Get Started with Hyperspectral Image Processing
Hyperspectral imaging measures the spatial and spectral characteristics of an object by imaging it at numerous different wavelengths. The wavelength range extends beyond the visible spectrum and covers the spectrum from ultraviolet (UV) to long wave infrared (LWIR) wavelengths. The most popular are the visible, near-infrared, and mid-infrared wavelength bands. A hyperspectral imaging sensor acquires several images with narrow and contiguous wavelengths within a specified spectral range. Each of these images contains more subtle and detailed information. The different information in the various wavelengths is useful in diverse applications such as these.
Remote sensing applications such as identification of vegetation, water bodies, and roads, as different landscapes have distinct spectral signatures.
Non-destructive testing or visual inspection applications such as maturity monitoring of fruits.
Medical imaging applications such as tissue segmentation.
Hyperspectral image processing involves representing, analyzing, and interpreting information contained in hyperspectral images.
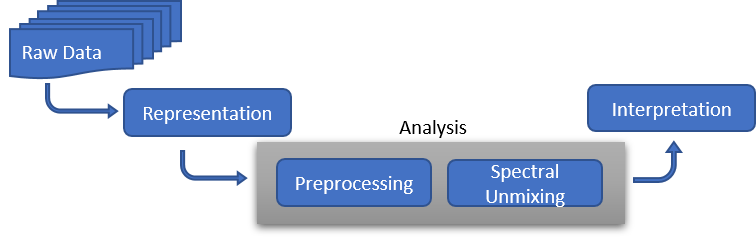
Representing Hyperspectral Data
The values measured by a hyperspectral imaging sensor are stored to a binary data file by using band sequential (BSQ), band-interleaved-by-pixel (BIP), or band-interleaved-by-line (BIL) encoding formats. The data file is associated to a header file that contains ancillary information (metadata) like sensor parameters, acquisition settings, spatial dimensions, spectral wavelengths, and encoding formats that are required for proper representation of the values in the data file. Alternatively, the ancillary information can also be directly added to the data file as in TIFF and NITF file formats.
For hyperspectral image processing, the values read from the data file are arranged into a three-dimensional (3-D) array of the form M-by-N-by-C, where M and N are the spatial dimensions of the acquired data, C is the spectral dimension specifying the number of spectral wavelengths (bands) used during acquisition. Thus, you can consider the 3-D array as a set of two-dimensional (2-D) monochromatic images captured at varying wavelengths. This set is known as the hyperspectral data cube or data cube.
The Hyperspectral Imaging Library for Image Processing
Toolbox™ enables you to represent hyperspectral data and its metadata as a
hypercube object. The imhypercube and geohypercube functions create hypercube objects
to store the data cube, spectral wavelengths, and the metadata. While the
imhypercube function does not store any geospatial
information in the hypercube object, the
geohypercube function stores geospatial information in the
Metadata property of the hypercube object.
You can use the hypercube object as input to other functions in
the Hyperspectral Imaging Library for Image Processing
Toolbox. You can use the Hyperspectral
Viewer app to interactively visualize and process hyperspectral images
directly from files or from hypercube objects.
Large Hyperspectral Images
Processing hyperspectral images of very large spatial resolution requires a large
amount of system memory, and might cause MATLAB to run out of memory. You can crop a
large hyperspectral image to a small region of interest, and then read only that
small region into memory using the hypercube object and its
functions. For an example of how to process small regions of large hyperspectral
images, see Process Large Hyperspectral and Multispectral Images.
Color Representation of Data Cube
To visualize and understand the object being imaged, it is useful to represent the
data cube as a 2-D image by using color schemes. The color representation of the
data cube enables you to visually inspect the data and supports decision making. You
can use the colorize function to compute the Red-Green-Blue (RGB), false-color,
and color-infrared (CIR) representations of the data cube.
The RGB color scheme uses the red, green, and blue spectral band responses to generate the 2-D image of the hyperspectral data cube. The RGB color scheme brings a natural appearance, but results in a significant loss of subtle information.
The false-color scheme uses a combination of any number of bands other than the visible red, green, and blue spectral bands. Use false-color representation to visualize the spectral responses of bands outside the visible spectrum. The false-color scheme efficiently captures distinct information across all spectral bands of hyperspectral data.
The CIR color scheme uses spectral bands in the NIR range. The CIR representation of a hyperspectral data cube is particularly useful in displaying and analyzing vegetation areas of the data cube.
Preprocessing
The hyperspectral imaging sensors typically have high spectral resolution and low spatial resolution. The spatial and the spectral characteristics of the acquired hyperspectral data are characterized by its pixels. Each pixel is a vector of values that specify the intensities at a location (x,y) in z different bands. The vector is known as the pixel spectrum, and it defines the spectral signature of the pixel located at (x,y). The pixel spectra are important features in hyperspectral data analysis. But these pixel spectra gets distorted due to factors such as sensor noise, low resolution, atmospheric effects, and spectral distortions from sensors.
![]()
You can use the denoiseNGMeet function to remove noise from a hyperspectral data by
using the non-local meets global approach.
To enhance the spatial resolution of a hyperspectral data, you can use image
fusion methods. The fusion approach combines information from the low resolution
hyperspectral data with a high resolution multispectral data or panchromatic image
of the same scene. This approach is also known as sharpening
or pansharpening in hyperspectral image analysis.
Pansharpening specifically refers to fusion between hyperspectral and panchromatic
data. You can use the sharpencnmf function for sharpening hyperspectral data using coupled
non-negative matrix factorization method.
To compensate for the atmospheric effects, you must first calibrate the pixel values, which are digital numbers (DNs). You must preprocess the data by calibrating DNs using radiometric and atmospheric correction methods. This process improves interpretation of the pixel spectra and provides better results when you analyse multiple data sets. In addition, spectral distortions which occur due to hyperspectral sensor characteristics during acquisition, can lead to inaccuracies in the spectral signatures. To enhance the reliability of spectral data for further analysis, you must apply preprocessing techniques that significantly reduce spectral distortions in hyperspectral images. For information about hyperspectral data correction methods, see Hyperspectral and Multispectral Data Correction.
The other preprocessing step that is important in all hyperspectral imaging applications is dimensionality reduction. The large number of bands in the hyperspectral data increases the computational complexity of processing the data cube. The contiguous nature of the band images results in redundant information across bands. Neighboring bands in a hyperspectral image have high correlation, which results in spectral redundancy. You can remove the redundant bands by decorrelating the band images. Popular approaches for reducing the spectral dimensionality of a data cube include band selection and orthogonal transforms.
The band selection approach uses orthogonal space projections to find the spectrally distinct and most informative bands in the data cube. Use the
selectBandsandremoveBandsfunctions for the finding most informative bands and removing one or more bands, respectively.Orthogonal transforms such as principal component analysis (PCA) and maximum noise fraction (MNF), decorrelate the band information and find the principal component bands.
PCA transforms the data to a lower dimensional space and finds principal component vectors with their directions along the maximum variances of the input bands. The principal components are in descending order of the amount of total variance explained.
MNF computes the principal components that maximize the signal-to-noise ratio, rather than the variance. MNF transform is particularly efficient at deriving principal components from noisy band images. The principal component bands are spectrally distinct bands with low interband correlation.
The
hyperpcaandhypermnffunctions reduce the spectral dimensionality of the data cube by using the PCA and MNF transforms respectively. You can use the pixel spectra derived from the reduced data cube for hyperspectral data analysis.
Spectral Unmixing
In a hyperspectral image, the intensity values recorded at each pixel specify the spectral characteristics of the region that the pixel belongs to. The region can be a homogeneous surface or heterogeneous surface. The pixels that belong to a homogeneous surface are known as pure pixels. These pure pixels constitute the endmembers of the hyperspectral data.
Heterogeneous surfaces are a combination of two or more distinct homogeneous surfaces. The pixels belonging to heterogeneous surfaces are known as mixed pixels. The spectral signature of a mixed pixel is a combination of two or more endmember signatures. This spatial heterogeneity is mainly due to the low spatial resolution of the hyperspectral sensor.

Spectral unmixing is the process of decomposing the spectral signatures of mixed pixels into their constituent endmembers. The spectral unmixing process involves two steps:
Endmember extraction — The spectra of the endmembers are prominent features in the hyperspectral data and can be used for efficient spectral unmixing of hyperspectral images. Convex geometry based approaches, such as pixel purity index (PPI), fast iterative pixel purity index (FIPPI), and N-finder (N-FINDR) are some of the efficient approaches for endmember extraction.
Use the
ppifunction to estimate the endmembers by using the PPI approach. The PPI approach projects the pixel spectra to an orthogonal space and identifies extrema pixels in the projected space as endmembers. This is a non-iterative approach, and the results depend on the random unit vectors generated for orthogonal projection. To improve results, you must increase the random unit vectors for projection, which can be computationally expensive.Use the
fippifunction to estimate the endmembers by using the FIPPI approach. The FIPPI approach is an iterative approach, which uses an automatic target generation process to estimate the initial set of unit vectors for orthogonal projection. The algorithm converges faster than the PPI approach and identifies endmembers that are distinct from one another.Use the
nfindrfunction to estimate the endmembers by using the N-FINDR method. N-FINDR is an iterative approach that constructs a simplex by using the pixel spectra. The approach assumes that the volume of a simplex formed by the endmembers is larger than the volume defined by any other combination of pixels. The set of pixel signatures for which the volume of the simplex is high are the endmembers.
Abundance map estimation — Given the endmember signatures, it is useful to estimate the fractional amount of each endmember present in each pixel. You can generate the abundance maps for each endmember, which represent the distribution of endmember spectra in the image. You can label a pixel as belonging to an endmember spectra by comparing all of the abundance map values obtained for that pixel.
Use the
estimateAbundanceLSfunction to estimate the abundance maps for each endmember spectra.
Spectral Matching and Target Detection
Interpret the pixel spectra by performing spectral matching using the spectralMatch function or target detection using the detectTarget function. Spectral matching
identifies the class of an endmember material by comparing its spectra with one or
more reference spectra. The reference data consists of pure spectral signatures of
materials, which are available as spectral libraries. Use the readEcostressSig function to read the reference spectra files from
the ECOSTRESS spectral library. Then, you can compute the similarity between the
spectra in the ECOSTRESS library files and the spectra of an endmember material by
using the spectralMatch function.
You can also use spectral matching to identify materials or perform
target detection, detecting specific targets in a
hyperspectral image when the spectral signature of the target is distinct from other
regions in the hyperspectral image. However, when the spectral contrast between the
target and other regions is low, spectral matching becomes more challenging. In such
cases, you must use more sophisticated target detection algorithms, such as those
provided by the detectTarget function, that consider the entire hyperspectral data
cube and use statistical or machine learning methods. For more information on
spectral matching and target detection techniques, see Spectral Matching and Target Detection Techniques.
Spectral Indices and Segmentation
A spectral index is a function such as a ratio or
difference of two or more spectral bands. Spectral indices delineate and identify
different regions in an image based on their spectral properties. By calculating a
spectral index for each pixel, you can transform the hyperspectral data into a
single-band image where the index values indicate the presence and concentration of
a feature of interest. Use the spectralIndices and customSpectralIndex functions to identify different regions in the
hyperspectral image. Preprocess the hyperspectral image to set to zero any negative
pixel values arising because of sensor issues. For more information on spectral
indices, see Spectral Indices.
You can also use the spectral indices for change detection and threshold-based
segmentation of hyperspectral images. To segment regions that cannot be
distinguished using spectral indices, you can use spectral clustering approaches
such as Simple Linear Iterative Clustering (SLIC) with the hyperslic function or anchor graphs with the hyperseganchor function.
Applications
Hyperspectral image processing applications include land cover classification, material analysis, target detection, change detection, visual inspection, and medical image analysis.
Classify land cover by classifying each pixel in a hyperspectral image. For examples of classification, see these examples.
Identify materials in a hyperspectral image using a spectral library. For an example, see Endmember Material Identification Using Spectral Library.
Perform target detection by matching the known spectral signature of a target material to the pixel spectra in hyperspectral data. For examples of target detection, see Target Detection Using Spectral Signature Matching and Ship Detection from Sentinel-1 C Band SAR Data Using YOLOX Object Detection.
Detect changes in hyperspectral images over time. For examples of change detection, see Change Detection in Hyperspectral Images and Map Flood Areas Using Sentinel-1 SAR Imagery.
Perform visual inspection and non-destructive testing operations, such as maturity monitoring of fruit. The comprehensive spectral data available in hyperspectral images enables precise and non-destructive analysis. For an example, see Predict Sugar Content in Grape Berries Using PLS Regression on Hyperspectral Data.
Analyze hyperspectral medical images. For an example, see Segment Spleen in Hyperspectral Image of Porcine Tissue.
See Also
hypercube | multicube | Hyperspectral
Viewer