Ajuste polinomial de curvas
Este ejemplo muestra cómo ajustar polinomios hasta de sexto grado a datos de censo usando Curve Fitting Toolbox™. También muestra cómo ajustar una ecuación exponencial de un solo término y compararla con los modelos polinomiales.
Los sucesivos pasos muestran cómo:
Cargar datos y crear ajustes usando distintos modelos de bibliotecas.
Buscar el mejor ajuste comparando los resultados de los ajustes, tanto gráficos como numéricos, incluidos los coeficientes ajustados y los valores estadísticos de bondad de ajuste.
Cargar y representar los datos
Los datos para este ejemplo son el archivo census.mat.
load censusEl área de trabajo contiene dos variables nuevas:
cdatees un vector columna que contiene los años 1790 a 1990 en incrementos de 10 años.popes un vector columna con las cifras de población estadounidense correspondientes a cada año decdate.
whos cdate pop
Name Size Bytes Class Attributes cdate 21x1 168 double pop 21x1 168 double
plot(cdate,pop,'o')
Crear y representar una curva cuadrática
Use la función fit para ajustar un polinomio a los datos. Especifique un polinomio cuadrático, o de segundo grado, mediante 'poly2'. El primer resultado de fit es el polinomio y el segundo resultado (gof) contiene los valores estadísticos de bondad de ajuste que examinará más adelante.
[population2,gof] = fit(cdate,pop,'poly2');Para representar el ajuste, use la función plot. Añada una leyenda en la esquina superior izquierda.
plot(population2,cdate,pop); legend('Location','NorthWest');
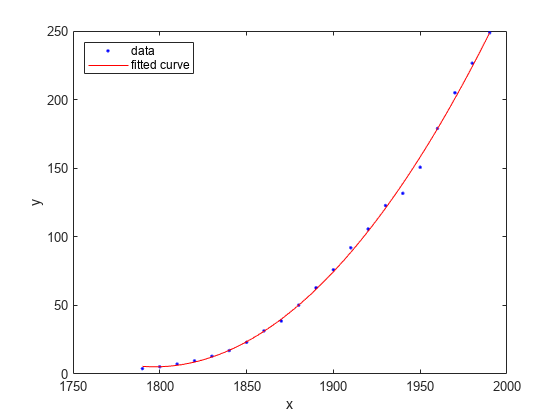
Crear y representar una selección de polinomios
Para ajustar polinomios de distintos grados, modifique el tipo de ajuste; por ejemplo, para un polinomio cúbico, o de tercer grado, use 'poly3'. La escala de los datos de entrada cdate es bastante grande, por lo que obtendrá mejores resultados si centra y cambia la escala de los datos. Para ello, use la función 'Normalize'.
population3 = fit(cdate,pop,'poly3','Normalize','on'); population4 = fit(cdate,pop,'poly4','Normalize','on'); population5 = fit(cdate,pop,'poly5','Normalize','on'); population6 = fit(cdate,pop,'poly6','Normalize','on');
Un modelo sencillo de crecimiento poblacional indica que una ecuación exponencial debería ajustarse bien a estos datos de censo. Para ajustar un modelo exponencial de un solo término, use 'exp1' como fittype.
populationExp = fit(cdate,pop,'exp1');Represente todos los ajustes a la vez y añada una leyenda relevante en la esquina superior izquierda de la gráfica.
hold on plot(population3,'b'); plot(population4,'g'); plot(population5,'m'); plot(population6,'b--'); plot(populationExp,'r--'); hold off legend('cdate v pop','poly2','poly3','poly4','poly5','poly6','exp1', ... 'Location','NorthWest');

Representar los valores residuales para evaluar el ajuste
Para representar los valores residuales, elija 'residuals' como tipo de gráfica en la función plot.
plot(population2,cdate,pop,'residuals');
Todos los ajustes y los valores residuales de las ecuaciones polinomiales se parecen, por lo que resulta difícil elegir el mejor.
Si los valores residuales muestran un patrón sistemático, es una clara indicación de que el modelo no se ajusta bien a los datos.
plot(populationExp,cdate,pop,'residuals');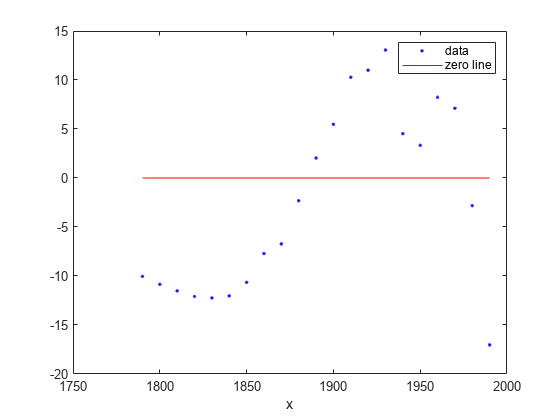
El ajuste y los valores residuales de la ecuación exponencial de un solo término indican que, en conjunto, no se ajusta bien. Por lo tanto, es una mala opción y puede eliminar el ajuste exponencial de la lista de posibles mejores ajustes.
Estudiar los ajustes más allá del rango de datos
Estudie el comportamiento de los ajustes hasta el año 2050. El objetivo de ajustar los datos del censo es extrapolar el mejor ajuste para predecir valores futuros de población.
De forma predeterminada, el ajuste se representa sobre el rango de datos. Para representar un ajuste sobre un rango distinto, establezca los límites del eje x antes de representar el ajuste. Por ejemplo, para ver los valores del ajuste extrapolados, establezca el límite superior del eje x en 2050.
plot(cdate,pop,'o'); xlim([1900, 2050]); hold on plot(population6); hold off
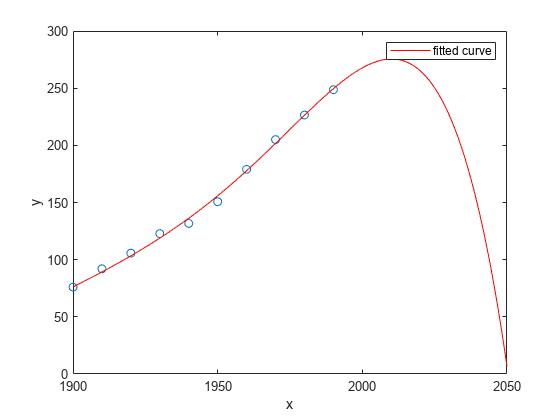
Estudie la gráfica. El comportamiento del ajuste polinomial de sexto grado más allá del rango de datos lo convierte en una mala opción para extrapolar, por lo que puede rechazar este ajuste.
Representar los intervalos de predicción
Para representar los intervalos de predicción, utilice 'predobs' o 'predfun' como tipo de gráfica. Por ejemplo, para ver los límites de predicción del polinomio de quinto grado de una nueva observación hasta el año 2050:
plot(cdate,pop,'o'); xlim([1900,2050]) hold on plot(population5,'predobs'); hold off
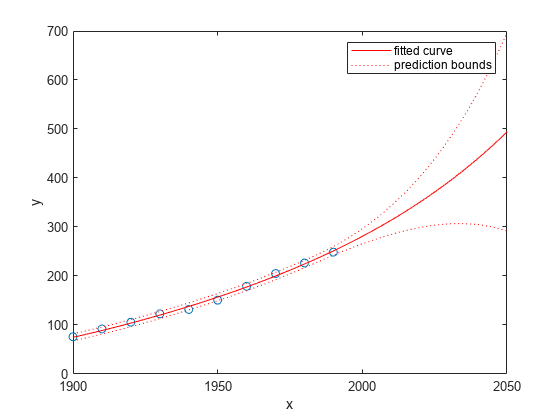
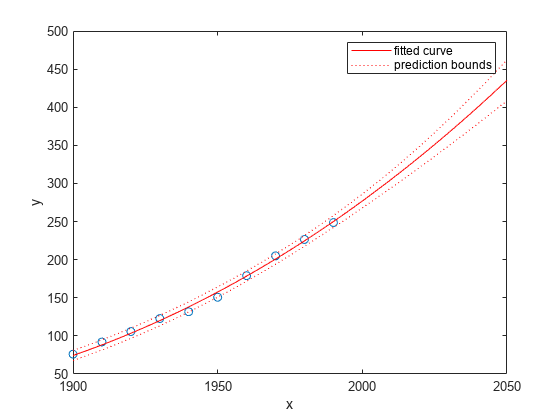
Represente los intervalos de predicción del polinomio cúbico hasta el año 2050:
plot(cdate,pop,'o'); xlim([1900,2050]) hold on plot(population3,'predobs') hold off
Examinar estadísticas de bondad de ajuste
La estructura gof muestra los valores estadísticos de bondad de ajuste del ajuste 'poly2'. Al crear el ajuste 'poly2' mediante la función fit en un paso anterior, especificó el argumento de salida gof.
gof
gof = struct with fields:
sse: 159.0293
rsquare: 0.9987
dfe: 18
adjrsquare: 0.9986
rmse: 2.9724
Estudie los valores estadísticos de la suma de cuadrados de los errores (SSE, por su sigla en inglés) y el R-cuadrado ajustado para ayudar a determinar cuál es el mejor ajuste. El valor estadístico SSE es el error de mínimos cuadrados del ajuste, y cuanto más próximo a cero sea su valor mejor será el ajuste. El valor estadístico del R-cuadrado ajustado es normalmente el mejor indicador de la calidad del ajuste cuando incorpore coeficientes adicionales al modelo.
El elevado valor de SSE de 'exp1' indica que no se ajusta bien, algo que ya sabía después de estudiar el ajuste y los valores residuales. El menor valor de SSE es el de 'poly6'. Sin embargo, el comportamiento de este ajuste más allá del rango de datos lo convierte en una mala opción para extrapolar, por lo que ya rechazó este ajuste al estudiar las gráficas con los nuevos límites en los ejes.
El siguiente mejor valor de SSE es el del ajuste polinomial de quinto grado 'poly5', lo que sugiere que podría ser el mejor ajuste. Sin embargo, los valores de SSE y de R-cuadrado ajustado de los restantes ajustes polinomiales están muy próximos entre sí. ¿Cuál elegir?
Comparar los coeficientes y los intervalos de confianza para determinar el mejor ajuste
Solucione el problema de mejor ajuste estudiando los coeficientes y los intervalos de confianza de los restantes ajustes: el polinomial de quinto grado y el cuadrático.
Estudie population2 y population5 mostrando los modelos, los coeficientes ajustados y los intervalos de confianza de los coeficientes ajustados:
population2
population2 =
Linear model Poly2:
population2(x) = p1*x^2 + p2*x + p3
Coefficients (with 95% confidence bounds):
p1 = 0.006541 (0.006124, 0.006958)
p2 = -23.51 (-25.09, -21.93)
p3 = 2.113e+04 (1.964e+04, 2.262e+04)
population5
population5 =
Linear model Poly5:
population5(x) = p1*x^5 + p2*x^4 + p3*x^3 + p4*x^2 + p5*x + p6
where x is normalized by mean 1890 and std 62.05
Coefficients (with 95% confidence bounds):
p1 = 0.5877 (-2.305, 3.48)
p2 = 0.7047 (-1.684, 3.094)
p3 = -0.9193 (-10.19, 8.356)
p4 = 23.47 (17.42, 29.52)
p5 = 74.97 (68.37, 81.57)
p6 = 62.23 (59.51, 64.95)
También puede obtener los intervalos de confianza usando confint:
ci = confint(population5)
ci = 2×6
-2.3046 -1.6841 -10.1943 17.4213 68.3655 59.5102
3.4801 3.0936 8.3558 29.5199 81.5696 64.9469
Los intervalos de confianza en los coeficientes determinan su precisión. Compruebe las ecuaciones de ajuste (por ejemplo, f(x)=p1*x+p2*x...) para ver los términos del modelo para cada coeficiente. Tenga en cuenta que p2 hace referencia al término p2*x de 'poly2' y al término p2*x^4 de 'poly5'. No compare directamente coeficientes normalizados y no normalizados.
Los límites presentan un cruce por cero en los coeficientes p1, p2 y p3 del polinomio de quinto grado. Esto significa que no puede tener la certeza de que estos coeficientes difieran de cero. Si existe la posibilidad de que los términos de los modelos de mayor orden tengan coeficientes cero, esto no ayuda con el ajuste, ya que sugiere que este modelo se sobreajusta a los datos del censo.
Los coeficientes ajustados relativos a términos constantes, lineales y cuadráticos son casi idénticos en todas las ecuaciones polinomiales normalizadas. aSin embargo, a medida que el grado del polinomio aumenta, los límites de los coeficientes relativos a términos de mayor grado presentan un cruce por cero, lo que sugiere un sobreajuste.
En el caso del ajuste cuadrático, sin embargo, los intervalos de confianza pequeños no presentan un cruce por cero en p1, p2 ni p3, lo que indica que los coeficientes ajustados se conocen con bastante precisión.
Por lo tanto, después de estudiar los resultados tanto gráficos como numéricos, debería elegir el ajuste cuadrático population2 como el mejor ajuste para extrapolar los datos del censo.
Evaluar el mejor ajuste en puntos de consulta nuevos
Una vez seleccionado el mejor ajuste (population2) para extrapolar estos datos del censo, evalúelo con algunos puntos de consulta nuevos:
cdateFuture = (2000:10:2020).'; popFuture = population2(cdateFuture)
popFuture = 3×1
274.6221
301.8240
330.3341
Para calcular los intervalos de confianza del 95% respecto a la predicción de población futura, use el método predint:
ci = predint(population2,cdateFuture,0.95,'observation')ci = 3×2
266.9185 282.3257
293.5673 310.0807
321.3979 339.2702
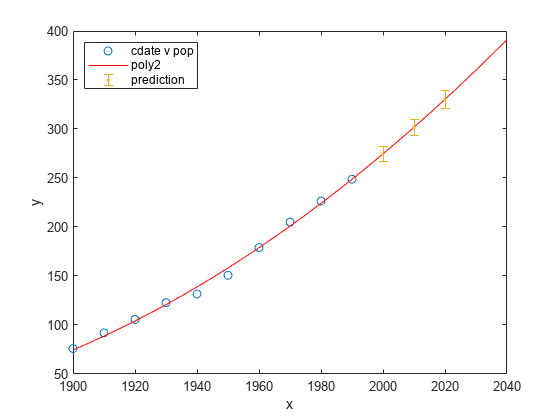
Represente la predicción de población futura con intervalos de confianza frente al ajuste y los datos.
plot(cdate,pop,'o'); xlim([1900,2040]) hold on plot(population2) h = errorbar(cdateFuture,popFuture,popFuture-ci(:,1),ci(:,2)-popFuture,'.'); hold off legend('cdate v pop','poly2','prediction', ... 'Location','NorthWest')
Para obtener más información, consulte Ajustar modelos polinomiales.