Acelere la planificación del movimiento con un muestreador basado en aprendizaje profundo
El ejemplo muestra cómo utilizar planificadores basados en muestreo como RRT (árbol aleatorio de exploración rápida) y RRT* con Motion Planning Networks (MPNet), un muestreador basado en aprendizaje profundo para encontrar rutas óptimas de manera eficiente.
Los planificadores clásicos basados en muestreo, como RRT, RRT*, Bidireccional-RRT, se basan en generar muestras a partir de una distribución uniforme en un espacio de estados específico. Sin embargo, estos planificadores suelen restringir la ruta real del robot a una pequeña porción del espacio de estados. El muestreo uniforme hace que el planificador explore muchos estados que no tienen impacto en la ruta final. Esto hace que el proceso de planificación se vuelva lento e ineficiente, especialmente para espacios estatales con una gran cantidad de dimensiones y entornos que tienen pasajes estrechos.
Puede entrenar una red de aprendizaje profundo para generar muestras aprendidas que puedan sesgar la ruta hacia la solución óptima. Luego, utilice las muestras generadas con el planificador de rutas para encontrar las rutas óptimas en menos tiempo computacional. El ejemplo Entrene un muestreador basado en aprendizaje profundo para la planificación del movimiento muestra cómo entrenar una MPNet para realizar muestreo de espacio de estados.
Crear redes de planificación de movimiento
Cree un objeto de redes de planificación de movimiento para el espacio de estados SE(2) utilizando mpnetSE2.
mpnet = mpnetSE2;
Cargue trainedNetwork y los parámetros asociados del archivo .mat, mazeMapTrainedMPNET.mat. La red se almacena como un objeto dlnetwork con pesos aprendidos. La red se entrenó en varios mapas de laberinto generados aleatoriamente y almacenados en MazeMapDataset.mat. El archivo .mat también contiene rutas óptimas generadas para valores aleatorios de estados iniciales y objetivos en los entornos de entrenamiento. encodingSize es el tamaño de la representación comprimida del mapa del laberinto. stateBounds especifica los límites para el espacio de estados SE(2).
load("mazeMapTrainedMPNET.mat","trainedNetwork","mazeParams","encodingSize","stateBounds")
Establezca las propiedades EncodingSize, Network, StateBounds del objeto mpnetSE2 en los valores del entorno de entrenamiento.
mpnet.EncodingSize = encodingSize; mpnet.StateBounds = stateBounds; mpnet.Network = trainedNetwork;
Crear muestra de estado de MPNnet
Cree un muestreador de estado de MPNnet utilizando el espacio de estado y el objeto MPNet como entradas. Especifique los límites para el número máximo de muestras aprendidas en 50.
stateSpace = stateSpaceSE2(stateBounds); stateSamplerDL = stateSamplerMPNET(stateSpace,mpnet,MaxLearnedSamples=50,GoalThreshold=1);
Crear mapa de laberinto aleatorio
Cree un mapa de laberinto aleatorio para probar el muestreador de estado de MPNnet entrenado. eligiendo un inicio y un objetivo aleatorios del mapa.
Haga clic en el botón Run para generar un nuevo mapa.
rng("default") %Set random seed map = mapMaze(mazeParams{:}); figure show(map)
![Figure contains an axes object. The axes object with title Binary Occupancy Grid, xlabel X [meters], ylabel Y [meters] contains an object of type image.](acceleratemotionplanningwithdeeplearningbasedsamplerexample_03_es.png)
drawnow
Cree un validador de estado para el mapa generado. Establezca la distancia de validación en 0.1.
stateValidator = validatorOccupancyMap(stateSpace,Map=map); stateValidator.ValidationDistance = 0.1;
Elija un inicio y un objetivo aleatorios
Tome una muestra aleatoria de start y goal del mapa especificando una distancia mínima, minDistance, entre ellos. Elegir un valor más alto de minDistance hará que la planificación del movimiento sea más desafiante ya que los puntos de inicio y destino están lejos uno del otro y puede haber más obstáculos a lo largo del camino. Nuevo comienzo, se generarán pares de objetivos cada vez que haga clic en el botón Run.
minDistance=
11; while true [start, goal] = sampleStartGoal(stateValidator); if distance(stateValidator.StateSpace, start,goal) >= minDistance break end end figure show(map); hold on plot(start(1),start(2),plannerLineSpec.start{:}) plot(goal(1),goal(2),plannerLineSpec.goal{:}) legend(Location="eastoutside")
![Figure contains an axes object. The axes object with title Binary Occupancy Grid, xlabel X [meters], ylabel Y [meters] contains 3 objects of type image, line. One or more of the lines displays its values using only markers These objects represent Start, Goal.](acceleratemotionplanningwithdeeplearningbasedsamplerexample_04_es.png)
drawnow
Actualice las propiedades Environment, StartState y GoalState del muestreador de estado MPNet con el mapa de prueba, la pose inicial y la pose objetivo, respectivamente.
stateSamplerDL.Environment = map; stateSamplerDL.StartState = start; stateSamplerDL.GoalState = goal;
Planificar ruta RRT*
Ejecute la siguiente sección o haga clic en PlanPath para generar las rutas utilizando muestreo uniforme y muestreo basado en aprendizaje profundo con MPNet.

Muestreo uniforme
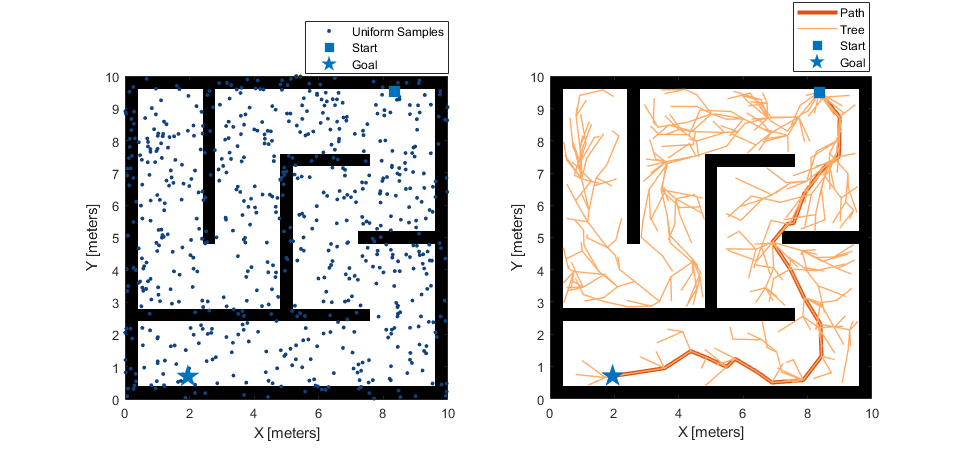
Planifique una ruta con muestreo de estado uniforme. A partir del resultado, es evidente que la ruta generada no es suave y la distancia recorrida no es óptima debido a la ruta en zigzag. Además, el árbol RRT muestra que muchos nodos se exploran pero no se utilizan y no tienen ningún impacto en la ruta final.
% Create RRT* planner with default uniform sampler plannerUniformSampling = plannerRRTStar(stateSpace,stateValidator,MaxConnectionDistance=1,StateSampler=stateSamplerUniform(stateSpace)); [pathUniformSampling,solutionInfoUniformSampling] = plan(plannerUniformSampling,start,goal); % Visualize results for uniform sampling figure show(map) hold on; plot(pathUniformSampling.States(:,1),pathUniformSampling.States(:,2),plannerLineSpec.path{:}) plot(solutionInfoUniformSampling.TreeData(:,1),solutionInfoUniformSampling.TreeData(:,2),plannerLineSpec.tree{:}) plot(start(1),start(2),plannerLineSpec.start{:}); plot(goal(1),goal(2),plannerLineSpec.goal{:}); legend(Location="northeastoutside") title("Uniform sampling")
![Figure contains an axes object. The axes object with title Uniform sampling, xlabel X [meters], ylabel Y [meters] contains 5 objects of type image, line. One or more of the lines displays its values using only markers These objects represent Path, Tree, Start, Goal.](acceleratemotionplanningwithdeeplearningbasedsamplerexample_05_es.png)
drawnow
Muestreo de red MPN
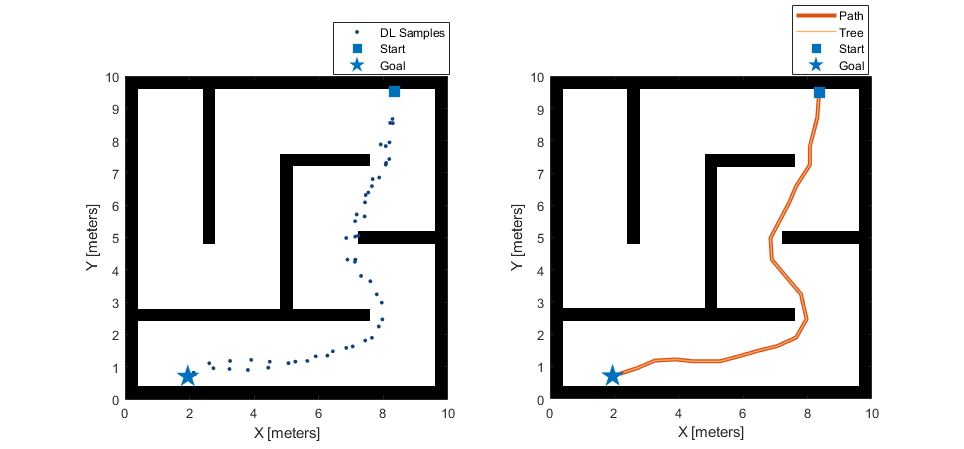
Planifique una ruta con el enfoque de muestreo de estado de MPNnet. A partir del resultado, es evidente que la ruta generada es suave y la distancia recorrida es mucho menor que la del muestreo uniforme. Además, el árbol RRT muestra que su muestreador explora un número limitado de nodos que se encuentran a lo largo de una ruta óptima factible entre los puntos inicial y objetivo.
plannerDLSampling = plannerRRTStar(stateSpace,stateValidator,MaxConnectionDistance=1,StateSampler=stateSamplerDL); [pathDLSampling,solutionInfoDLSampling] = plan(plannerDLSampling,start,goal); % Visualize results with deep learning based sampling figure show(map); hold on; plot(pathDLSampling.States(:,1),pathDLSampling.States(:,2),plannerLineSpec.path{:}) plot(solutionInfoDLSampling.TreeData(:,1),solutionInfoDLSampling.TreeData(:,2),plannerLineSpec.tree{:}) plot(start(1),start(2),plannerLineSpec.start{:}) plot(goal(1),goal(2),plannerLineSpec.goal{:}) legend(Location="northeastoutside") title("MPNet Sampling")
![Figure contains an axes object. The axes object with title MPNet Sampling, xlabel X [meters], ylabel Y [meters] contains 5 objects of type image, line. One or more of the lines displays its values using only markers These objects represent Path, Tree, Start, Goal.](acceleratemotionplanningwithdeeplearningbasedsamplerexample_06_es.png)
drawnow
Evaluación del desempeño
Utilice plannerBenchmark para comparar el rendimiento del muestreo basado en aprendizaje profundo y el muestreo uniforme utilizando varias métricas de evaluación, como el tiempo de ejecución, la longitud de la ruta y la suavidad. Elija runCount para definir el número de ejecuciones para generar las métricas. Cuanto mayor sea este valor, las métricas son más precisas. Puede haber algunos escenarios en los que el muestreo de MPNet tenga un rendimiento peor que el muestreo uniforme en algunas de estas métricas, pero los escenarios son menos probables. En tales casos, puede volver a entrenar la red para mejorar la precisión.
% Number of runs to benchmark the planner runCount =30; % Create plannerBenchmark object pb = plannerBenchmark(stateValidator,start,goal); % Create function handles to create planners for uniform sampling and deep % learning-based sampling plannerUniformSamplingFcn = @(stateValidator)plannerRRTStar(stateValidator.StateSpace,stateValidator,MaxConnectionDistance=1); plannerMPNetSamplingFcn = @(stateValidator)plannerRRTStar(stateValidator.StateSpace,stateValidator,MaxConnectionDistance=1,StateSampler=stateSamplerDL); % Create plan function plnFcn = @(initOut,s,g)plan(initOut,s,g); % Added both planners to plannerBenchmark object addPlanner(pb,plnFcn,plannerUniformSamplingFcn,PlannerName="Uniform"); addPlanner(pb,plnFcn,plannerMPNetSamplingFcn,PlannerName="MPNet"); % Run planners for specified runCount runPlanner(pb,runCount)
Initializing Uniform ... Done. Planning a path from the start pose (0.51332 0.72885 -2.5854) to the goal pose (7.9835 9.4301 1.1543) using Uniform. Executing run 1. Executing run 2. Executing run 3. Executing run 4. Executing run 5. Executing run 6. Executing run 7. Executing run 8. Executing run 9. Executing run 10. Executing run 11. Executing run 12. Executing run 13. Executing run 14. Executing run 15. Executing run 16. Executing run 17. Executing run 18. Executing run 19. Executing run 20. Executing run 21. Executing run 22. Executing run 23. Executing run 24. Executing run 25. Executing run 26. Executing run 27. Executing run 28. Executing run 29. Executing run 30. Initializing MPNet ... Done. Planning a path from the start pose (0.51332 0.72885 -2.5854) to the goal pose (7.9835 9.4301 1.1543) using MPNet. Executing run 1. Executing run 2. Executing run 3. Executing run 4. Executing run 5. Executing run 6. Executing run 7. Executing run 8. Executing run 9. Executing run 10. Executing run 11. Executing run 12. Executing run 13. Executing run 14. Executing run 15. Executing run 16. Executing run 17. Executing run 18. Executing run 19. Executing run 20. Executing run 21. Executing run 22. Executing run 23. Executing run 24. Executing run 25. Executing run 26. Executing run 27. Executing run 28. Executing run 29. Executing run 30.
Visualizar métricas de evaluación
Grafique las métricas calculadas por plannerBenchmark. Puede volver a generar métricas para diferentes mapas, estados de inicio y objetivos.
El tiempo de ejecución medio para el muestreo de MPNet es menor o similar al muestreo uniforme para la mayoría de los escenarios. Sin embargo, el muestreo de MPNnet tiene menos dispersión en comparación con el muestreo uniforme. Esto hace que el tiempo de ejecución sea más determinista y adecuado para la implementación en tiempo real.
figure
show(pb,"executionTime")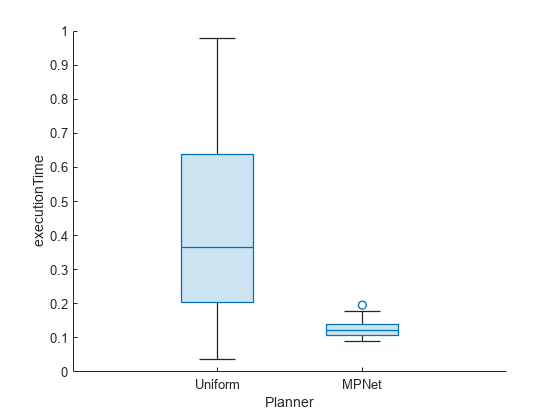
La longitud de ruta pathLength es mucho más pequeña para el muestreo MPNet en comparación con el muestreo uniforme. Además, la dispersión es menor, lo que la hace más determinista.
figure
show(pb,"pathLength")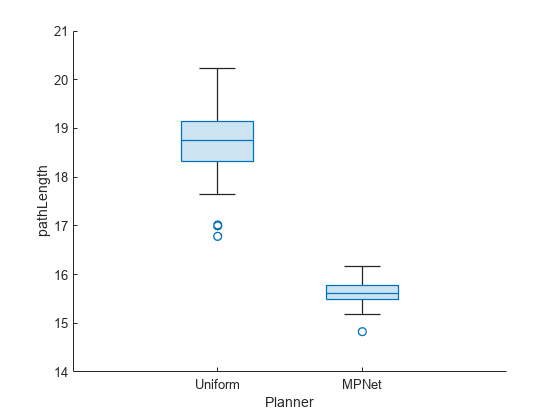
La suavidad también es mucho menor para el muestreo MPNet en comparación con el muestreo uniforme. Además, la dispersión es menor, lo que la hace más determinista.
figure
show(pb,"smoothness")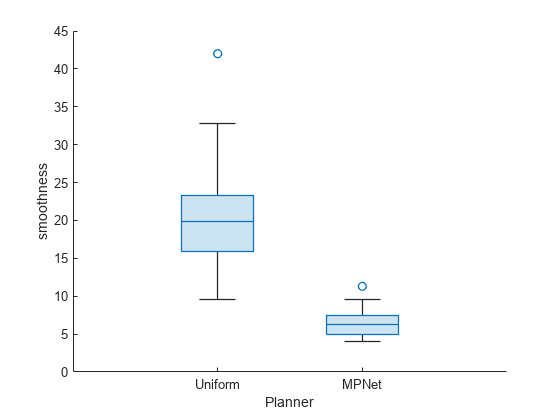
Grafique las rutas generadas por el objeto plannerBenchmark para el runCount especificado. Podemos observar que,
El muestreo uniforme proporciona rutas que tienen una alta dispersión y son subóptimas (tienen una mayor longitud de ruta y son menos suaves).
El muestreo MPNet proporciona rutas que tienen baja dispersión y son casi óptimas (tienen una longitud de ruta más pequeña y son más suaves).
figure; % Plot for planner output with uniform sampling subplot(121) show(map) hold on % Plot for planner output with MPNet sampling subplot(122); show(map) hold on for k =1:10 runName = "Run" + num2str(k); % Planner output with uniform sampling subplot(121) pathStates = pb.PlannerOutput.Uniform.PlanOutput.(runName){1}.States; plot(pathStates(:,1),pathStates(:,2),DisplayName=runName) plot(start(1),start(2),plannerLineSpec.start{:}) plot(goal(1),goal(2),plannerLineSpec.goal{:}) title("Uniform sampling") % Planner output with MPNet sampling subplot(122) pathStates = pb.PlannerOutput.MPNet.PlanOutput.(runName){1}.States; plot(start(1),start(2),plannerLineSpec.start{:}) plot(goal(1),goal(2),plannerLineSpec.goal{:}) plot(pathStates(:,1),pathStates(:,2),DisplayName=runName) title("MPNet sampling") end
![Figure contains 2 axes objects. Axes object 1 with title Uniform sampling, xlabel X [meters], ylabel Y [meters] contains 31 objects of type image, line. One or more of the lines displays its values using only markers These objects represent Run1, Start, Goal, Run2, Run3, Run4, Run5, Run6, Run7, Run8, Run9, Run10. Axes object 2 with title MPNet sampling, xlabel X [meters], ylabel Y [meters] contains 31 objects of type image, line. One or more of the lines displays its values using only markers These objects represent Start, Goal, Run1, Run2, Run3, Run4, Run5, Run6, Run7, Run8, Run9, Run10.](acceleratemotionplanningwithdeeplearningbasedsamplerexample_10_es.png)
Conclusión
Este ejemplo muestra cómo integrar el muestreador basado en aprendizaje profundo entrenado en el ejemplo Entrene un muestreador basado en aprendizaje profundo para la planificación del movimiento con plannerRRTStar usando un muestreador de estado personalizado. Muestra cómo la ruta planificada y el árbol RRT mejoran con el muestreo aprendido. También muestra que el muestreo aprendido ofrece un rendimiento estadísticamente mejor para métricas como el tiempo de ejecución, la longitud de la ruta y la fluidez. Podemos utilizar el enfoque de muestreo basado en aprendizaje profundo para otros planificadores basados en muestreo, como plannerRRT, plannerBiRRT, plannerPRM , y también podemos ampliarlo para otras aplicaciones, como la planificación de trayectorias de manipuladores y la planificación de trayectorias de UAV.
Consulte también
mpnetSE2 | plannerRRTStar | stateSamplerMPNET | stateSamplerUniform
Temas
Referencias
[1] Prokudin, Sergey, Christoph Lassner, and Javier Romero. “Efficient Learning on Point Clouds with Basis Point Sets.” In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 3072–81. Seoul, Korea (South): IEEE, 2019. https://doi.org/10.1109/ICCVW.2019.00370.
[2] Qureshi, Ahmed Hussain, Yinglong Miao, Anthony Simeonov, and Michael C. Yip. “Motion Planning Networks: Bridging the Gap Between Learning-Based and Classical Motion Planners.” IEEE Transactions on Robotics 37, no. 1 (February 2021): 48–66. https://doi.org/10.1109/TRO.2020.3006716.
[3] Qureshi, Ahmed H., and Michael C. Yip. “Deeply Informed Neural Sampling for Robot Motion Planning.” In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 6582–88. Madrid: IEEE, 2018. https://doi.org/10.1109/IROS.2018.8593772.