padv.pipeline.GitHubOptions
Options for generating pipeline files for GitHub Actions
Description
Add-On Required: This feature requires the CI Support Package for Simulink add-on.
Use the padv.pipeline.GitHubOptions object to specify options
for generating GitHub® pipeline files. To generate pipeline files, pass the object to the
padv.pipeline.generatePipeline function.
Creation
Syntax
Description
options = padv.pipeline.GitHubOptions(GeneratorVersion=version)
Use
GeneratorVersion=1if you need to maintain compatibility with existing pipelines.Use
GeneratorVersion=2for new pipelines or when upgrading your pipeline setup.
options = padv.pipeline.GitHubOptions(___,PropertyName=Value)
Some properties are available in Both Versions, while other properties are specific to Version 1 Only or Version 2 Only.
Input Arguments
Properties
Both Versions
GitHub runner labels, specified as a string.
The labels determine which GitHub runner can execute the job. For more information, see the GitHub documentation for Choosing the runner for a job.
Example:
"Linux"
Data Types: string
Specify whether GitHub uses MATLAB Actions to run tasks, specified as either a numeric or logical:
0(false) — The pipeline runs tasks using shell commands.1(true) — The pipeline runs tasks using the Run MATLAB Command action and the pipeline generator ignores the propertiesMatlabLaunchCmdandMatlabStartupOptions
Note
If you dry run tasks by setting DryRun to
true in RunprocessCommandOptions, the
pipeline does not use the plugin and runs tasks using shell commands.
Data Types: logical
Command to start MATLAB program, specified as a string.
If you use a custom command to launch MATLAB on your machine, make sure to set this property. The default value of this
property is "matlab", which assumes MATLAB is available in the PATH environment variable for your
system and runs the default MATLAB executable.
Example: "C:\Program
Files\MATLAB\R2024b\bin\matlab.exe"
Data Types: string
Command-line startup options for MATLAB, specified as a string.
Use this property to specify the command-line startup options that the generated
pipeline file uses when starting the MATLAB program. By default, the pipeline generator launches MATLAB using the -batch option. If you need to run MATLAB without the -batch option, specify the property
AddBatchStartupOption as false.
Some MATLAB code, including some built-in tasks, can only run successfully if a display is available for your machine. For more information, see Set Up Virtual Display Machines Without Displays.
Example: "-nodesktop -logfile mylogfile.log"
Data Types: string
Specify whether to open MATLAB using -batch startup option, specified as a numeric or
logical 0 (false) or 1
(true).
If you need to launch MATLAB with options that are not compatible with -batch,
specify AddBatchStartupOption as false.
Data Types: logical
Checkout Git submodules at the beginning of each pipeline stage, specified as either:
"false""true""recursive"
This property uses the GitHub Action checkout@v4. For information about the submodule
input values, see the GitHub documentation for Checkout
submodules.
Data Types: string
Number of stages and grouping of tasks in CI pipeline, specified as either:
padv.pipeline.Architecture.SingleStage— The pipeline has a single stage, named Runprocess, that runs each of the tasks in the process.
padv.pipeline.Architecture.SerialStages— The pipeline has one stage for each task iteration in the process.
padv.pipeline.Architecture.SerialStagesGroupPerTask— The pipeline has one stage for each task in the process.
padv.pipeline.Architecture.IndependentModelPipelines— The pipeline contains parallel, downstream pipelines for each model. Each downstream pipeline independently runs the tasks associated with that model. To make sure the jobs run in parallel, make sure that you either have multiple build agents available or configure your build agent to run parallel jobs.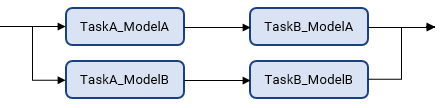
Note
For Pipeline Generator Version 2, if you decide
to use the IndependentModelPipelines architecture to generate code
and perform code analysis tasks in parallel, you must either switch to using the
template parallel process model or update your existing process as shown in Considerations for Parallel Code Generation. These updates allow
the tasks in your pipeline to properly handle shared utilities and code generated
across parallel jobs.
Example: padv.pipeline.Architecture.IndependentModelPipelines
Example: "IndependentModelPipelines"
Options for runprocess command, specified as a
padv.pipeline.RunProcessOptions object.
The object padv.pipeline.RunProcessOptions has properties for each of the name-value
arguments in the runprocess
function, except for the Scope arguments
Tasks, Process,
Subprocesses, and FilterArtifact.
Note
The GitHub workflow automatically dry runs tasks using shell commands if you set
DryRuntotruein RunprocessCommandOptions.GenerateJUnitForProcessis set tofalseby default inpadv.pipeline.RunProcessOptions. Previously, this property wastrueby default.The
GenerateJUnitForProcessproperty inpadv.pipeline.GitHubOptionswill be removed in a future release. Make sure to specify theGenerateJUnitForProcessproperty inpadv.pipeline.RunProcessOptionsto the value that you want the pipeline to use.
Example: padv.pipeline.RunProcessOptions()
Stop running pipeline after stage fails, specified as either:
1(true) — Stop the pipeline immediately when any stage fails.0(false) — Allow the pipeline to continue running subsequent stages, even if a previous stage fails.
If you use the built-in tasks
padv.builtin.task.RunTestsPerModel or
padv.builtin.task.RunTestsPerTestCase to run tests, keep
StopOnStageFailure set to false. This prevents
the pipeline from skipping the padv.builtin.task.MergeTestResults task if
a test stage fails.
Data Types: logical
File name of generated pipeline file, specified as a string.
By default, the generated pipeline file generates into the subfolder derived > pipeline, relative to the project root. To change where the pipeline file
generates, specify GeneratedPipelineDirectory.
Example: "padv_generated_pipeline_file"
Data Types: string
Location where the generated pipeline file generates, specified as a string.
This property defines the directory where the generated pipeline file generates.
By default, the generated pipeline file is named
"simulink_pipeline.yml". To change the name of the generated
pipeline file, specify the GeneratedYMLFileName property.
Example: fullfile("derived","pipeline","test")
Data Types: string
When to collect build artifacts, specified as:
"never",0, orfalse— Never collect artifacts"on_success"— Only collect artifacts when the pipeline succeeds"on_failure"— Only collect artifacts when the pipeline fails"always",1, ortrue— Always collect artifacts
Data Types: logical | string
Name of ZIP file for job artifacts, specified as a string.
Example: "my_job_artifacts.zip"
Data Types: string
Generate Process Advisor build report, specified as a numeric or logical
1 (true) or 0
(false).
Data Types: logical
File format for the generated report, specified as one of these values:
"pdf"— PDF file"html"— HTML report, packaged as a zipped file that contains the HTML file, images, style sheet, and JavaScript® files of the report"html-file"— HTML report, consisting of a single HTML file that contains the text, style sheets, JavaScript, and base64-encoded images of the report"docx"— Microsoft® Word document
Name and path of generated report, specified as a string array.
By default, the report path uses a relative path to the project root and the
pipeline generator generates a report
ProcessAdvisorReport.pdf.
As a recommended practice, set the ReportPath to a sub-folder
within the project root. CI pipelines cannot archive files located in the project root
itself.
Example: "$PROJECTROOT$/PA_Results/Report/ProcessAdvisorReport"
Data Types: string
Enable integration with OpenTelemetry to view detailed pipeline timing and execution data, specified as a
numeric or logical true (1) or
false (0).
Before you enable the OpenTelemetry integration, you must install the OpenTelemetry-MATLAB package and set up OpenTelemetry, as shown in Collect Detailed Execution Data with OpenTelemetry Integration.
Data Types: logical
Version 1 Only
The pipeline generator does not use this property.
Data Types: logical
Enable pipeline caching to support incremental builds in CI, specified as a numeric
or logical 0 (false) or 1
(true).
For Pipeline Generator Version 1, generated
pipelines use caching by default to help the
performance of incremental builds in CI.
However, if a generated pipeline has persistent conflicts and generates errors when
merging artifact information from parallel jobs, you can disable pipeline caching by
specifying EnablePipelineCaching as 0
(false). Disabling pipeline caching increases build times, but can
help avoid merge conflicts.
Pipeline Generator Version 2 ignores this property.
Data Types: logical
Path to MATLAB installation location, specified as a string.
For Pipeline Generator Version 1, make sure the path that you specify uses the MATLAB root folder location and file separators for the operating system of your build agent.
Pipeline Generator Version 2 ignores this property.
For Pipeline Generator Version 2, make sure MATLAB is available on the system PATH so the build agent can
access MATLAB.
Example:
"C:\Program Files\MATLAB\R2025b\bin"
Example:
"/usr/local/MATLAB/R2025b/bin"
Example:
"/Applications/MATLAB_R2025b.app/bin"
Data Types: string
How many days GitHub stores workflow artifacts, specified as a string.
This property corresponds to the job keyword "retention-days" in
GitHub. After the specified number of retention days, the artifacts expire and
GitHub deletes the artifacts. For more information, see the GitHub documentation for Configuring a custom artifact retention period.
Pipeline Generator Version 2 ignores this property and instead uses the default organization retention policy. For more information, see the GitHub documentation for Artifact and log retention policy.
Example: RetentionDays = "90"
Data Types: string
Shell environment GitHub uses to launch MATLAB, specified as one of these values:
"bash"— UNIX® shell script"pwsh"— PowerShell Core script
Pipeline Generator Version 2 ignores this property and instead:
If the build agent is a UNIX machine, the GitHub pipeline uses a shell script.
If the build agent is not a UNIX machine, the GitHub pipeline uses a Windows® batch script.
Data Types: string
Version 2 Only
Path to root folder of support packages on build agent, specified as a string.
To help identify the path, you can run the function matlabshared.supportpkg.getSupportPackageRoot on the build agent.
Note
If you specify this property, you must also specify the variable
MW_SUPPORT_PACKAGE_ROOT in your CI system.
Pipeline Generator Version 1 does not support this property.
Example: "C:\\ProgramData\\MATLAB\\SupportPackages\\R2025a"
Data Types: string
Relative path from repository root to project root folder, specified as a string.
If your project root folder is at the repository root, leave
RelativeProjectPath as an empty string
"".
If your project is located in a subfolder, set
RelativeProjectPath to the subfolder path relative to the
repository root. The value of RelativeProjectPath must be the
portion of the project path after the repository root and must be a valid sub-path
within the full path to the project root folder. The path must end with the file
separator /.
For example:
| Situation | Project Root Folder | Valid RelativeProjectPath |
|---|---|---|
| Project in repository repo | "/home/user/repo-root/" | "" |
| Project in subfolder | "/home/user/repo-root/src/myproject/" | "src/myproject/" |
Note
If you specify this property, you must also specify the variable
MW_RELATIVE_PROJECT_PATH in your CI system. The path must end
with the file separator /.
Pipeline Generator Version 1 does not support this property.
Example: "src/myproject/"
Example: "subfolder/src/myproject/"
Data Types: string
Name of remote build cache directory, specified as a string.
The pipeline generator uses the directory to store pipeline artifact caches on the
remote build cache service. The artifacts and sub-folders are inside a root folder. You
can specify the name of the root folder by using the
RemoteBuildCacheName property.
For example, inside your artifact storage location, the pipeline generator can generate a folder structure such as:
<RemoteBuildCacheName>/
└── branchName/
└── folderForEachRunId/
└── br_NameForPipelineBranch/
├── Project/
├── PA_Results/
├── derived/
│ └── artifacts.dmr
├── ir_dag.json
├── simulink_pipeline
└── __lastSuccessfulRunId__As a best practice, use a unique name for each pipeline and project to avoid conflicts between different pipelines.
Pipeline Generator Version 1 does not support this property.
Example: "GitHub MATLAB Workflow"
Data Types: string
Artifact storage approach, specified as one of the values in this table. The artifact service mode determines how the pipeline stores and retrieves artifact caches. Depending on which approach you choose, you must also specify the additional properties and credentials in the Requirements column.
| Value | Description | Requirements |
|---|---|---|
"network" | Store artifacts on a network drive | Set the |
"jfrog" | Store artifacts in a JFrog Artifactory repository | Set both the In your
CI system, save your JFrog API token as a secret with the ID
|
"s3" | Store artifacts in an Amazon S3™ bucket | Set both the In
your CI system, save your Amazon S3 access key as a secret with the ID
|
"azure_blob" | Store artifacts in an Azure® Blob Storage container | Set the In your CI system, save your Azure storage account connection string as a secret with the ID
|
Pipeline Generator Version 1 does not support this property.
Path to network storage location for storing artifacts when
ArtifactServiceMode is "network", specified as
a string.
Specify the path to a shared network location that all agents running the pipeline can access.
Pipeline Generator Version 1 does not support this property.
Example: "/artifactManagement/cacheStorage"
Data Types: string
URL of JFrog Artifactory server for storing artifacts when
ArtifactServiceMode is "jfrog", specified as a
string.
Pipeline Generator Version 1 does not support this property.
Example: "http://localhost:8082/artifactory"
Data Types: string
Name of JFrog Artifactory repository for storing artifacts when
ArtifactServiceMode is "jfrog", specified as a
string.
Pipeline Generator Version 1 does not support this property.
Example: "example-repo-local"
Data Types: string
Name of Amazon S3 bucket for storing artifacts when ArtifactServiceMode
is "s3", specified as a string.
Pipeline Generator Version 1 does not support this property.
Example: "my-artifacts-bucket"
Data Types: string
AWS access key ID for storing artifacts in an Amazon S3 bucket when ArtifactServiceMode is
"s3", specified as a string.
Pipeline Generator Version 1 does not support this property.
Example: "AKIAIOSFODNN7EXAMPLE"
Data Types: string
Name of Azure Blob Storage container for storing artifacts when
ArtifactServiceMode is "azure_blob", specified
as a string.
You can only specify a single container name, not multiple container names.
Pipeline Generator Version 1 does not support this property.
Example: "mycontainer"
Data Types: string
Execution environment of runner, specified as either:
"default"— Runs tasks directly on the host machine without containerization."container"— Runs tasks inside a containerized environment, such as a Docker® container. Specify the container by using theImageTagproperty.The container does not use MATLAB actions. Make sure to specify the
UseMatlabPlugin,MatlabLaunchCmd,MatlabStartupOptions, andAddBatchStartupOptionproperties as required by your setup. For example:op = padv.pipeline.GitHubOptions(GeneratorVersion=2); % Docker image settings op.UseMatlabPlugin = false; op.MatlabLaunchCmd = "xvfb-run -a matlab -batch"; op.MatlabStartupOptions = ""; op.AddBatchStartupOption = false;
Pipeline Generator Version 1 does not support this property.
Full name of the container image that the generated pipeline uses when
RunnerType is "container", specified as a
string.
The image must be an OCI-compliant image, such as a Docker image.
Pipeline Generator Version 1 does not support this property.
Example: "mycompany/pipeline-runner:latest"
Data Types: string
Path to pipeline template file, specified as a string.
The generated pipeline files look for the required supporting template files at this path location.
Pipeline Generator Version 1 does not support this property.
Data Types: string
Branches to check for cached build artifacts, specified as a string.
To support incremental builds, the pipeline generator attempts
to restore the cache from the last successful run on the same
branch. If no cache is available, the pipeline checks for
cached build artifacts on the branches that you specify. By default, the fallback branch is
main, but you can specify multiple fallback branches and the pipeline
checks each one in order. If the pipeline generator does not find a cache on the specified
branches, the pipeline runs a full build, executing each task in the process without skipping
tasks. For more information, see How Pipeline Generation Works.
Pipeline Generator Version 1 does not support this property.
Example: ["develop"]
Example: ["main","develop"]
Data Types: string