trainnet
Sintaxis
Descripción
netTrained = trainnet(images,net,lossFcn,options)net para tareas de imágenes utilizando las imágenes y objetivos especificados por images y las opciones de entrenamiento definidas por options.
netTrained = trainnet(sequences,net,lossFcn,options)sequences.
netTrained = trainnet(features,net,lossFcn,options)features.
netTrained = trainnet(data,net,lossFcn,options)
[ también devuelve información sobre el entrenamiento utilizando cualquiera de las sintaxis anteriores.netTrained,info] = trainnet(___)
Ejemplos
Si tiene un conjunto de datos de imágenes, puede entrenar una red neuronal profunda utilizando una capa de entrada de imagen.
Descomprima los datos de dígitos de muestra y cree un almacén de datos de imágenes. La función imageDatastore etiqueta automáticamente las imágenes en función de los nombres de carpeta.
unzip("DigitsData.zip") imds = imageDatastore("DigitsData", ... IncludeSubfolders=true, ... LabelSource="foldernames");
Divida los datos en conjuntos de datos de entrenamiento y de prueba, de forma que cada categoría del conjunto de entrenamiento contenga 750 imágenes, y el conjunto de prueba contenga el resto de las imágenes de cada etiqueta. splitEachLabel divide el almacén de datos de imágenes en dos nuevos almacenes de datos para el entrenamiento y la prueba.
numTrainFiles = 750;
[imdsTrain,imdsTest] = splitEachLabel(imds,numTrainFiles,"randomized");Defina la arquitectura de la red neuronal convolucional. Especifique el tamaño de las imágenes de la capa de entrada de la red y el número de clases de la capa final totalmente conectada. Cada imagen tiene un tamaño de 28 por 28 por 1 píxeles.
inputSize = [28 28 1];
classNames = categories(imds.Labels);
numClasses = numel(classNames);
layers = [
imageInputLayer(inputSize)
convolution2dLayer(5,20)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];Especifique las opciones de entrenamiento.
Entrene usando el solver SGDM.
Entrene durante cuatro épocas.
Monitorice el progreso del entrenamiento en una gráfica y monitorice la métrica de precisión.
Deshabilite la salida detallada.
options = trainingOptions("sgdm", ... MaxEpochs=4, ... Verbose=false, ... Plots="training-progress", ... Metrics="accuracy");
Entrene la red neuronal. Para la clasificación, utilice la pérdida de entropía cruzada.
net = trainnet(imdsTrain,layers,"crossentropy",options);
Pruebe la red con el conjunto de pruebas con etiquetas. Evalúe la precisión de la clasificación de una sola etiqueta. La precisión es el porcentaje de etiquetas que la red predice correctamente.
accuracy = testnet(net,imdsTest,"accuracy")accuracy = 98.2400
Prediga las puntuaciones de clasificación utilizando la red entrenada y, luego, convierta las etiquetas en predicciones con la función scores2label.
scoresTest = minibatchpredict(net,imdsTest); YTest = scores2label(scoresTest,classNames);
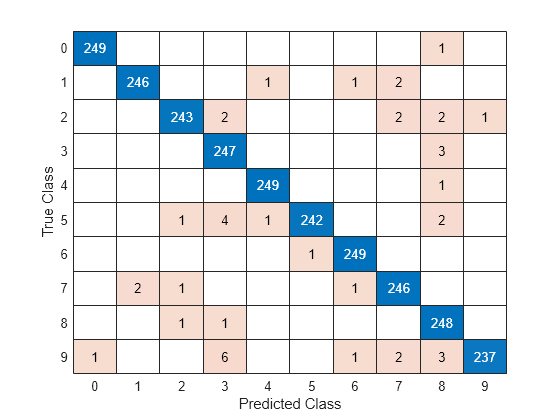
Visualice las predicciones en una gráfica de confusión.
confusionchart(imdsTest.Labels,YTest)
Si tiene un conjunto de datos de características numéricas (por ejemplo, datos tabulares sin dimensiones espaciales ni temporales), puede entrenar una red neuronal profunda utilizando una capa de entrada de características.
Lea los datos de la caja de engranajes del archivo CSV "transmissionCasingData.csv".
filename = "transmissionCasingData.csv"; tbl = readtable(filename,TextType="String");
Convierta las etiquetas para la predicción en categóricas utilizando la función convertvars.
labelName = "GearToothCondition"; tbl = convertvars(tbl,labelName,"categorical");
Para entrenar una red utilizando características categóricas, primero debe convertir las características categóricas en numéricas. Primero, convierta los predictores categóricos en numéricos con la función convertvars especificando un arreglo de cadena que contenga los nombres de todas las variables de entrada categórica. En este conjunto de datos, hay dos características categóricas con los nombres "SensorCondition" y "ShaftCondition".
categoricalPredictorNames = ["SensorCondition" "ShaftCondition"]; tbl = convertvars(tbl,categoricalPredictorNames,"categorical");
Forme un lazo con las variables de entrada categórica. Para cada variable, convierta los valores categóricos en vectores codificados one-hot usando la función onehotencode.
for i = 1:numel(categoricalPredictorNames) name = categoricalPredictorNames(i); tbl.(name) = onehotencode(tbl.(name),2); end
Visualice las primeras filas de la tabla. Observe que los predictores categóricos se han dividido en varias columnas.
head(tbl)
SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis SensorCondition ShaftCondition GearToothCondition
________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ______________ __________________
-0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 0 1 1 0 No Tooth Fault
-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08e-08 9.16e-08 226.12 0 1 1 0 No Tooth Fault
1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74e-06 2.85e-07 162.13 0 1 0 1 No Tooth Fault
1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4e-07 162.13 0 1 0 1 No Tooth Fault
1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62e-06 2.28e-07 230.39 0 1 0 1 No Tooth Fault
1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 0 1 0 1 No Tooth Fault
1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 0 1 0 1 No Tooth Fault
1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 0 1 0 1 No Tooth Fault
Visualice los nombres de las clases del conjunto de datos.
classNames = categories(tbl{:,labelName})classNames = 2×1 cell
{'No Tooth Fault'}
{'Tooth Fault' }
Reserve datos para pruebas. Divida los datos en un conjunto de entrenamiento que contenga el 85% de los datos y en un conjunto de prueba que contenga el 15% restante. Para dividir los datos, use la función trainingPartitions, incluida en este ejemplo como un archivo de soporte. Para acceder al archivo, abra el ejemplo como un script en vivo.
numObservations = size(tbl,1); [idxTrain,idxTest] = trainingPartitions(numObservations,[0.85 0.15]); tblTrain = tbl(idxTrain,:); tblTest = tbl(idxTest,:);
Convierta los datos a un formato compatible con la función trainnet. Convierta los predictores y objetivos en arreglos numéricos y categóricos, respectivamente. Para la entrada de características, la red espera datos con filas que correspondan a las observaciones y columnas que correspondan a las características. Si los datos tienen un diseño diferente, puede preprocesarlos para que tengan este diseño o puede proporcionar información de diseño utilizando formatos de datos. Para obtener más información, consulte Deep Learning Data Formats.
predictorNames = ["SigMean" "SigMedian" "SigRMS" "SigVar" "SigPeak" "SigPeak2Peak" ... "SigSkewness" "SigKurtosis" "SigCrestFactor" "SigMAD" "SigRangeCumSum" ... "SigCorrDimension" "SigApproxEntropy" "SigLyapExponent" "PeakFreq" ... "HighFreqPower" "EnvPower" "PeakSpecKurtosis" "SensorCondition" "ShaftCondition"]; XTrain = table2array(tblTrain(:,predictorNames)); TTrain = tblTrain.(labelName); XTest = table2array(tblTest(:,predictorNames)); TTest = tblTest.(labelName);
Defina una red con una capa de entrada de características y especifique el número de características. Configure también la capa de entrada para normalizar los datos utilizando la normalización de puntuación Z.
numFeatures = size(XTrain,2);
numClasses = numel(classNames);
layers = [
featureInputLayer(numFeatures,Normalization="zscore")
fullyConnectedLayer(16)
layerNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];Especifique las opciones de entrenamiento:
Entrenar usando el solver L-BFGS. Este solver es adecuado para tareas con redes pequeñas y cuando los datos caben en la memoria.
Entrenar usando la CPU. Dado que la red y los datos son pequeños, la CPU es más adecuada.
Muestre el progreso del entrenamiento en una gráfica.
Suprimir la salida detallada.
options = trainingOptions("lbfgs", ... ExecutionEnvironment="cpu", ... Plots="training-progress", ... Verbose=false);
Entrene la red con la función trainnet. Para la clasificación, utilice la pérdida de entropía cruzada.
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
Pruebe la red con el conjunto de pruebas con etiquetas. Evalúe la precisión de la clasificación de una sola etiqueta. La precisión es el porcentaje de etiquetas que la red predice correctamente.
accuracy = testnet(net,XTest,TTest,"accuracy")accuracy = 100
Prediga las etiquetas de los datos de prueba con la red entrenada. Prediga las puntuaciones de clasificación utilizando la red entrenada y luego convierta las predicciones en etiquetas con la función scores2label.
scoresTest = minibatchpredict(net,XTest); YTest = scores2label(scoresTest,classNames);
Visualice las predicciones en una gráfica de confusión.
confusionchart(TTest,YTest)

Argumentos de entrada
Argumentos de salida
Más acerca de
Sugerencias
Para tareas de regresión, normalizar los objetivos suele ayudar a estabilizar y acelerar el entrenamiento. Para obtener más información, consulte Entrenar una red neuronal convolucional para regresión.
En la mayoría de los casos, si el predictor o los objetivos contienen valores
NaN, estos se propagan por la red y el entrenamiento no converge.Para convertir un arreglo numérico a un almacén de datos, use
ArrayDatastore.Cuando combine capas en una red neuronal con tipos de datos mezclados, puede que tenga que volver a establecer el formato de los datos antes de pasarlos a una capa de combinación (como una capa de concatenación o una capa de suma). Para volver a establecer el formato de los datos, puede utilizar una capa aplanada para aplanar las dimensiones espaciales a la dimensión del canal, o crear un objeto
FunctionLayero una capa personalizada que vuelva a establecer el formato y cambie la forma de los datos.
Algoritmos
Capacidades ampliadas
Historial de versiones
Introducido en R2023bConsulte también
dlnetwork | trainingOptions | testnet | minibatchpredict | scores2label | minibatchqueue | Deep Network Designer