Create Simple Preprocessing Function
This example shows how to create a function which cleans and preprocesses text data for analysis using the Preprocess Text Data Live Editor task.
Text data can be large and can contain lots of noise which negatively affects statistical analysis. For example, text data can contain the following:
Variations in case, for example "new" and "New"
Variations in word forms, for example "walk" and "walking"
Words which add noise, for example "stop words" such as "the" and "of"
Punctuation and special characters
HTML and XML tags
These word clouds illustrate word frequency analysis applied to some raw text data from factory reports, and a preprocessed version of the same text data.

Most workflows require a preprocessing function to easily prepare different collections of text data in the same way. For example, when you train a model, you can use the same function to preprocess the training data and new data using the same steps.
You can interactively preprocess text data using the Preprocess Text Data Live Editor task and visualize the results. This example uses the Preprocess Text Data Live Editor task to generate code that preprocesses text data and creates a function that you can reuse. For more information on Live Editor tasks, see Add Interactive Tasks to a Live Script.
First, load the factory reports data. The data contains textual descriptions of factory failure events.
tbl = readtable("factoryReports.csv")
Open the Preprocess Text Data Live Editor task. To open the task, begin typing the task name and select Preprocess Text Data from the suggested command completions. Alternatively, on the Live Editor tab, select Task > Preprocess Text Data.

Preprocess the text using these options:
Select
tblas the input data and select the table variableDescription.Tokenize the text using automatic language detection.
To improve lemmatization, add part-of-speech tags to the token details.
Normalize the words using lemmatization.
Remove words with fewer than 3 characters or more than 14 characters.
Remove stop words.
Erase punctuation.
Display the preprocessed text in a word cloud.
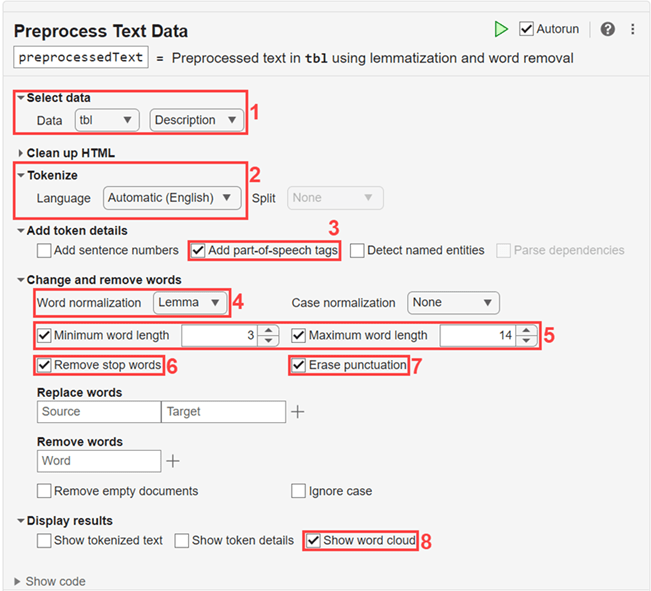

The Preprocess Text Data Live Editor task generates code in your live script. The generated code reflects the options that you select and includes code to generate the display. To see the generated code, click Show code at the bottom of the task parameter area. The task expands to display the generated code.
By default, the generated code uses preprocessedText as the name of the output variable returned to the MATLAB® workspace. To specify a different output variable name, enter a new name in the summary line at the top of the task.
![]()
To reuse the same steps in your code, create a function that takes as input the text data and
outputs the preprocessed text data. You can include the function at the end of a script or
as a separate file. The preprocessTextData function listed at the end of
the example, uses the code generated by the Preprocess Text
Data Live Editor task.
To use the function, specify the table as input to the preprocessTextData function.
documents = preprocessTextData(tbl);
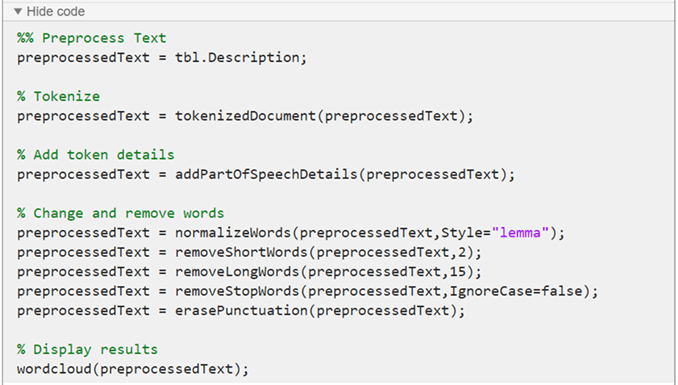
Preprocessing Function
The preprocessTextData function uses the code generated by the
Preprocess Text Data Live Editor task. The function
takes as input the table tbl and returns the preprocessed text
preprocessedText. The function performs these steps:
Extract the text data from the
Descriptionvariable of the input table.Tokenize the text using
tokenizedDocument.Add part-of-speech details using
addPartOfSpeechDetails.Lemmatize the words using
normalizeWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.Remove stop words (such as "and", "of", and "the") using
removeStopWords.Erase punctuation using
erasePunctuation.
function preprocessedText = preprocessTextData(tbl) %% Preprocess Text preprocessedText = tbl.Description; % Tokenize preprocessedText = tokenizedDocument(preprocessedText); % Add token details preprocessedText = addPartOfSpeechDetails(preprocessedText); % Change and remove words preprocessedText = normalizeWords(preprocessedText,Style="lemma"); preprocessedText = removeShortWords(preprocessedText,2); preprocessedText = removeLongWords(preprocessedText,15); preprocessedText = removeStopWords(preprocessedText,IgnoreCase=false); preprocessedText = erasePunctuation(preprocessedText); end
For an example showing a more detailed workflow, see Preprocess Text Data in Live Editor. For next steps in text analytics, you can try creating a classification model or analyze the data using topic models. For examples, see Create Simple Text Model for Classification and Analyze Text Data Using Topic Models.
See Also
Preprocess
Text Data | tokenizedDocument | erasePunctuation | removeStopWords | removeShortWords | removeLongWords | normalizeWords | addPartOfSpeechDetails