Cómo funciona el algoritmo genético
Esquema del algoritmo
El siguiente esquema resume cómo funciona el algoritmo genético:
El algoritmo comienza creando una población inicial aleatoria.
Luego, el algoritmo crea una secuencia de nuevas poblaciones. En cada paso, el algoritmo utiliza los individuos de la generación actual para crear la siguiente población. Para crear la nueva población, el algoritmo realiza los siguientes pasos:
Califica a cada miembro de la población actual calculando su valor de aptitud. Estos valores se denominan puntuaciones de aptitud sin procesar.
Escala las puntuaciones de aptitud sin procesar para convertirlas en un rango de valores más utilizable. Estos valores escalados se denominan valores esperados.
Selecciona a los miembros, llamados padres, en función de sus expectativas.
Algunos de los individuos de la población actual que tienen una aptitud física más baja son elegidos como élite. Estos individuos de élite pasan a la siguiente población.
Produce hijos de los padres. Los niños se producen ya sea haciendo cambios aleatorios en un solo padre—mutación—o combinando las entradas vectoriales de un par de padres—cruce.
Reemplaza la población actual con los niños para formar la próxima generación.
El algoritmo se detiene cuando se cumple uno de los criterios de detención. Consulte Condiciones de detención del algoritmo.
El algoritmo toma pasos modificados para restricciones lineales y enteras. Consulte Restricciones enteras y lineales.
El algoritmo se modifica aún más para restricciones no lineales. Consulte Algoritmos de resolución de restricciones no lineales para algoritmos genéticos.
Población inicial
El algoritmo comienza creando una población inicial aleatoria, como se muestra en la siguiente figura.
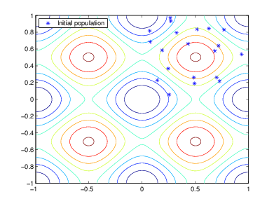
En este ejemplo, la población inicial contiene 20 individuos. Nótese que todos los individuos de la población inicial se encuentran en el cuadrante superior derecho de la imagen, es decir, sus coordenadas están entre 0 y 1. Para este ejemplo, la opción InitialPopulationRange es [0;1].
Si sabe aproximadamente dónde se encuentra el punto mínimo de una función, debe configurar InitialPopulationRange para que el punto se encuentre cerca de la mitad de ese rango. Por ejemplo, si cree que el punto mínimo de la función de Rastrigin está cerca del punto [0 0], podría establecer InitialPopulationRange como [-1;1]. Sin embargo, como muestra este ejemplo, el algoritmo genético puede encontrar el mínimo incluso con una elección menos que óptima para InitialPopulationRange.
Crear la próxima generación
En cada paso, el algoritmo genético utiliza la población actual para crear los niños que formarán la próxima generación. El algoritmo selecciona un grupo de individuos de la población actual, llamados padres, quienes aportan sus genes (las entradas de sus vectores) a sus hijos. El algoritmo generalmente selecciona a los individuos que tienen mejores valores de aptitud física como padres. Puede especificar la función que utiliza el algoritmo para seleccionar a los padres en la opción SelectionFcn. Consulte Selection Options.
El algoritmo genético crea tres tipos de hijos para la próxima generación:
Los niños de élite son los individuos de la generación actual con los mejores valores de aptitud física. Estos individuos sobreviven automáticamente a la siguiente generación.
Cruce Los hijos se crean combinando los vectores de un par de padres.
Mutación Los hijos se crean introduciendo cambios aleatorios, o mutaciones, en un solo padre.
El siguiente diagrama esquemático ilustra los tres tipos de niños.
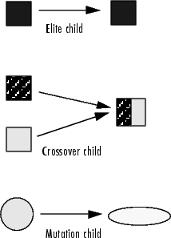
Mutación y cruce explica cómo especificar el número de hijos de cada tipo que genera el algoritmo y las funciones que utiliza para realizar cruces y mutaciones.
Las siguientes secciones explican cómo el algoritmo crea hijos de cruce y mutación.
Hijos cruzados
El algoritmo crea niños cruzados combinando pares de padres en la población actual. En cada coordenada del vector hijo, la función de cruce predeterminada selecciona aleatoriamente una entrada, o gen, en la misma coordenada de uno de los dos padres y se la asigna al hijo. Para problemas con restricciones lineales, la función de cruce predeterminada crea al hijo como un promedio ponderado aleatorio de los padres.
Niños con mutaciones
El algoritmo crea niños mutantes modificando aleatoriamente los genes de cada uno de sus padres. De forma predeterminada, para problemas sin restricciones, el algoritmo agrega un vector aleatorio de una distribución gaussiana a la distribución principal. En problemas acotados o linealmente restringidos, el niño sigue siendo factible.
La siguiente figura muestra los hijos de la población inicial, es decir, la población de la segunda generación, e indica si son hijos de élite, de cruce o de mutación.
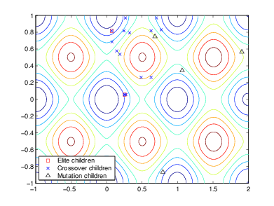
Gráficas de generaciones posteriores
La siguiente figura muestra las poblaciones en las iteraciones 60, 80, 95 y 100.
|
|
|
|
|
|
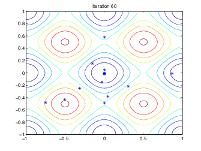
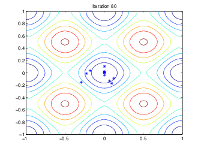
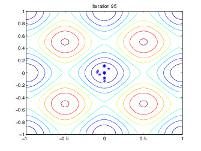
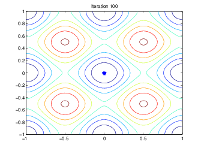
A medida que aumenta el número de generaciones, los individuos de la población se acercan entre sí y se aproximan al punto mínimo [0 0].
Condiciones de detención del algoritmo
El algoritmo genético utiliza las siguientes opciones para determinar cuándo detenerse. Vea los valores predeterminados para cada opción ejecutando opts = optimoptions('ga') .
MaxGenerations— El algoritmo se detiene cuando el número de generaciones llega aMaxGenerations.MaxTime— El algoritmo se detiene después de ejecutarse durante un tiempo en segundos igual aMaxTime.FitnessLimit— El algoritmo se detiene cuando el valor de la función de aptitud para el mejor punto en la población actual es menor o igual aFitnessLimit.MaxStallGenerations— El algoritmo se detiene cuando el cambio relativo promedio en el valor de la función de aptitud sobreMaxStallGenerationses menor queFunction tolerance.MaxStallTime— El algoritmo se detiene si no hay mejora en la función objetivo durante un intervalo de tiempo en segundos igual aMaxStallTime.FunctionTolerance— El algoritmo se ejecuta hasta que el cambio relativo promedio en el valor de la función de aptitud enMaxStallGenerationssea menor queFunction tolerance.ConstraintTolerance— ElConstraintToleranceno se utiliza como criterio de detención. Se utiliza para determinar la viabilidad con respecto a restricciones no lineales. Además,max(sqrt(eps),ConstraintTolerance)determina la viabilidad con respecto a las restricciones lineales.
El algoritmo se detiene tan pronto como se cumple cualquiera de estas condiciones.
Selección
La función de selección elige a los padres para la próxima generación en función de sus valores escalados de la función de escala de aptitud. Los valores de aptitud escalados se denominan valores esperados. Un individuo puede ser seleccionado más de una vez como padre, en cuyo caso aporta sus genes a más de un hijo. La opción de selección predeterminada, @selectionstochunif, establece una línea en la que cada padre corresponde a una sección de la línea de longitud proporcional a su valor escalado. El algoritmo se mueve a lo largo de la línea en pasos de igual tamaño. En cada paso, el algoritmo asigna un padre de la sección en la que aterriza.
Una opción de selección más determinista es @selectionremainder, que realiza dos pasos:
En el primer paso, la función selecciona a los padres de forma determinista según la parte entera del valor escalado para cada individuo. Por ejemplo, si el valor escalado de un individuo es 2,3, la función selecciona a ese individuo dos veces como padre.
En el segundo paso, la función de selección selecciona padres adicionales utilizando las partes fraccionarias de los valores escalados, como en la selección uniforme estocástica. La función traza una línea en secciones, cuyas longitudes son proporcionales a la parte fraccionaria del valor escalado de los individuos, y se mueve a lo largo de la línea en pasos iguales para seleccionar a los padres.
Tenga en cuenta que si las partes fraccionarias de los valores escalados son todas iguales a 0, como puede ocurrir utilizando el escalado
Top, la selección es completamente determinista.
Para obtener más detalles y más opciones de selección, consulte Selection Options .
Opciones de reproducción
Las opciones de reproducción controlan cómo el algoritmo genético crea la próxima generación. Las opciones son
EliteCount— La cantidad de individuos con los mejores valores de aptitud física en la generación actual que tienen garantía de sobrevivir hasta la próxima generación. A estos individuos se les llama niños de élite.Cuando
EliteCountes al menos 1, el mejor valor de aptitud solo puede disminuir de una generación a la siguiente. Esto es lo que se quiere que suceda, ya que el algoritmo genético minimiza la función de aptitud. EstablecerEliteCounten un valor alto hace que los individuos más aptos dominen la población, lo que puede hacer que la búsqueda sea menos efectiva.CrossoverFraction— La fracción de individuos en la siguiente generación, aparte de los hijos de la élite, que se crean por cruce. El tema "Configuración de la fracción de cruce" en Vary Mutation and Crossover describe cómo el valor deCrossoverFractionafecta el rendimiento del algoritmo genético.
Debido a que los individuos de élite ya han sido evaluados, ga no reevalúa la función de aptitud de los individuos de élite durante la reproducción. Este comportamiento supone que la función de aptitud de un individuo no es aleatoria, sino una función determinista. Para cambiar este comportamiento, utilice una función de salida. Ver EvalElites en The State Structure .
Mutación y cruce
El algoritmo genético utiliza a los individuos de la generación actual para crear los hijos que formarán la próxima generación. Además de los niños de élite, que corresponden a los individuos de la generación actual con los mejores valores de aptitud física, el algoritmo crea
Cruzar a los niños seleccionando entradas de vectores, o genes, de un par de individuos en la generación actual y combinarlos para formar un niño.
Mutación de niños mediante la aplicación de cambios aleatorios a un solo individuo en la generación actual para crear un niño.
Ambos procesos son esenciales para el algoritmo genético. El cruce permite que el algoritmo extraiga los mejores genes de diferentes individuos y los recombine para crear hijos potencialmente superiores. La mutación aumenta la diversidad de una población y, por lo tanto, aumenta la probabilidad de que el algoritmo genere individuos con mejores valores de aptitud.
Consulte Crear la próxima generación para ver un ejemplo de cómo el algoritmo genético aplica la mutación y el cruce.
Puede especificar cuántos niños de cada tipo crea el algoritmo de la siguiente manera:
EliteCountespecifica el número de hijos de élite.CrossoverFractionespecifica la fracción de la población, aparte de los hijos de élite, que son hijos cruzados.
Por ejemplo, si PopulationSize es 20, EliteCount es 2 y CrossoverFraction es 0.8, los números de cada tipo de hijos en la próxima generación son los siguientes:
Hay dos niños de élite.
Hay 18 individuos además de los niños de élite, por lo que el algoritmo redondea 0,8*18 = 14,4 a 14 para obtener el número de niños cruzados.
Los cuatro individuos restantes, aparte de los niños de élite, son hijos de la mutación.
Restricciones enteras y lineales
Cuando un problema tiene restricciones enteras o lineales (incluidos límites), el algoritmo modifica la evolución de la población.
Cuando el problema tiene restricciones tanto enteras como lineales, el software modifica todos los individuos generados para que sean factibles con respecto a esas restricciones. Puede utilizar cualquier función de creación, mutación o cruce, y toda la población seguirá siendo factible con respecto a las restricciones enteras y lineales.
Cuando el problema sólo tiene restricciones lineales, el software no modifica a los individuos para que sean factibles con respecto a esas restricciones. Debe utilizar funciones de creación, mutación y cruce que mantengan la viabilidad con respecto a las restricciones lineales. De lo contrario, la población puede volverse inviable y el resultado puede ser inviable. Los operadores predeterminados mantienen la viabilidad lineal:
gacreationlinearfeasibleogacreationnonlinearfeasiblepara la creación,mutationadaptfeasiblepara la mutación ycrossoverintermediatepara el cruce.
Los algoritmos internos para viabilidad entera y lineal son similares a los de surrogateopt. Cuando un problema tiene restricciones enteras y lineales, el algoritmo primero crea puntos linealmente factibles. Luego, el algoritmo intenta satisfacer las restricciones de números enteros redondeando los puntos linealmente factibles a números enteros utilizando una heurística que intenta mantener los puntos linealmente factibles. Cuando este proceso no logra obtener suficientes puntos factibles para construir una población, el algoritmo llama a intlinprog para intentar encontrar más puntos que sean factibles con respecto a los límites, las restricciones lineales y las restricciones enteras.
Más tarde, cuando la mutación o el cruce crean nuevos miembros de la población, los algoritmos garantizan que los nuevos miembros sean enteros y linealmente factibles tomando pasos similares. Cada nuevo miembro se modifica, si es necesario, para que sea lo más cercano posible a su valor original, satisfaciendo al mismo tiempo las restricciones y límites enteros y lineales.