Surrogate Optimization Algorithm
Serial surrogateopt Algorithm
Serial surrogateopt Algorithm Overview
The surrogate optimization algorithm alternates between two phases.
Construct Surrogate — Create
options.MinSurrogatePointsrandom points within the bounds. Evaluate the (expensive) objective function at these points. Construct a surrogate of the objective function by interpolating a radial basis function through these points.Search for Minimum — Search for a minimum of the objective function by sampling several thousand random points within the bounds. Evaluate a merit function based on the surrogate value at these points and on the distances between them and points where the (expensive) objective function has been evaluated. Choose the best point as a candidate, as measured by the merit function. Evaluate the objective function at the best candidate point. This point is called an adaptive point. Update the surrogate using this value and search again.
During the Construct Surrogate phase, the algorithm constructs sample points from a
quasirandom sequence. Constructing an interpolating radial basis function takes at least
nvars + 1 sample points, where nvars is the number
of problem variables. The default value of options.MinSurrogatePoints
is 2*nvars or 20, whichever is larger.
The algorithm stops the Search for Minimum phase when all the search points are too
close (less than the option MinSampleDistance) to points where the
objective function was previously evaluated. See Search for Minimum Details. This switch from the Search
for Minimum phase is called surrogate reset.
If surrogateopt encounters a NaN value when
evaluating the objective or nonlinear constraint functions,
surrogateopt rejects the evaluation point and continues.
Definitions for Surrogate Optimization
The surrogate optimization algorithm description uses the following definitions.
Current — The point where the objective function was evaluated most recently.
Incumbent — The point with the smallest objective function value among all evaluated since the most recent surrogate reset.
Best — The point with the smallest objective function value among all evaluated so far.
Initial — The points, if any, that you pass to the solver in the
InitialPointsoption.Random points — Points in the Construct Surrogate phase where the solver evaluates the objective function. Generally, the solver takes these points from a quasirandom sequence, scaled and shifted to remain within the bounds. A quasirandom sequence is similar to a pseudorandom sequence such as
randreturns, but is more evenly spaced. See https://en.wikipedia.org/wiki/Low-discrepancy_sequence. However, when the number of variables is above 500, the solver takes points from a Latin hypercube sequence. See https://en.wikipedia.org/wiki/Latin_hypercube_sampling.Adaptive points — Points in the Search for Minimum phase where the solver evaluates the objective function.
Merit function — See Merit Function Definition.
Evaluated points — All points at which the objective function value is known. These points include initial points, Construct Surrogate points, and Search for Minimum points at which the solver evaluates the objective function.
Sample points. Pseudorandom points where the solver evaluates the merit function during the Search for Minimum phase. These points are not points at which the solver evaluates the objective function, except as described in Search for Minimum Details.
Construct Surrogate Details
To construct the surrogate, the algorithm chooses quasirandom points within the
bounds. If you pass an initial set of points in the InitialPoints
option, the algorithm uses those points and new quasirandom points (if necessary) to reach
a total of options.MinSurrogatePoints.
When BatchUpdateInterval > 1, the minimum
number of random sample points used to create a surrogate is the larger of
MinSurrogatePoints and BatchUpdateInterval.
Note
If some upper bounds and lower bounds are equal, surrogateopt
removes those "fixed" variables from the problem before constructing a surrogate.
surrogateopt manages the variables seamlessly. So, for example,
if you pass initial points, pass the full set, including any fixed variables.
On subsequent Construct Surrogate phases, the algorithm uses
options.MinSurrogatePoints quasirandom points. The algorithm
evaluates the objective function at these points.
The algorithm constructs a surrogate as an interpolation of the objective function by using a radial basis function (RBF) interpolator. RBF interpolation has several convenient properties that make it suitable for constructing a surrogate:
An RBF interpolator is defined using the same formula in any number of dimensions and with any number of points.
An RBF interpolator takes the prescribed values at the evaluated points.
Evaluating an RBF interpolator takes little time.
Adding a point to an existing interpolation takes relatively little time.
Constructing an RBF interpolator involves solving an N-by-N linear system of equations, where N is the number of surrogate points. As Powell [1] showed, this system has a unique solution for many RBFs.
surrogateoptuses a cubic RBF with a linear tail. This RBF minimizes a measure of bumpiness. See Gutmann [4].
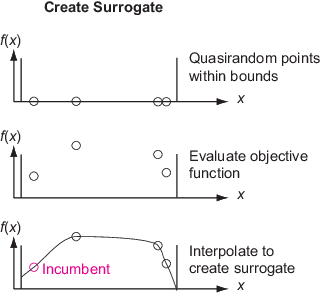
The algorithm uses only initial points and random points in the first Construct Surrogate phase, and uses only random points in subsequent Construct Surrogate phases. In particular, the algorithm does not use any adaptive points from the Search for Minimum phase in this surrogate.
Search for Minimum Details
The solver searches for a minimum of the objective function by following a procedure that is related to local search. The solver initializes a scale for the search with the value 0.2. The scale is like a search region radius or the mesh size in a pattern search. The solver starts from the incumbent point, which is the point with the smallest objective function value since the last surrogate reset. The solver searches for a minimum of a merit function that relates to both the surrogate and to a distance from existing search points, to try to balance minimizing the surrogate and searching the space. See Merit Function Definition.
The solver adds hundreds or thousands of pseudorandom vectors with scaled length to
the incumbent point to obtain sample points. For details, see the
Sampler Cycle table and surrounding
discussion. These vectors are shifted and scaled by the bounds in each dimension, and
multiplied by the scale. If necessary, the solver alters the sample points so that they
stay within the bounds. The solver evaluates the merit function at the sample points, but
not at any point within options.MinSampleDistance of a previously
evaluated point. The point with the lowest merit function value is called the adaptive
point. The solver evaluates the objective function value at the adaptive point, and
updates the surrogate with this value. If the objective function value at the adaptive
point is sufficiently lower than the incumbent value, then the solver deems the search
successful and sets the adaptive point as the incumbent. Otherwise, the solver deems the
search unsuccessful and does not change the incumbent.
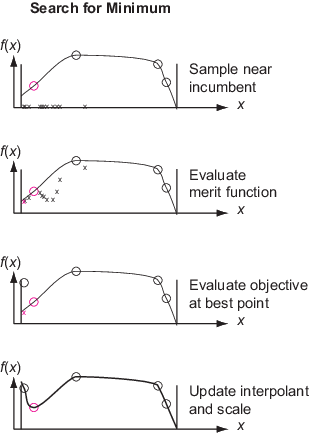
The solver changes the scale when the first of these conditions is met:
Three successful searches occur since the last scale change. In this case, the scale is doubled, up to a maximum scale length of
0.8times the size of the box specified by the bounds.max(5,nvar)unsuccessful searches occur since the last scale change, wherenvaris the number of problem variables. In this case, the scale is halved, down to a minimum scale length of1e-5times the size of the box specified by the bounds.
In this way, the random search eventually concentrates near an incumbent point that has a small objective function value. Then the solver geometrically reduces the scale toward the minimum scale length.
The way surrogateopt attempts to find a minimum of the merit
function is based on the problem type. The problem types are bounds plus optional linear
constraints, pure binary, binary plus linear constraints, and general integer with linear
constraints. (Nonlinear constraints do not affect these problem types.) Each sampler
samples points within a scaled region around the incumbent. Any integer points have a
scale that starts at ½ times the width of the bounds, and adjusts exactly as the
non-integer points, except that the width is increased to 1 if it would ever fall below
1.
For each problem type, surrogateopt chooses the sampler in a
cycle associated with the weights according to the following table.
Sampler Cycle
| Weight | 0.3 | 0.5 | 0.8 | 0.95 |
| Bounds + optional Linear | Random | Random | OrthoMADS | GPS |
| Pure Binary | Random | Random | Crossover | Crossover |
| Binary + Linear | OrthoMADS | OrthoMADS | Crossover | Crossover |
| Integer + Linear | OrthoMADS | Crossover | OrthoMADS | GPS |
Random — The sampler generates integer points uniformly at random within a scale, centered at the incumbent. The sampler generates continuous points according to a Gaussian with mean zero from the incumbent. The width of the samples of any integer points is multiplied by the scale, as is the standard deviation of the continuous points.
OrthoMADS — The sampler chooses an orthogonal coordinate system uniformly at random. The algorithm then creates sample points around the incumbent, adding and subtracting the current scale times each unit vector in the coordinate system. This creates 2N samples (unless some integer points are rounded to the incumbent), where N is the number of problem dimensions. OrthoMADS also uses two more points than the 2N fixed directions, one at [+1,+1,…,+1], and the other at [–1,–1,…,–1], for a total of 2N+2 points. Then the sampler repeatedly halves the 2N + 2 steps, creating a finer and finer set of points around the incumbent. This process ends when either there are enough samples. The points that should be integer-valued are then rounded to the nearest feasible integer points. The OrthoMADS algorithm is based on the paper [6]. That paper uses a quasirandom set of numbers for generating the coordinate system. In contrast,
surrogateoptuses standard MATLAB® pseudorandom numbers, with the orthogonal coordinates generated byqr.GPS (Generalized Pattern Search) — The sampler is like OrthoMADS, except instead of choosing a random set of directions, GPS uses the non-rotated coordinate system. The GPS algorithm is based on the paper [5]. This algorithm is described in detail in How Pattern Search Polling Works.
Crossover — The sampler uses the
ga"crossoverarithmetic"crossover function (see Crossover Options), where the population for crossover is the pointssurrogateopthas evaluated. The population is selected using the"selectiontournament"selection function (see Selection Options) with four players. The number of points in the sample depends on the trust region size; a smaller trust region radius leads to more points being sampled to evaluate the merit function.
The solver does not evaluate the merit function at points within
options.MinSampleDistance of an evaluated point (see Definitions for Surrogate Optimization). The solver switches from
the Search for Minimum phase to a Construct Surrogate phase (in other words, performs a
surrogate reset) when all sample points are within MinSampleDistance of
evaluated points. Generally, this reset occurs after the solver reduces the scale so that
all sample points are tightly clustered around the incumbent.
When the BatchUpdateInterval option is larger than
1, the solver generates BatchUpdateInterval
adaptive points before updating the surrogate model or changing the incumbent. The update
includes all of the adaptive points. Effectively, the algorithm does not use any new
information until it generates BatchUpdateInterval adaptive points, and
then the algorithm uses all the information to update the surrogate.
When the problem has no integer variables and has a nonlinear constraint, the
algorithm performs a search using MultiStart
fmincon on the merit function after every K (defined next) steps.
This is similar to the Tree Search algorithm for problems with
integer constraints. This fmincon call is time-consuming, but can
lead to a better feasible objective function value. The value of K depends on N:
If N < 15, K = max(50,10*N).
if N ≥15, K = max(50, 2*N).
Merit Function Definition
The merit function fmerit(x) is a weighted combination of two terms:
Scaled surrogate. Define smin as the minimum surrogate value among the sample points, smax as the maximum, and s(x) as the surrogate value at the point x. Then the scaled surrogate S(x) is
s(x) is nonnegative and is zero at points x that have minimal surrogate value among sample points.
Scaled distance. Define xj, j = 1,…,k as the k evaluated points. Define dij as the distance from sample point i to evaluated point k. Set dmin = min(dij) and dmax = max(dij), where the minimum and maximum are taken over all i and j. The scaled distance D(x) is
where d(x) is the minimum distance of the point x to an evaluated point. D(x) is nonnegative and is zero at points x that are maximally far from evaluated points. So, minimizing D(x) leads the algorithm to points that are far from evaluated points.
The merit function is a convex combination of the scaled surrogate and scaled distance. For a weight w with 0 < w < 1, the merit function is
A large value of w gives importance to the surrogate values, causing the search to minimize the surrogate. A small value of w gives importance to points that are far from evaluated points, leading the search to new regions. During the Search for Minimum phase, the weight w cycles through these four values, as suggested by Regis and Shoemaker [2]: 0.3, 0.5, 0.8, and 0.95.
Mixed-Integer surrogateopt Algorithm
Mixed-Integer surrogateopt Overview
When some or all of the variables are integer, as specified in the intcon argument,
surrogateopt changes some aspects of the Serial surrogateopt Algorithm. This description is mainly
about the changes, rather than the entire algorithm.
Algorithm Start
If necessary, surrogateopt moves the specified bounds for
intcon points so that they are integers. Also,
surrogateopt ensures that a supplied initial point is integer
feasible and feasible with respect to bounds. The algorithm then generates quasirandom
points as in the non-integer algorithm, rounding integer points to integer values. The
algorithm generates a surrogate exactly as in the non-integer algorithm.
Integer Search for Minimum
This portion of the algorithm is the same as in Search for Minimum Details. The modifications for integer constraints appear in that section.
Tree Search
After sampling hundreds or thousands of values of the merit function,
surrogateopt usually chooses the minimal point, and evaluates the
objective function. However, under some circumstances, surrogateopt
performs another search called a Tree Search before evaluating the objective. These
circumstances do not apply to pure binary problems or to problems with bounds only and
fewer than 15 variables. When applicable,
There have been 2N steps since the last Tree Search, called Case A.
surrogateoptis about to perform a surrogate reset, called Case B.
The Tree Search proceeds as follows, similar to a procedure in
intlinprog, as described in Branch-and-Bound. The algorithm makes a
tree by finding an integer value and creating a new problem that has a bound on this value
either one higher or one lower, and solving the subproblem with this new bound. After
solving the subproblem, the algorithm chooses a different integer to be bounded either
above or below by one.
Case A: Use the scaled sampling radius as the overall bounds, and run for up to 30 steps of the search.
Case B: Use the original problem bounds as the overall bounds, and run for up to 60 steps of the search.
In this case, solving the subproblem means running the fmincon
"sqp" algorithm on the continuous variables, starting from the
incumbent with the specified integer values, so search for a local minimum of the merit
function.
Tree Search can be time-consuming. So surrogateopt has an
internal iteration limit to avoid excessive time in this step, limiting both the number of
Case A and Case B steps.
After Tree Search, the algorithm performs a MultiStart
fmincon search using 20 points for MultiStart (5
points when N ≤ 10).
At the end of the Tree Search, the algorithm takes the better of the point found by Tree Search and the point found by the preceding search for a minimum, as measured by the merit function. The algorithm evaluates the objective function at this point. The remainder of the integer algorithm is exactly the same as the continuous algorithm.
Linear Constraint Handling
When a problem has linear constraints, the algorithm modifies its search procedure in a
way that keeps all points feasible with respect to these constraints and with respect to
bounds at every iteration. During the construction and search phases, the algorithm creates
only linearly feasible points by a procedure similar to the
patternsearch
"GSSPositiveBasis2N" poll algorithm.
When a problem has integer constraints and linear constraints, the algorithm first
creates linearly feasible points. Then the algorithm tries to satisfy integer constraints by
a process of rounding linearly feasible points to integers using a heuristic that attempts
to keeps the points linearly feasible. When this process is unsuccessful in obtaining enough
feasible points for constructing a surrogate, the algorithm calls
intlinprog to attempt to find more points that are feasible with
respect to bounds, linear constraints, and integer constraints.
surrogateopt Algorithm with Nonlinear Constraints
When the problem has nonlinear constraints, surrogateopt modifies
the previously described algorithm in several ways.
Initially and after each surrogate reset, the algorithm creates surrogates of the
objective and nonlinear constraint functions. Subsequently, the algorithm differs depending
on whether or not the Construct Surrogate phase found any feasible points; finding a
feasible point is equivalent to the incumbent point being feasible when the surrogate is
constructed. Note that if the objective or nonlinear constraint function evaluates to
NaN at a point, surrogateopt discards the
objective function value and the constraint at that point, and does not use that point for
creating or updating a surrogate.
Incumbent is infeasible — This case, called Phase 1, involves a search for a feasible point. In the Search for Minimum phase before encountering a feasible point,
surrogateoptchanges the definition of the merit function. The algorithm counts the number of constraints that are violated at each point, and considers only those points with the fewest number of violated constraints. Among those points, the algorithm chooses the point that minimizes the maximum constraint violation as the best (lowest merit function) point. This best point is the incumbent. Subsequently, until the algorithm encounters a feasible point, it uses this modification of the merit function. Whensurrogateoptevaluates a point and finds that it is feasible, the feasible point becomes the incumbent and the algorithm is in Phase 2.Incumbent is feasible — This case, called Phase 2, proceeds in the same way as the standard algorithm. The algorithm ignores infeasible points for the purpose of computing the merit function.
The algorithm proceeds according to the Mixed-Integer surrogateopt Algorithm with the following changes.
After every 2*nvars points where the algorithm evaluates the objective
and nonlinear constraint functions, surrogateopt calls the fmincon function to minimize the surrogate, subject to the surrogate nonlinear
constraints and bounds, where the bounds are scaled by the current scale factor. (If the
incumbent is infeasible, fmincon ignores the objective and attempts to
find a point satisfying the constraints.) If the problem has both integer and nonlinear
constraints, then surrogateopt calls Tree Search instead of
fmincon.
If the problem is a feasibility problem, meaning it has no objective function, then
surrogateopt performs a surrogate reset immediately after it finds a
feasible point.
Parallel surrogateopt Algorithm
The parallel surrogateopt algorithm differs from the serial algorithm
as follows:
The parallel algorithm maintains a queue of points on which to evaluate the objective function. This queue is 30% larger than the number of parallel workers, rounded up. The queue is larger than the number of workers to minimize the chance that a worker is idle because no point is available to evaluate.
The scheduler takes points from the queue in a FIFO fashion and assigns them to workers as they become idle, asynchronously.
When the algorithm switches between phases (Search for Minimum and Construct Surrogate), the existing points being evaluated remain in service, and any other points in the queue are flushed (discarded from the queue). So, generally, the number of random points that the algorithm creates for the Construct Surrogate phase is at most
options.MinSurrogatePoints + PoolSize, wherePoolSizeis the number of parallel workers. Similarly, after a surrogate reset, the algorithm still hasPoolSize - 1adaptive points that its workers are evaluating.
Note
Currently, parallel surrogate optimization does not necessarily give reproducible results, due to the nonreproducibility of parallel timing, which can lead to different execution paths.
Parallel Mixed-Integer surrogateopt Algorithm
When run in parallel on a mixed-integer problem, surrogateopt
performs the Tree Search procedure on the host, not on the parallel workers. Using the
latest surrogate, surrogateopt searches for a smaller value of the
surrogate after each worker returns with an adaptive point.
If the objective function is not expensive (time-consuming), then this Tree Search procedure can be a bottleneck on the host. In contrast, if the objective function is expensive, then the Tree Search procedure takes a small fraction of the overall computational time, and is not a bottleneck.
References
[1] Powell, M. J. D. The Theory of Radial Basis Function Approximation in 1990. In Light, W. A. (editor), Advances in Numerical Analysis, Volume 2: Wavelets, Subdivision Algorithms, and Radial Basis Functions. Clarendon Press, 1992, pp. 105–210.
[2] Regis, R. G., and C. A. Shoemaker. A Stochastic Radial Basis Function Method for the Global Optimization of Expensive Functions. INFORMS J. Computing 19, 2007, pp. 497–509.
[3] Wang, Y., and C. A. Shoemaker. A General Stochastic Algorithm Framework for Minimizing Expensive Black Box Objective Functions Based on Surrogate Models and Sensitivity Analysis. arXiv:1410.6271v1 (2014). Available at https://arxiv.org/pdf/1410.6271.
[4] Gutmann, H.-M. A Radial Basis Function Method for Global Optimization. Journal of Global Optimization 19, March 2001, pp. 201–227.
[5] Audet, Charles, and J. E. Dennis Jr. “Analysis of Generalized Pattern Searches.” SIAM Journal on Optimization. Volume 13, Number 3, 2003, pp. 889–903.
[6] Abramson, Mark A., Charles Audet, J. E. Dennis, Jr., and Sebastien Le Digabel. “ORTHOMADS: A deterministic MADS instance with orthogonal directions.” SIAM Journal on Optimization. Volume 20, Number 2, 2009, pp. 948–966.