concentrationIndices
Compute ad-hoc concentration indices for a portfolio
Description
ci = concentrationIndices(PortfolioData)concentrationIndices function
supports the following indices:
CR — Concentration ratio
Deciles — Deciles of the portfolio weights distribution
Gini — Gini coefficient
HH — Herfindahl-Hirschman index
HK — Hannah-Kay index
HT — Hall-Tideman index
TE — Theil entropy index
[ adds
optional name-value pair arguments. ci,Lorenz]
= concentrationIndices(___,Name,Value)
Examples
Compute the concentration indices for a credit portfolio using a portfolio that is described by its exposures. The exposures at default are stored in the EAD array.
Load the CreditPortfolioData.mat file that contains EAD used for the PortfolioData input argument.
load CreditPortfolioData.mat
ci = concentrationIndices(EAD)ci=1×8 table
ID CR Deciles Gini HH HK HT TE
___________ ________ _________________________________________________________________________________________________________________________ _______ ________ ________ ________ _______
"Portfolio" 0.058745 0 0.01118 0.026911 0.04605 0.072783 0.12318 0.18735 0.26993 0.41164 0.61058 1 0.55751 0.023919 0.013363 0.022599 0.53485
Use the CRIndex optional input to obtain the concentration ratios for the tenth and twentieth largest exposures. In the output, the CR column becomes a vector, with one value for each requested index.
Load the CreditPortfolioData.mat file that contains the EAD used for the PortfolioData input argument.
load CreditPortfolioData.mat ci = concentrationIndices(EAD,'CRIndex',[10 20])
ci=1×8 table
ID CR Deciles Gini HH HK HT TE
___________ __________________ _________________________________________________________________________________________________________________________ _______ ________ ________ ________ _______
"Portfolio" 0.38942 0.58836 0 0.01118 0.026911 0.04605 0.072783 0.12318 0.18735 0.26993 0.41164 0.61058 1 0.55751 0.023919 0.013363 0.022599 0.53485
Use the HKAlpha optional input to set the alpha parameter for the Hannah-Kay (HK) index. Use a vector of alpha values to compute the HK index for multiple parameter values. In the output, the HK column becomes a vector, with one value for each requested alpha value.
Load the CreditPortfolioData.mat file that contains EAD used for the PortfolioData input argument.
load CreditPortfolioData.mat ci = concentrationIndices(EAD,'HKAlpha',[0.5 3])
ci=1×8 table
ID CR Deciles Gini HH HK HT TE
___________ ________ _________________________________________________________________________________________________________________________ _______ ________ ____________________ ________ _______
"Portfolio" 0.058745 0 0.01118 0.026911 0.04605 0.072783 0.12318 0.18735 0.26993 0.41164 0.61058 1 0.55751 0.023919 0.013363 0.029344 0.022599 0.53485
Compare the concentration measures using an ID optional argument for a fully diversified portfolio and a fully concentrated portfolio.
ciD = concentrationIndices([1 1 1 1 1],'ID','Fully diversified'); ciC = concentrationIndices([0 0 0 0 5],'ID','Fully concentrated'); disp([ciD;ciC])
ID CR Deciles Gini HH HK HT TE
____________________ ___ _______________________________________________________________________ ____ ___ ___ ___ ___________
"Fully diversified" 0.2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.2 0.2 -2.2204e-16
"Fully concentrated" 1 0 0 0 0 0 0 0 0 0 0.5 1 0.8 1 1 1 1.6094
Use the ScaleIndices optional input to scale the index values of Gini, HH, HK, HT, and TE. The range of ScaleIndices is from 0 through 1, independent of the number of loans.
ciDU = concentrationIndices([1 1 1 1 1],'ID','Diversified, unscaled'); ciDS = concentrationIndices([1 1 1 1 1],'ID','Diversified, scaled','ScaleIndices',true); ciCU = concentrationIndices([0 0 0 0 5],'ID','Concentrated, unscaled'); ciCS = concentrationIndices([0 0 0 0 5],'ID','Concentrated, scaled','ScaleIndices',true); disp([ciDU;ciDS;ciCU;ciCS])
ID CR Deciles Gini HH HK HT TE
________________________ ___ _______________________________________________________________________ ____ __________ ___________ ___________ ___________
"Diversified, unscaled" 0.2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.2 0.2 -2.2204e-16
"Diversified, scaled" 0.2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 3.4694e-17 -3.4694e-17 -6.9389e-17 -1.3796e-16
"Concentrated, unscaled" 1 0 0 0 0 0 0 0 0 0 0.5 1 0.8 1 1 1 1.6094
"Concentrated, scaled" 1 0 0 0 0 0 0 0 0 0 0.5 1 1 1 1 1 1
Load the CreditPortfolioData.mat file that contains EAD used for the PortfolioData input argument.
load CreditPortfolioData.mat
P = EAD;
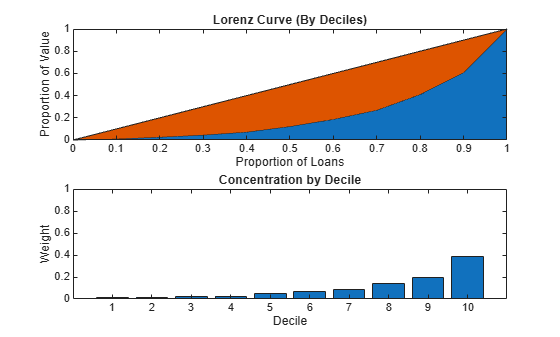
ci = concentrationIndices(P);Visualize an approximate Lorenz curve using the deciles information and also the concentration at the decile level.
Proportion = 0:0.1:1; figure; subplot(2,1,1) area(Proportion',[ci.Deciles' Proportion'-ci.Deciles']) axis([0 1 0 1]) title('Lorenz Curve (By Deciles)') xlabel('Proportion of Loans') ylabel('Proportion of Value') subplot(2,1,2) bar(diff(ci.Deciles)) axis([0 11 0 1]) title('Concentration by Decile') xlabel('Decile') ylabel('Weight')
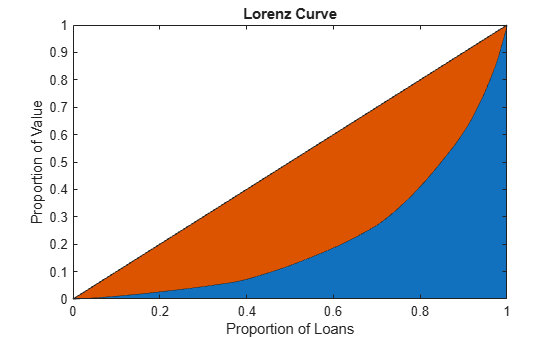
Load the CreditPortfolioData.mat file that contains the EAD used for the PortfolioData input argument. The optional output Lorenz contains the data for the exact Lorenz curve.
load CreditPortfolioData.mat P = EAD; [~,Lorenz] = concentrationIndices(P); figure; area(Lorenz.ProportionLoans,[Lorenz.ProportionValue Lorenz.ProportionLoans-Lorenz.ProportionValue]) axis([0 1 0 1]) title('Lorenz Curve') xlabel('Proportion of Loans') ylabel('Proportion of Value')
Input Arguments
Name-Value Arguments
Output Arguments
More About
The Lorenz curve is a visualization of the cumulative proportion of portfolio value (or cumulative portfolio weights) against the cumulative proportion of loans.
The cumulative proportion of loans (p) is defined by:
The cumulative proportion of portfolio value L is defined as:
The Lorenz curve is a plot of L versus p, or the cumulative proportion of portfolio value versus cumulative proportion of the number of loans (sorted from smallest to largest).
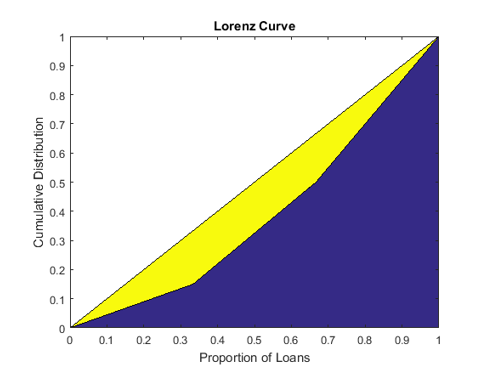
The diagonal line is indicated in the same plot because it represents the curve for the portfolio with the least possible concentration (all loans with the same weight). The area between the diagonal and the Lorenz curve is a visual representation of the Gini coefficient, which is another concentration measure.
References
[1] Basel Committee on Banking Supervision. "Studies on Credit Risk Concentration". Working paper no. 15. November, 2006.
[2] Calabrese, R., and F. Porro. "Single-name concentration risk in credit portfolios: a comparison of concentration indices." working paper 201214, Geary Institute, University College, Dublin, May, 2012.
[3] Lütkebohmert, E. Concentration Risk in Credit Portfolios. Springer, 2009.
Version History
Introduced in R2017a