueden conseguir al predecir otros datos. Los datos se generan a partir de una curva cúbica, con un gran intervalo sin datos en el rango de la variable x.
x = [1:0.1:3 9:0.1:10]'; c = [2.5 -0.5 1.3 -0.1]; y = c(1) + c(2)*x + c(3)*x.^2 + c(4)*x.^3 + (rand(size(x))-0.5);
Ajuste los datos en la app Curve Fitter mediante un polinomio cúbico y otro de quinto grado. A continuación se muestran los datos, los ajustes y los valores residuales. Puede mostrar valores residuales en la app Curve Fitter haciendo clic en Residuals Plot en la sección Visualization, dentro de la pestaña Curve Fitter.
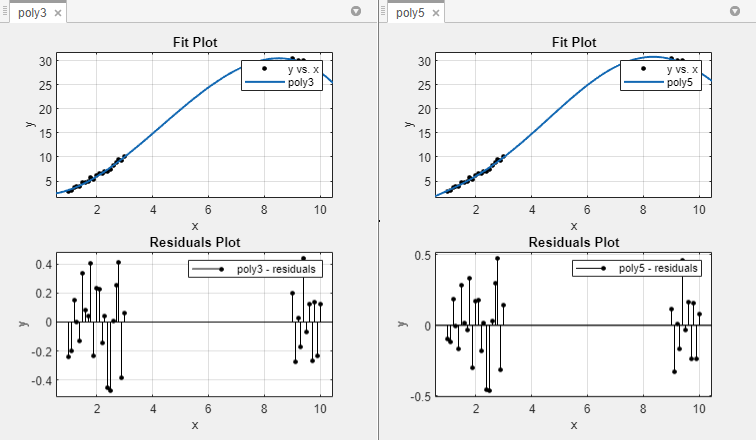
Ambos modelos parecen ajustarse bien a los datos y los valores residuales parecen tener una distribución aleatoria alrededor del cero. Por lo tanto, una evaluación gráfica de los ajustes no revela ninguna diferencia evidente entre ambas ecuaciones.
Fíjese en los resultados del ajuste numérico en el panel Results y compare los intervalos de confianza de los coeficientes.
Los resultados muestran que los coeficientes del ajuste cúbico se conocen con precisión (intervalos de confianza estrechos) pero no ocurre lo mismo con los coeficientes del ajuste de quinto grado. Como se preveía, los resultados del ajuste con poly3 son razonables porque los datos generados parten de una curva cúbica. Los intervalos de confianza del 95% de los coeficientes ajustados indican que su precisión es aceptable. Sin embargo, los intervalos de confianza del 95% de poly5 indican que los coeficientes ajustados no se conocen con precisión.
Las estadísticas de bondad de ajuste se muestran en el panel Table Of Fits. De forma predeterminada, la tabla muestra los valores estadísticos R-cuadrado ajustado y raíz del error cuadrático medio (RMSE). Los valores estadísticos no muestran una diferencia sustancial entre ambas ecuaciones. Para elegir los valores estadísticos que desea mostrar u ocultar, haga clic con el botón secundario en los encabezados de las columnas.
A continuación se muestran los límites de predicción no simultáneos del 95% para nuevas observaciones. Para mostrar los límites de predicción en la app Curve Fitter, seleccione 95% de la lista Prediction Bounds, en la sección Visualization de la pestaña Curve Fitter.
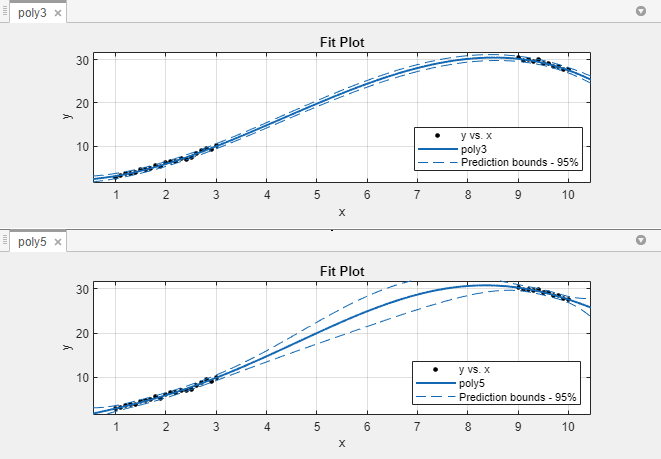
Los límites de predicción de poly3 indican que pueden predecirse nuevas observaciones con poca incertidumbre en todo el rango de datos. Este no es el caso de poly5. que tiene unos límites de predicción más amplios en la zona carente de datos, aparentemente porque los datos no contienen suficiente información para estimar con precisión los polinomios de mayor grado. Dicho de otra forma, un polinomio de quinto grado se sobreajusta a los datos.
A continuación se muestran los límites de predicción del 95% para la función ajustada con poly5. Como puede ver, hay una gran incertidumbre al predecir valores de la función en la zona central de los datos. Por lo tanto, puede concluir que necesita recopilar más datos antes de poder hacer predicciones precisas con un polinomio de quinto grado.
En conclusión, debería examinar todas las medidas de bondad de ajuste disponibles antes de decidirse por el ajuste que mejor se adapta a sus objetivos. El enfoque inicial siempre debería ser un estudio gráfico del ajuste y los valores residuales. Sin embargo, algunas características del ajuste solo se ponen de manifiesto mediante un análisis numérico de los resultados del ajuste, los valores estadísticos y los límites de predicción.