Visualizar y evaluar el rendimiento de modelos en Regression Learner
Después de entrenar modelos de regresión en la app Regression Learner, puede comparar modelos en función de las métricas de los modelos, visualizar resultados en una gráfica de respuesta o representando la respuesta real frente a la predicha y evaluar modelos utilizando la gráfica residual.
Si se utiliza la validación cruzada de k particiones, la app calcula las métricas del modelo utilizando las observaciones de las k particiones de validación e informa de los valores medios. La app realiza predicciones sobre las observaciones en las particiones de validación y muestra estas predicciones en las gráficas. La app también calcula los valores residuales de las observaciones en las particiones de validación.
Nota
Cuando se importan datos a la app, si se aceptan los valores predeterminados, la app utiliza automáticamente la validación cruzada. Para obtener más información, consulte Elegir esquema de validación.
Si se utiliza la validación por retención, la app calcula las métricas del modelo utilizando las observaciones de la partición de validación y realiza predicciones sobre las observaciones. La app utiliza estas predicciones en las gráficas y también calcula los valores residuales basándose en las predicciones.
Si se utiliza la validación por sustitución, los valores son métricas del modelo de sustitución basadas en todos los datos de entrenamiento y las predicciones son predicciones de sustitución.
Comprobar el rendimiento en el panel Models
Después de entrenar un modelo en Regression Learner, compruebe el panel Models para ver qué modelo tiene la mejor puntuación global. El mejor RMSE (Validation) se muestra resaltado en un cuadro. Esta puntuación es la raíz del error cuadrático medio (RMSE) en el conjunto de validación. La puntuación estima el rendimiento del modelo entrenado en los nuevos datos. Utilice la puntuación para elegir el mejor modelo.

Para la validación cruzada, la puntuación es el RMSE de todas las observaciones no reservadas para las pruebas, contando cada observación cuando estaba en una partición de retención (validación).
En el caso de la validación por retención, la puntuación es el RMSE de las observaciones retenidas.
Para la validación por sustitución, la puntuación es el RMSE de la sustitución en todos los datos de entrenamiento.
La mejor puntuación global puede no ser el mejor modelo para su objetivo. En ocasiones, un modelo con una puntuación global ligeramente inferior puede ser el mejor modelo para su objetivo. Se debe evitar el sobreajuste y es posible que desee excluir algunos predictores cuando la recopilación de datos sea costosa o difícil.
Ver métricas del modelo en la pestaña Summary y en el panel Models
Puede ver las métricas del modelo en la pestaña Summary y en el panel Models y utilizar estas métricas para evaluar y comparar modelos. De forma alternativa, puede utilizar la gráfica para comparar resultados y la pestaña Results Table para comparar modelos. Para obtener más información, consulte Ver la información del modelo y los resultados en una gráfica para comparar resultados y Comparar la información del modelo y los resultados en una vista de tabla.
Las métricas de Training Results se calculan sobre el conjunto de validación. Las métricas de Test Results, si se muestran, se calculan sobre un conjunto de prueba. Para obtener más información, consulte Evaluar el rendimiento del modelo de un conjunto de prueba.

Métricas del modelo
| Estadística | Descripción | Consejo |
|---|---|---|
| RMSE | Raíz del error cuadrático medio. El RMSE es siempre positivo y sus unidades coinciden con las unidades de la respuesta. | Busque valores más pequeños del RMSE. |
| R cuadrado (R2) | Coeficiente de determinación. La app calcula los valores de R2 ordinario (no ajustado). R2 es siempre menor que 1 y normalmente mayor que 0. Compara el modelo entrenado con el modelo en el que la respuesta es constante e igual a la media de la respuesta de entrenamiento. Si el modelo es peor que este modelo constante, R2 es negativo. La estadística R2 no es una métrica útil para la mayoría de modelos de regresión. Para obtener más información, consulte Rsquared. | Busque un valor de R2 cercano a 1. |
| MSE | Error cuadrático medio. El MSE es el cuadrado del RMSE. | Busque valores más pequeños del MSE. |
| EMA | Error medio absoluto. El EMA es siempre positivo y similar al RMSE, pero menos susceptible a los valores atípicos. | Busque valores más pequeños del EMA. |
| MAPE | Error porcentual medio absoluto. El MAPE es siempre no negativo e indica la comparación del error de predicción con la respuesta. Para obtener más información, consulte Mean Absolute Percentage Error. | Busque valores más pequeños del MAPE. |
| Velocidad de predicción | Velocidad de predicción estimada para los nuevos datos, basada en los tiempos de predicción de los conjuntos de datos de validación. | Los procesos que se llevan a cabo en segundo plano tanto dentro como fuera de la app pueden afectar a esta estimación, de modo que es importante entrenar los modelos en condiciones similares para obtener mejores comparaciones. |
| Tiempo de entrenamiento | Tiempo dedicado a entrenar el modelo. | Los procesos que se llevan a cabo en segundo plano tanto dentro como fuera de la app pueden afectar a esta estimación, de modo que es importante entrenar los modelos en condiciones similares para obtener mejores comparaciones. |
| Tamaño del modelo (compacto) | Tamaño del objeto de modelo de machine learning si se exporta como modelo compacto (es decir, sin datos de entrenamiento). Cuando se exporta un modelo al área de trabajo, la estructura exportada contiene el objeto de modelo y campos adicionales. La app muestra el tamaño del objeto de modelo (en bytes) tal como lo devuelve la función whos. Tenga en cuenta que es posible que la función learnersize devuelva un tamaño diferente para algunos tipos de modelo, porque llama a gather en el objeto de modelo antes de llamar a whos. | Busque valores del tamaño del modelo que se ajusten a los requisitos de memoria de las aplicaciones objetivo. |
| Tamaño del modelo (codificador) | Tamaño aproximado del modelo (en bytes) en código C/C++ generado por MATLAB® Coder™. La app muestra el tamaño (en bytes) devuelto por la función learnersize con type="coder". El tamaño del modelo codificador es NaN para tipos de modelo que no son compatibles con la generación de código. | Para ver una lista de los tipos de modelo compatibles, consulte Export Regression Model to MATLAB Coder to Generate C/C++ Code. |
Puede ordenar los modelos en el panel Models en función de diferentes métricas del modelo. Para seleccionar una métrica para la ordenación, utilice la lista Sort by situada en la parte superior del panel Models. No todas las métricas están disponibles para la ordenación de modelos en el panel Models. Puede ordenar los modelos por otras métricas en Results Table (consulte Comparar la información del modelo y los resultados en una vista de tabla).
También puede eliminar los modelos no deseados que aparecen en el panel Models. Seleccione el modelo que desea eliminar y haga clic en el botón Delete selected model situado en la parte superior derecha del panel o haga clic con el botón secundario en el modelo y seleccione Delete. No puede eliminar el último modelo restante del panel Models.
Comparar la información del modelo y los resultados en una vista de tabla
En lugar de utilizar la pestaña Summary o el panel Models para comparar las métricas del modelo, puede utilizar una tabla de resultados. En la pestaña Learn, de la sección Plots and Results, haga clic en Results Table. En la pestaña Results Table, puede ordenar los modelos en función de sus resultados de entrenamiento y prueba, así como en función de sus opciones (como tipo de modelo, características seleccionadas, PCA, etc.). Por ejemplo, para ordenar los modelos por la raíz del error cuadrático medio, haga clic en las flechas de ordenación del encabezado de la columna RMSE (Validation). Una flecha hacia arriba indica que los modelos están ordenados del RMSE más bajo al RMSE más alto.
Para ver más opciones de columnas de la tabla, haga clic en el botón "Select columns to display"  situado en la parte superior derecha de la tabla. En el cuadro de diálogo Select Columns to Display, marque las casillas de las columnas que desee mostrar en la tabla de resultados. Las nuevas columnas seleccionadas se añaden en la parte de la derecha de la tabla.
situado en la parte superior derecha de la tabla. En el cuadro de diálogo Select Columns to Display, marque las casillas de las columnas que desee mostrar en la tabla de resultados. Las nuevas columnas seleccionadas se añaden en la parte de la derecha de la tabla.

Dentro de la tabla de resultados, puede arrastrar y soltar manualmente las columnas de la tabla para que aparezcan en el orden que prefiera.
Puede marcar determinados modelos como favoritos utilizando la columna Favorite. La app mantiene una selección coherente de modelos favoritos entre la tabla de resultados y el panel Models. A diferencia de otras columnas, las columnas Favorite y Model Number no se pueden eliminar de la tabla.
Para eliminar una fila de la tabla, haga clic con el botón secundario en cualquier entrada dentro de la fila y haga clic en Hide row (o Hide selected row(s) si la fila está resaltada). Para eliminar filas consecutivas, haga clic en cualquier entrada dentro de la primera fila que desee eliminar, pulse Mayús y haga clic en cualquier entrada dentro de la última fila que desee eliminar. Después, haga clic con el botón secundario en cualquiera de las entradas resaltadas y haga clic en Hide selected row(s). Para restaurar todas las filas eliminadas, haga clic con el botón secundario en cualquier entrada de la tabla y haga clic en Show all rows. Las filas restauradas se añaden a la parte inferior de la tabla.
Para exportar la información de la tabla, utilice uno de los botones de exportación  situados en la parte superior derecha de la tabla. Puede elegir entre exportar la tabla al área de trabajo o a un archivo. La tabla exportada solo incluye las filas y columnas que se muestran.
situados en la parte superior derecha de la tabla. Puede elegir entre exportar la tabla al área de trabajo o a un archivo. La tabla exportada solo incluye las filas y columnas que se muestran.
Ver la información del modelo y los resultados en una gráfica para comparar resultados
Puede ver la información del modelo y los resultados en una gráfica para comparar resultados. En la pestaña Learn o Test, de la sección Plots and Results, haga clic en Compare Results. De forma alternativa, haga clic en el botón Plot Results en la pestaña Results Table. La gráfica muestra una gráfica de barras de RMSE de validación para los modelos, ordenados del valor RMSE más bajo al más alto. Puede ordenar los modelos por otros resultados de entrenamiento y prueba usando la lista Sort by en Sort Data. Para agrupar modelos del mismo tipo, seleccione Group by model type. Para asignar el mismo color a todos los tipos de modelo, desactive Color by model type.

Seleccione los tipos de modelo que desea mostrar usando las casillas de Select. Oculte un modelo mostrado haciendo clic con el botón secundario en una barra de la gráfica y seleccionando Hide Model.
También puede seleccionar y filtrar los modelos mostrados haciendo clic en el botón Filter de Filter and Group. En el cuadro de diálogo Filter and Select Models, haga clic en Select Metrics y seleccione las métricas que desea mostrar en la tabla de modelos en la parte superior del cuadro de diálogo. Dentro de la tabla, puede arrastrar las columnas de la tabla para que aparezcan en el orden que prefiera. Haga clic en las flechas de ordenación de los encabezados de la tabla para ordenar la tabla. Para filtrar modelos por valor de métrica, seleccione primero una métrica en la columna Filter by. Después, seleccione una condición en la tabla Filter Models, introduzca un valor en el campo Value y haga clic en Apply Filter(s). La app actualiza las selecciones de la tabla de modelos. Puede especificar condiciones adicionales haciendo clic en el botón Add Filter. Haga clic en OK para mostrar la gráfica actualizada.

Seleccione otras métricas que desea representar en las listas X e Y en Plot Data. Si no selecciona Model Number para X o Y, la app muestra una gráfica de dispersión.

Para exportar una gráfica para comparar resultados a una figura, consulte Export Plots in Regression Learner App.
Para exportar la tabla de resultados al área de trabajo, haga clic en Export Plot y seleccione Export Plot Data. En el cuadro de diálogo Export Result Metrics Plot Data, edite el nombre de la variable exportada, si es necesario, y haga clic en OK. La app crea un arreglo de estructura que contiene la tabla de resultados.
Explorar los datos y resultados en la gráfica de respuesta
Visualice los resultados del modelo de regresión mediante la gráfica de respuesta, que muestra la respuesta predicha frente al número de registro. Después de entrenar un modelo de regresión, la app abre automáticamente la gráfica de respuesta de ese modelo. Si entrena un modelo "All", la app abre la gráfica de respuesta solo para el primer modelo. Para ver la gráfica de respuesta de otro modelo, seleccione el modelo en el panel Models. En la sección Plots and Results de la pestaña Learn, haga clic en la flecha para abrir la galería y, a continuación, haga clic en Response en el grupo Validation Results. Si utiliza la validación por retención o cruzada, los valores de respuesta predichos son las predicciones de las observaciones retenidas (de validación). En otras palabras, el software obtiene cada predicción mediante un modelo que se entrenó sin la observación correspondiente.
Para investigar los resultados, utilice los controles a la derecha. Puede:
Representar las respuestas predichas y/o verdaderas. Utilizar las casillas de Plot para hacer su selección.
Mostrar los errores de predicción, representados como líneas verticales entre las respuestas predichas y las verdaderas, seleccionando la casilla Errors.
Elegir la variable que desee representar en el eje x, en X-axis. Puede elegir el número de registro o una de sus variables predictoras.

Representar la respuesta como marcadores o como una gráfica de caja en Style. Solo se puede seleccionar Box plot cuando la variable del eje x tiene pocos valores únicos.
Una gráfica de caja muestra los valores típicos de la respuesta y los posibles valores atípicos. La marca central indica la mediana y los extremos inferior y superior de la caja son los percentiles 25 y 75, respectivamente. Las líneas verticales, denominadas bigotes, se extienden desde las cajas hasta los puntos de datos más extremos que no se consideran valores atípicos. Los valores atípicos se representan individualmente con el símbolo
"o". Para obtener más información sobre las gráficas de caja, consulteboxchart.
Para exportar las gráficas de respuesta que cree en la app como figuras, consulte Export Plots in Regression Learner App.
Representar una respuesta predicha en comparación con una respuesta real
Utilice la gráfica Predicted vs. Actual para comprobar el rendimiento del modelo. Utilice esta gráfica para comprender lo bien que el modelo de regresión realiza predicciones para diferentes valores de respuesta. Para ver la gráfica Predicted vs. Actual después de entrenar un modelo, haga clic en la flecha de la sección Plots and Results para abrir la galería y, después, haga clic en Predicted vs. Actual (Validation), en el grupo Validation Results.
Cuando se abre la gráfica, la respuesta predicha del modelo se representa en comparación con la respuesta real verdadera. En un modelo de regresión perfecto, la respuesta predicha es igual a la respuesta verdadera, por lo que todos los puntos se sitúan en una línea diagonal. La distancia vertical de la línea a cualquier punto es el error de la predicción para ese punto. Un buen modelo tiene pequeños errores, lo que significa que las predicciones aparecen dispersas cerca de la línea.

Por lo general, un buen modelo tiene puntos dispersos de forma casi simétrica alrededor de la línea diagonal. Si se observa algún patrón claro en la gráfica, es probable que pueda mejorar el modelo. Pruebe a entrenar un tipo de modelo diferente o a flexibilizar el tipo de modelo actual duplicando el modelo y utilizando las opciones de Model Hyperparameters de la pestaña Summary del modelo. Si no consigue mejorar el modelo, es posible que necesite más datos o que le falte un predictor importante.
Para exportar las gráficas Predicted vs. Actual que cree en la app como figuras, consulte Export Plots in Regression Learner App.
Evaluar modelos con gráficas de valores residuales
Utilice la gráfica de valores residuales para comprobar el rendimiento del modelo. Para ver la gráfica de valores residuales después de entrenar un modelo, haga clic en la flecha de la sección Plots and Results para abrir la galería y, después, haga clic en Residuals (Validation), en el grupo Validation Results. La gráfica de valores residuales muestra la diferencia entre las respuestas predichas y las verdaderas. Elija la variable que desee representar en el eje x, en X-axis. Elija la respuesta verdadera, la respuesta predicha, el número de registro o uno de los predictores.
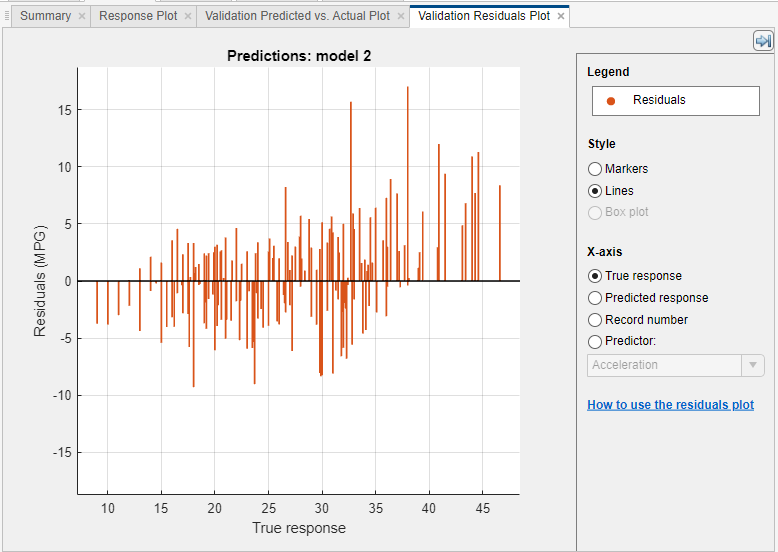
Normalmente, un buen modelo tiene valores residuales dispersos de forma casi simétrica en torno a 0. Si se observa algún patrón claro en los valores residuales, es probable que pueda mejorar el modelo. Busque los siguientes patrones:
Valores residuales que no se distribuyen simétricamente en torno a 0.
Valores residuales que cambian significativamente de tamaño de izquierda a derecha en la gráfica.
Se producen valores atípicos, es decir, valores residuales mucho mayores que el resto de valores residuales.
Aparece un claro patrón no lineal en los valores residuales.
Pruebe a entrenar un tipo de modelo diferente o a flexibilizar el tipo de modelo actual duplicando el modelo y utilizando las opciones de Model Hyperparameters de la pestaña Summary del modelo. Si no consigue mejorar el modelo, es posible que necesite más datos o que le falte un predictor importante.
Para exportar las gráficas de valores residuales que cree en la app como figuras, consulte Export Plots in Regression Learner App.
Comparar gráficas de modelos cambiando el diseño
Visualice los resultados de los modelos entrenados en Regression Learner con las opciones de la gráfica recogidas en la sección Plots and Results de la pestaña Learn. Puede reorganizar el diseño de las gráficas para comparar los resultados de varios modelos: utilice las opciones del botón Layout, arrastre y suelte las gráficas o seleccione las opciones del botón Document Actions situado a la derecha de las pestañas de las gráficas de los modelos.
Por ejemplo, después de entrenar dos modelos en Regression Learner, visualice una gráfica para cada modelo y cambie el diseño de la gráfica para comparar las gráficas usando uno de los siguientes procedimientos:
En la sección Plots and Results, haga clic en Layout y seleccione Compare models.
Haga clic en el nombre de la pestaña del segundo modelo y, después, arrastre y suelte la pestaña del segundo modelo a la derecha.
Haga clic en el botón Document Actions situado en el extremo derecho de las pestañas de las gráficas de los modelos. Seleccione la opción
Tile Ally especifique un diseño de 1 por 2.
Tenga en cuenta que puede hacer clic en el botón para ocultar las opciones de la gráfica  situado en la parte superior derecha de las gráficas para dejar más espacio para las gráficas.
situado en la parte superior derecha de las gráficas para dejar más espacio para las gráficas.
Evaluar el rendimiento del modelo de un conjunto de prueba
Después de entrenar un modelo en Regression Learner, puede evaluar el rendimiento del modelo en un conjunto de prueba en la app. Este proceso permite comprobar si las métricas de validación ofrecen buenas estimaciones para el rendimiento del modelo con nuevos datos.
Importe un conjunto de datos de prueba en Regression Learner. También puede reservar algunos datos para realizar pruebas cuando se importen datos a la app (consulte (Opcional) Reservar datos para las pruebas).
Si el conjunto de datos de prueba se encuentra en el área de trabajo de MATLAB, en la sección Data de la pestaña Test, haga clic en Test Data y seleccione From Workspace.
Si el conjunto de datos de prueba se encuentra en un archivo, en la sección Data, haga clic en Test Data y seleccione From File. Seleccione un tipo de archivo de la lista, como una hoja de cálculo, archivo de texto o archivo de valores separados por comas (
.csv), o seleccione All Files para examinar otros tipos de archivos como los.dat.
En el cuadro de diálogo Import Test Data, seleccione el conjunto de datos de prueba de la lista Test Data Set Variable. El conjunto de prueba debe tener las mismas variables que los predictores importados para el entrenamiento y la validación.
Calcule las métricas del conjunto de prueba.
Para calcular las métricas de prueba de un único modelo, seleccione el modelo entrenado del panel Models. En la pestaña Test, de la sección Test, haga clic en Test Selected.
Para calcular las métricas de prueba de todos los modelos entrenados, haga clic en Test All, en la sección Test.
La app calcula el rendimiento del conjunto de prueba de cada modelo entrenado con el conjunto de datos completo, incluyendo los datos de entrenamiento y validación (pero excluyendo los datos de prueba).
Compare las métricas de validación con las métricas de prueba.
En la pestaña Summary del modelo, la app muestra las métricas de validación y las métricas de prueba en la sección Training Results y en la sección Test Results, respectivamente. Puede comprobar si las métricas de validación ofrecen buenas estimaciones para las métricas de prueba.
También puede visualizar los resultados de la prueba con gráficas.
Visualice una gráfica Predicted vs. Actual. En la sección Plots and Results de la pestaña Test, haga clic en Predicted vs. Actual (Test).
Visualice una gráfica de valores residuales. En la sección Plots and Results, haga clic en Residuals (Test).
Para ver un ejemplo, consulte Check Model Performance Using Test Data Set in Regression Learner App. Para ver un ejemplo que utiliza métricas de conjuntos de prueba en un flujo de trabajo de optimización de hiperparámetros, consulte Train Regression Model Using Hyperparameter Optimization in Regression Learner App.
Consulte también
Temas
- Train Regression Models in Regression Learner App
- Seleccionar datos para regresión o abrir una sesión guardada en la app
- Choose Model Options In Regression Learner
- Selección y transformación de características mediante la app Regression Learner
- Export Plots in Regression Learner App
- Export Regression Model to Predict New Data
- Train Regression Trees Using Regression Learner App