Expresiones regulares
Este tema describe qué expresiones son expresiones regulares y cómo utilizarlas para buscar texto. Las expresiones regulares son flexibles y potentes, aunque utilicen una sintaxis compleja. Una alternativa a las expresiones regulares es un pattern (desde la versión R2020b), que es más sencilla de definir y resulta en un código que es más sencillo de leer. Para obtener más información, consulte Build Pattern Expressions.
¿Qué es una expresión regular?
Una expresión regular es una secuencia de caracteres que define un patrón determinado. Habitualmente, utiliza una expresión regular para buscar texto de un grupo de palabras que coinciden con el patrón, por ejemplo, al analizar la entrada de un programa o durante el procesamiento de un bloque de texto.
El vector de caracteres 'Joh?n\w*' es un ejemplo de expresión regular. Define un patrón que comienza con las letras Jo, va seguido de manera opcional por la letra h (indicada por 'h?'), después por la letra n y termina con cualquier número de caracteres de palabra, es decir, caracteres alfabéticos, numéricos o guiones bajos (indicado por '\w*'). Este patrón coincide con cualquiera de lo siguiente:
Jon, John, Jonathan, Johnny
Las expresiones regulares ofrecen una forma única de buscar un volumen de texto para un subconjunto determinado de caracteres en dicho texto. En lugar de buscar una coincidencia exacta de caracteres como haría con una función como strfind, las expresiones regulares le ofrecen la posibilidad de buscar un patrón de caracteres en concreto.
Por ejemplo, algunas formas de expresar una velocidad en el sistema métrico son:
km/h km/hr km/hour kilometers/hour kilometers per hour
Puede localizar cualquiera de los términos anteriores en el texto enviando cinco comandos de búsqueda distintos:
strfind(text, 'km/h'); strfind(text, 'km/hour'); % etc.
Sin embargo, para ser más eficiente, puede crear una única frase que se aplique a todos estos términos de búsqueda:
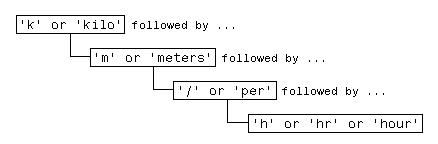
Traduzca esta frase en una expresión regular (se explicará más adelante en esta sección) y tiene:
pattern = 'k(ilo)?m(eters)?(/|\sper\s)h(r|our)?';
Ahora localice un término o varios con un único comando:
text = ['The high-speed train traveled at 250 ', ... 'kilometers per hour alongside the automobile ', ... 'travelling at 120 km/h.']; regexp(text, pattern, 'match')
ans =
1×2 cell array
{'kilometers per hour'} {'km/h'}
Existen cuatro funciones de MATLAB® compatibles con la búsqueda y el reemplazo de caracteres con expresiones regulares. Las tres primeras son similares en los valores de entrada que aceptan y los valores de salida que devuelven. Para obtener más información, haga clic en los enlaces de las páginas de referencia de la función.
| Función | Descripción |
|---|---|
regexp | Hacer coincidir expresiones regulares. |
regexpi | Hacer coincidir expresiones regulares ignorando mayúsculas y minúsculas. |
regexprep | Sustituir parte del texto utilizando expresiones regulares. |
regexptranslate | Traducir el texto en expresiones regulares. |
Cuando llame a cualquiera de las tres primeras funciones, pase el texto que desea analizar y la expresión regular como los dos primeros argumentos de entrada. Cuando llame a regexprep, pase una entrada adicional que es una expresión que especifica un patrón para el reemplazo.
Pasos para la formación de expresiones
Hay tres pasos implicados en el uso de expresiones regulares para buscar un elemento específico en un texto:
Identificar los patrones únicos de la cadena
Esto implica dividir el texto que desea buscar en grupos de tipos de caracteres similares. Estos tipos de caracteres pueden ser una serie de letras en minúscula, el símbolo de dólar seguido por tres números y un separador decimal, etc.
Expresar cada patrón como una expresión regular
Utilice los metacaracteres y los operadores que se describen en esta documentación para expresar cada segmento del patrón de búsqueda como una expresión regular. Después, combine estos segmentos de expresiones en una única expresión para utilizarla en la búsqueda.
Llamar a la función de búsqueda adecuada
Pase el texto que desea analizar a una de las funciones de búsqueda, como
regexporegexpi, o a la función de reemplazo de texto,regexprep.
El ejemplo que se muestra en esta sección busca un registro que contenga la información de contacto que pertenece a un grupo de cinco amigos. Esta información incluye el nombre, el número de teléfono, el lugar de residencia y la dirección de correo electrónico de cada persona. El objetivo es extraer información específica del texto.
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
La primera parte del ejemplo forma una expresión regular que representa el formato común de una dirección de correo electrónico. Utilizando esta expresión, el ejemplo busca la información de la dirección de correo electrónico de un componente del grupo de amigos. La información de contacto de Janice se encuentra en la fila 2 del arreglo de celda contacts:
contacts{2}
ans =
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'
Paso 1 — Identificar los patrones únicos del texto
Una dirección de correo electrónico está formada por componentes estándar: el nombre de cuenta del usuario, seguido del símbolo @, el nombre del proveedor de servicios de Internet (PSI) del usuario, un punto y el dominio al que pertenece el PSI. La tabla que aparece a continuación enumera estos componentes en la columna de la izquierda y generaliza el formato de cada componente en la columna de la derecha.
| Patrones únicos de una dirección de correo electrónico | Descripción general de cada patrón |
|---|---|
En primer lugar, escriba el nombre de la cuentajan_stephens . . . | Una o varias letras en minúscula con guiones bajos |
Añada “@”jan_stephens@ . . . | Símbolo @ |
Añada el PSI jan_stephens@horizon . . . | Una o varias letras en minúscula sin guiones bajos |
Añada un puntojan_stephens@horizon. . . . | Carácter de punto |
Finalmente, añada el dominiojan_stephens@horizon.net | com o net |
Paso 2 — Expresar cada patrón como una expresión regular
En este paso, traduce los formatos generales derivados del paso 1 en segmentos de una expresión regular. Después, combina estos segmentos para formar la expresión completa.
La tabla que aparece a continuación muestra las descripciones de los formatos generalizados de cada patrón de caracteres en la columna de la izquierda. (Estos patrones se han extraído de la columna de la derecha de la tabla del paso 1). La segunda columna muestra los operadores o metacaracteres que representan el patrón de caracteres.
| Descripción de cada segmento | Patrón |
|---|---|
| Una o varias letras en minúscula con guiones bajos | [a-z_]+ |
Símbolo @ | @ |
| Una o varias letras en minúscula sin guiones bajos | [a-z]+ |
| Carácter de punto | \. |
com o net | (com|net) |
Si combina estos patrones en un vector de caracteres, obtendrá la expresión completa:
email = '[a-z_]+@[a-z]+\.(com|net)';
Paso 3 — Llamar a la función de búsqueda adecuada
En este paso, utiliza la expresión regular derivada del paso 2 para obtener una dirección de correo electrónico de uno de los amigos del grupo. Utilice la función regexp para llevar a cabo la búsqueda.
A continuación se muestra la lista de información de contacto que ha aparecido anteriormente en esta sección. El registro de cada persona ocupa una fila del arreglo de celdas contacts:
contacts = { ...
'Harry 287-625-7315 Columbus, OH hparker@hmail.com'; ...
'Janice 529-882-1759 Fresno, CA jan_stephens@horizon.net'; ...
'Mike 793-136-0975 Richmond, VA sue_and_mike@hmail.net'; ...
'Nadine 648-427-9947 Tampa, FL nadine_berry@horizon.net'; ...
'Jason 697-336-7728 Montrose, CO jason_blake@mymail.com'};
Esta es la expresión regular que representa una dirección de correo electrónico, tal y como se ha derivado en el paso 2:
email = '[a-z_]+@[a-z]+\.(com|net)';
Llame a la función regexp y pase la fila 2 del arreglo de celdas contacts y la expresión regular email. Este proceso devuelve la dirección de correo electrónico de Janice.
regexp(contacts{2}, email, 'match')
ans =
1×1 cell array
{'jan_stephens@horizon.net'}
MATLAB analiza un vector de caracteres de izquierda a derecha y "consume" el vector a medida que avanza. Si se encuentran caracteres que coincidan, regexp registra la ubicación y reanuda el análisis del vector de caracteres, comenzando justo después del final de la coincidencia más reciente.
Realice la misma llamada, pero esta vez para la quinta persona de la lista:
regexp(contacts{5}, email, 'match')
ans =
1×1 cell array
{'jason_blake@mymail.com'}
También puede buscar la dirección de correo electrónico de todas las personas de la lista utilizando el arreglo de celdas completo en el argumento de entrada:
regexp(contacts, email, 'match');
Operadores y caracteres
Las expresiones regulares pueden contener caracteres, metacaracteres, operadores, tokens e indicadores que especifican los patrones que deben coincidir, como se describe en estas secciones:
Metacaracteres
Los metacaracteres representan letras, intervalos de letras, dígitos y caracteres de espacio. Utilícelos para formar un patrón de caracteres generalizado.
Metacarácter | Descripción | Ejemplo |
|---|---|---|
| Cualquier carácter individual, incluido un espacio en blanco. |
|
| Cualquier carácter que se encuentre dentro de corchetes. Los siguientes caracteres se tratan de forma literal: |
|
| Cualquier carácter que no se encuentre dentro de corchetes. Los siguientes caracteres se tratan de forma literal: |
|
| Cualquier carácter que se encuentre en el intervalo de |
|
| Cualquier carácter alfabético, numérico o de guion bajo. Para los conjuntos de caracteres en inglés, |
|
| Cualquier carácter que no sea alfabético, numérico o de guion bajo. Para los conjuntos de caracteres en inglés, |
|
| Cualquier carácter de espacio en blanco, equivalente a |
|
| Cualquier carácter que no sea de espacio en blanco, equivalente a |
|
| Cualquier dígito numérico, equivalente a |
|
| Cualquier carácter que no sea un dígito, equivalente a |
|
| Carácter de valor octal |
|
| Carácter de valor hexadecimal |
|
Representación de caracteres
Operador | Descripción |
|---|---|
| Alarma (pitido) |
| Retroceso |
| Salto de impresión |
| Nueva línea |
| Retorno de carro |
| Tabulación horizontal |
| Tabulación vertical |
| Cualquier carácter con significado especial en las expresiones regulares que desea hacer que coincida de forma literal (por ejemplo, utilice |
Cuantificadores
Los cuantificadores especifican el número de veces que un patrón se debe producir en el texto que coincide.
Cuantificador | Número de veces que se produce la expresión | Ejemplo |
|---|---|---|
| 0 o más veces consecutivas. |
|
| 0 o 1 vez. |
|
| 1 o más veces consecutivas. |
|
| Al menos
|
|
| Al menos
|
|
| Exactamente Equivale a |
|
Los cuantificadores pueden aparecer en tres modos, según se describe en la tabla que aparece a continuación. q representa a cualquiera de los cuantificadores de la tabla anterior.
Modo | Descripción | Ejemplo |
|---|---|---|
| Expresión avariciosa: coincide con tantos caracteres como sea posible. | Dado el texto |
| Expresión perezosa: coincide con tan pocos caracteres como sea posible. | Dado el texto |
| Expresión posesiva: coincide con tantos caracteres como sea posible, pero no vuelve a buscar ninguna parte del texto. | Dado el texto |
Operadores de agrupación
Los operadores de agrupación le permiten capturar tokens, aplicar un operador a varios elementos o desactivar la búsqueda hacia atrás en un grupo específico.
Operador de agrupación | Descripción | Ejemplo |
|---|---|---|
| Agrupa los elementos de la expresión y captura tokens. |
|
| Agrupa, pero no captura tokens. |
Sin la agrupación, |
| Agrupa de forma atómica. No realiza búsquedas hacia atrás dentro del grupo para completar la coincidencia y no captura tokens. |
|
| Coincide con la expresión Si se produce una coincidencia con Puede incluir |
|
Delimitadores
Los delimitadores de una expresión coinciden con el comienzo o el final de una palabra o vector de caracteres.
Delimitador | Coincide con… | Ejemplo |
|---|---|---|
| El comienzo del texto de entrada. |
|
| El final del texto de entrada. |
|
| El principio de una palabra. |
|
| El final de una palabra. |
|
Aserciones de búsqueda de ancho cero
Las aserciones de búsqueda de ancho cero buscan patrones que preceden o siguen de forma inmediata a la coincidencia prevista, pero no forman parte de la coincidencia.
El puntero permanece en la ubicación actual y los caracteres que corresponden a la expresión test no se capturan ni descartan. Por lo tanto, las aserciones de búsqueda anticipada pueden coincidir con grupos de caracteres que se superponen.
Aserción de búsqueda de ancho cero | Descripción | Ejemplo |
|---|---|---|
| Busca caracteres hacia adelante que coinciden con |
|
| Busca caracteres hacia adelante que no coinciden con |
|
| Busca hacia atrás los caracteres que coinciden con |
|
| Busca hacia atrás los caracteres que no coinciden con |
|
Si especifica una aserción de búsqueda anticipada antes de una expresión, la operación equivale a un AND lógico.
Operación | Descripción | Ejemplo |
|---|---|---|
| Coincide con |
|
| Coincide con |
|
Para obtener más información, consulte Aserciones de búsqueda anticipada en expresiones regulares.
Operadores condicionales y lógicos
Los operadores condicionales y lógicos le permiten realizar una prueba del estado de una condición determinada y después utilizar la salida para determinar qué patrón, si existe, coincide después. Estos operadores admiten los operadores lógicos OR e if o las condiciones if/else. (Para las condiciones AND, consulte Aserciones de búsqueda de ancho cero).
Las condiciones pueden ser tokens, aserciones de búsqueda de ancho cero o expresiones dinámicas con la forma (?@cmd). Las expresiones dinámicas deben devolver un valor numérico o lógico.
Operador condicional | Descripción | Ejemplo |
|---|---|---|
| Coincide con la expresión Si se produce una coincidencia con |
|
| Si la condición |
|
| Si la condición |
|
Operadores de token
Los tokens son partes del texto que coincide que usted define englobando una parte de la expresión regular entre paréntesis. Puede referirse a un token mediante su secuencia en el texto (un token ordinal) o asignar nombres a los tokens para facilitar el mantenimiento del código y una salida legible.
Operador de token ordinal | Descripción | Ejemplo |
|---|---|---|
| Captura en un token los caracteres que se corresponden con la expresión delimitada. |
|
| Hace coincidir el |
|
| Si se encuentra el |
|
Operador de token denominado | Descripción | Ejemplo |
|---|---|---|
| Captura en un token denominado los caracteres que coinciden con la expresión delimitada. |
|
| Hace coincidir el token al que se hace referencia mediante |
|
| Si se encuentra el token denominado, coincide con |
|
Nota
Si una expresión tiene paréntesis anidados, MATLAB captura los tokens que corresponden con el conjunto de paréntesis exterior. Por ejemplo, dado el patrón de búsqueda '(and(y|rew))', MATLAB crea un token para 'andrew', pero no para 'y' o 'rew'.
Para obtener más información, consulte Tokens en expresiones regulares.
Expresiones dinámicas
Las expresiones dinámicas le permiten ejecutar un comando de MATLAB o una expresión regular para determinar el texto que debe coincidir.
Los paréntesis que delimitan expresiones dinámicas no crean un grupo de captura.
Operador | Descripción | Ejemplo |
|---|---|---|
| Analiza Al analizarse, |
|
| Ejecuta el comando de MATLAB representado por |
|
| Ejecuta el comando MATLAB representado por |
|
En expresiones dinámicas, utilice los siguientes operadores para definir los términos de sustitución.
Operador de sustitución | Descripción |
|---|---|
| Parte del texto de entrada que actualmente forma parte de una coincidencia |
| Parte del texto de entrada que precede a la coincidencia actual |
| Parte del texto de entrada que sigue a la coincidencia actual (utilice |
|
|
| Token denominado |
| Resultado devuelto cuando MATLAB ejecuta el comando, |
Para obtener más información, consulte Expresiones regulares dinámicas.
Comentarios
El operador comment le permite insertar comentarios en el código para hacerlo más fácil de mantener. MATLAB ignora el texto del comentario cuando coincide con el texto de entrada.
Caracteres | Descripción | Ejemplo |
|---|---|---|
(?#comment) | Inserta un comentario en la expresión regular. El texto del comentario se ignora cuando coincide con la entrada. |
|
Indicadores de búsqueda
Los indicadores de búsqueda modifican el comportamiento para las expresiones que coinciden.
Indicador | Descripción |
|---|---|
(?-i) | Hace coincidir mayúsculas y minúsculas (opción predeterminada para |
(?i) | No hace coincidir mayúsculas y minúsculas (opción predeterminada para |
(?s) | Hace coincidir el punto ( |
(?-s) | Hace coincidir el punto en el patrón con cualquier otro carácter que no sea un carácter de línea nueva. |
(?-m) | Hace coincidir los metacaracteres |
(?m) | Hace coincidir los metacaracteres |
(?-x) | Incluye los caracteres de espacio y los comentarios cuando coinciden (opción predeterminada). |
(?x) | Ignora los caracteres de espacio y los comentarios cuando coinciden. Utiliza |
La expresión que modifica el indicador puede aparecer antes de los paréntesis, como
(?i)\w*
o dentro de los paréntesis y separada del indicador con dos puntos (:), como
(?i:\w*)
La última sintaxis le permite cambiar el comportamiento para una parte de una expresión mayor.
Consulte también
regexp | regexpi | regexprep | regexptranslate | pattern