Procesamiento de sonido
Aplique deep learning a aplicaciones de procesamiento de audio y voz con Deep Learning Toolbox™ y Audio Toolbox™. Para obtener información sobre las aplicaciones de procesamiento de señales, consulte Procesamiento de señales. Para obtener información sobre las aplicaciones de comunicaciones inalámbricas, consulte Comunicaciones inalámbricas.
Apps
| Signal Labeler | Etiquete atributos de señal, regiones y puntos de interés y extraiga características |
Funciones
Bloques
Temas
- Deep Learning for Audio Applications (Audio Toolbox)
Learn common tools and workflows to apply deep learning to audio applications.
- Classify Sound Using Deep Learning (Audio Toolbox)
Train, validate, and test a simple long short-term memory (LSTM) to classify sounds.
- Adapt Pretrained Audio Network for New Data Using Deep Network Designer
This example shows how to interactively adapt a pretrained network to classify new audio signals using Deep Network Designer.
- Audio Transfer Learning Using Experiment Manager
Configure an experiment that compares the performance of multiple pretrained networks applied to a speech command recognition task using transfer learning.
- Compare Speaker Separation Models
Compare the performance, size, and speed of multiple deep learning speaker separation models.
- Speaker Identification Using Custom SincNet Layer and Deep Learning
Perform speech recognition using a custom deep learning layer that implements a mel-scale filter bank.
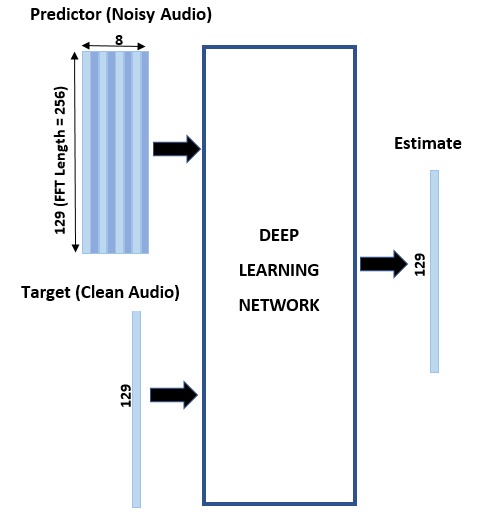
- Dereverberate Speech Using Deep Learning Networks
Train a deep learning model that removes reverberation from speech.
- Speech Command Recognition in Simulink
Detect the presence of speech commands in audio using a Simulink® model.
- Sequential Feature Selection for Audio Features
This example shows a typical workflow for feature selection applied to the task of spoken digit recognition.
- Train Spoken Digit Recognition Network Using Out-of-Memory Audio Data
This example trains a spoken digit recognition network on out-of-memory audio data using a transformed datastore.
- Train Spoken Digit Recognition Network Using Out-of-Memory Features
This example trains a spoken digit recognition network on out-of-memory auditory spectrograms using a transformed datastore.
- Investigate Audio Classifications Using Deep Learning Interpretability Techniques
This example shows how to use interpretability techniques to investigate the predictions of a deep neural network trained to classify audio data.
- Accelerate Audio Deep Learning Using GPU-Based Feature Extraction
Leverage GPUs for feature extraction to decrease the time required to train an audio deep learning model.
Información relacionada
Ejemplos destacados


















You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)