Get Started with Topic Modeling
This example shows how to fit a topic model to text data and visualize the topics.
A Latent Dirichlet Allocation (LDA) model is a topic model which discovers underlying topics in a collection of documents. Topics, characterized by distributions of words, correspond to groups of commonly co-occurring words. LDA is an unsupervised topic model which means that it does not require labeled data.
Load and Extract Text Data
Load the example data. The file factoryReports.csv contains factory reports, including a text description and categorical labels for each event.
Import the data using the readtable function and extract the text data from the Description column.
filename = "factoryReports.csv"; data = readtable(filename,'TextType','string'); textData = data.Description;
Prepare Text Data for Analysis
Tokenize and preprocess the text data and create a bag-of-words model.
Tokenize the text.
documents = tokenizedDocument(textData);
To improve the model fit, remove the punctuation and the stop words (words like "and", "of", and "the") from the documents.
documents = removeStopWords(documents); documents = erasePunctuation(documents);
Create a bag-of-words model.
bag = bagOfWords(documents);
Fit LDA Model
Fit an LDA model with seven topics using the fitlda function. To suppress the verbose output, set the 'Verbose' option to 0.
numTopics = 7;
mdl = fitlda(bag,numTopics,'Verbose',0);Visualize Topics
Visualize the first four topics using word clouds.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic " + topicIdx) end
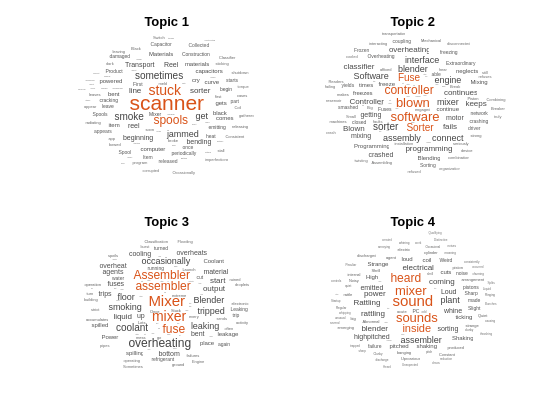
For next steps in text analytics, you can try improving the model fit by using different preprocessing steps and visualizing the topic mixtures. For an example, see Analyze Text Data Using Topic Models.
See Also
removeStopWords | tokenizedDocument | erasePunctuation | bagOfWords | fitlda | wordcloud