cvpartition
Partición de datos para validación cruzada
Descripción
cvpartition define una partición aleatoria en un conjunto de datos. Utilice esta partición para definir conjuntos de entrenamiento y prueba para validar un modelo estadístico mediante la validación cruzada. Utilice training para extraer los índices de entrenamiento y test para extraer los índices de prueba para la validación cruzada. Utilice repartition para definir una nueva partición aleatoria del mismo tipo que un objeto cvpartition dado.
Si especifica una variable de estratificación o agrupación cuando crea un objeto cvpartition, puede usar summary para mostrar más información sobre la división de los datos.
Creación
Sintaxis
Descripción
c = cvpartition(n,KFold=k)cvpartition c que define una partición aleatoria no estratificada para la validación cruzada de k particiones sobre n observaciones. La partición divide aleatoriamente las observaciones en k submuestras inconexas, o particiones, cada una de las cuales tiene aproximadamente el mismo número de observaciones.
c = cvpartition(n,KFold=k,GroupingVariables=groupingVariables)c que define una partición aleatoria para la validación cruzada de k particiones. La función garantiza que las observaciones con la misma combinación de etiquetas de grupos, según lo especificado por groupingVariables, están en la misma partición. (desde R2025a)
Cuando se especifica groupingVariables, cvpartition descarta las filas de observaciones correspondientes a valores faltantes en groupingVariables.
c = cvpartition(stratvar,KFold=k)k particiones estratificada. Cada submuestra, o partición, tiene aproximadamente el mismo número de observaciones y contiene aproximadamente las mismas proporciones de clase que en stratvar.
Cuando se especifica stratvar como primer argumento de entrada, cvpartition descarta las filas de observaciones correspondientes a valores faltantes en stratvar.
c = cvpartition(stratvar,KFold=k,Stratify=stratifyOption)c que define una partición aleatoria para la validación cruzada de k particiones. Si especifica Stratify=false, cvpartition ignora la información de clase de stratvar y crea una partición aleatoria no estratificada. En caso contrario, la función aplica la estratificación de forma predeterminada.
c = cvpartition(stratvar,Holdout=p)stratvar. Tanto el conjunto de entrenamiento como el de prueba tienen aproximadamente las mismas proporciones de clase que en stratvar.
c = cvpartition(stratvar,Holdout=p,Stratify=stratifyOption)c que define una partición aleatoria en un conjunto de entrenamiento y un conjunto de prueba o retención. Si especifica Stratify=false, cvpartition crea una partición aleatoria no estratificada. En caso contrario, la función aplica la estratificación de forma predeterminada.
c = cvpartition(n,"Leaveout")n observaciones. La validación cruzada dejando una observación fuera es un caso especial de KFold en el que el número de particiones es igual al número de observaciones.
c = cvpartition( crea un objeto n,"Resubstitution")c que no realiza una partición de los datos. Tanto el conjunto de entrenamiento como el conjunto de prueba contienen todas las n observaciones originales.
Argumentos de entrada
Propiedades
Funciones del objeto
repartition | Repartition data for cross-validation |
summary | Summarize cross-validation partition with stratification or grouping variable |
test | Índices de prueba para la validación cruzada |
training | Índices de entrenamiento para la validación cruzada |
Ejemplos
Utilice el error de clasificación errónea de validación cruzada para estimar el rendimiento de un modelo con datos nuevos.
Cargue el conjunto de datos ionosphere. Cree una tabla que contenga los datos predictores X y la variable de respuesta Y.
load ionosphere
tbl = array2table(X);
tbl.Y = Y;Utilice una partición aleatoria no estratificada hpartition para dividir los datos en datos de entrenamiento (tblTrain) y un conjunto de datos reservados (tblNew). Reserve aproximadamente el 30% de los datos.
rng(0,"twister") % For reproducibility n = length(tbl.Y); hpartition = cvpartition(n,Holdout=0.3); idxTrain = training(hpartition); tblTrain = tbl(idxTrain,:); idxNew = test(hpartition); tblNew = tbl(idxNew,:);
Entrene un modelo de clasificación de máquina de vectores de soporte (SVM, por sus siglas en inglés) con los datos de entrenamiento tblTrain. Calcule el error de clasificación errónea y la precisión de clasificación en los datos de entrenamiento.
Mdl = fitcsvm(tblTrain,"Y");
trainError = resubLoss(Mdl)trainError = 0.0569
trainAccuracy = 1-trainError
trainAccuracy = 0.9431
Normalmente, el error de clasificación errónea en los datos de entrenamiento no es una buena estimación del rendimiento de un modelo en los nuevos datos porque puede subestimar la tasa de clasificación errónea en los nuevos datos. Una estimación mejor es el error de validación cruzada.
Cree un modelo particionado cvMdl. Calcule el error de clasificación errónea de la validación cruzada de 10 particiones y la precisión de la clasificación. De forma predeterminada, crossval garantiza que las proporciones de clase de cada partición sigan siendo aproximadamente las mismas que las proporciones de clase de la variable de respuesta tblTrain.Y.
cvMdl = crossval(Mdl); cvtrainError = kfoldLoss(cvMdl)
cvtrainError = 0.1220
cvtrainAccuracy = 1-cvtrainError
cvtrainAccuracy = 0.8780
Fíjese en que el error de validación cruzada cvtrainError es mayor que el error de resustitución trainError.
Clasifique los nuevos datos en tblNew usando el modelo SVM entrenado. Compare la precisión de la clasificación en los nuevos datos con las estimaciones de precisión trainAccuracy y cvtrainAccuracy.
newError = loss(Mdl,tblNew,"Y");
newAccuracy = 1-newErrornewAccuracy = 0.8700
El error de validación cruzada ofrece una mejor estimación del rendimiento del modelo en los nuevos datos que el error de resustitución.
Use la misma partición estratificada para la validación cruzada de 5 particiones y calcule las tasas de clasificación errónea de dos modelos.
Cargue el conjunto de datos fisheriris. La matriz meas contiene mediciones de 150 flores diferentes. La variable species enumera las especies de cada flor.
load fisheririsCree una partición aleatoria para la validación cruzada estratificada de 5 particiones. Los conjuntos de entrenamiento y prueba tienen aproximadamente las mismas proporciones de especies florales que species.
rng(0,"twister") % For reproducibility c = cvpartition(species,KFold=5);
Cree un modelo de análisis discriminante particionado y un modelo de árbol de clasificación particionado usando c.
discrCVModel = fitcdiscr(meas,species,CVPartition=c); treeCVModel = fitctree(meas,species,CVPartition=c);
Calcule las tasas de clasificación errónea de los dos modelos particionados.
discrRate = kfoldLoss(discrCVModel)
discrRate = 0.0200
treeRate = kfoldLoss(treeCVModel)
treeRate = 0.0600
El modelo de análisis discriminante tiene una menor tasa de clasificación errónea de validación cruzada.
Observe las proporciones de clase del conjunto de prueba (partición) en una partición no estratificada de 5 particiones de los datos de fisheriris. Las proporciones de clase difieren entre las particiones.
Cargue el conjunto de datos fisheriris. La variable species contiene el nombre de la especie (clase) de cada flor (observación). Convierta species en una variable categorical.
load fisheriris
species = categorical(species);Halle el número de observaciones de cada clase. Observe que las tres clases se dan en la misma proporción.
C = categories(species)
C = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
numClasses = size(C,1); n = countcats(species)
n = 3×1
50
50
50
Cree una partición aleatoria no estratificada de 5 particiones.
rng(0,"twister") % For reproducibility cv = cvpartition(species,KFold=5,Stratify=false)
cv =
K-fold cross validation partition
NumObservations: 150
NumTestSets: 5
TrainSize: [120 120 120 120 120]
TestSize: [30 30 30 30 30]
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
Muestre que las tres clases no aparecen en la misma proporción en cada uno de los cinco conjuntos de prueba o particiones. Utilice un bucle for para actualizar la matriz nTestData de modo que cada entrada nTestData(i,j) corresponda al número de observaciones del conjunto de prueba i y la clase C(j). Cree una gráfica de barras a partir de los datos de nTestData.
numFolds = cv.NumTestSets; nTestData = zeros(numFolds,numClasses); for i = 1:numFolds testClasses = species(cv.test(i)); nCounts = countcats(testClasses); nTestData(i,:) = nCounts'; end bar(nTestData) xlabel("Test Set (Fold)") ylabel("Number of Observations") title("Nonstratified Partition") legend(C)
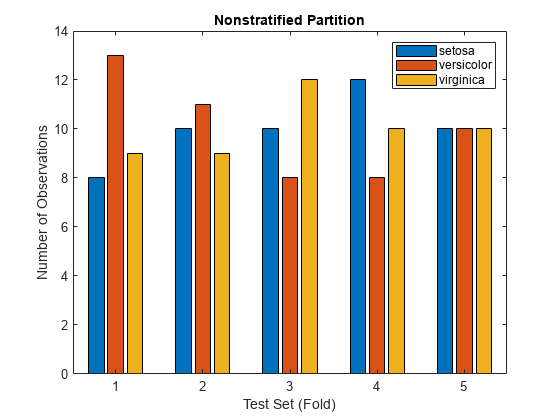
Observe que las proporciones de clase varían en algunos de los conjuntos de prueba. Por ejemplo, el primer conjunto de prueba contiene 8 flores de setosa, 13 de versicolor y 9 de virginica, en lugar de 10 flores por especie. Dado que cv es una partición aleatoria no estratificada de los datos de fisheriris, no se garantiza que las proporciones de clase de cada conjunto de prueba (partición) sean iguales a las proporciones de clase de species. Es decir, las clases no siempre aparecen por igual en cada conjunto de prueba, como ocurre en species.
Desde R2025a
Cree un objeto cvpartition usando una variable de agrupación. Muestre un resumen de la validación cruzada.
Cargue los datos sobre casos de tsunamis y cree una tabla a partir de los datos. Muestre las primeras ocho observaciones de la tabla.
Tbl = readtable("tsunamis.xlsx");
head(Tbl) Latitude Longitude Year Month Day Hour Minute Second ValidityCode Validity CauseCode Cause EarthquakeMagnitude Country Location MaxHeight IidaMagnitude Intensity NumDeaths DescDeaths
________ _________ ____ _____ ___ ____ ______ ______ ____________ _________________________ _________ __________________ ___________________ ___________________ __________________________ _________ _____________ _________ _________ __________
-3.8 128.3 1950 10 8 3 23 NaN 2 {'questionable tsunami' } 1 {'Earthquake' } 7.6 {'INDONESIA' } {'JAVA TRENCH, INDONESIA'} 2.8 1.5 1.5 NaN NaN
19.5 -156 1951 8 21 10 57 NaN 4 {'definite tsunami' } 1 {'Earthquake' } 6.9 {'USA' } {'HAWAII' } 3.6 1.8 NaN NaN NaN
-9.02 157.95 1951 12 22 NaN NaN NaN 2 {'questionable tsunami' } 6 {'Volcano' } NaN {'SOLOMON ISLANDS'} {'KAVACHI' } 6 2.6 NaN NaN NaN
42.15 143.85 1952 3 4 1 22 41 4 {'definite tsunami' } 1 {'Earthquake' } 8.1 {'JAPAN' } {'SE. HOKKAIDO ISLAND' } 6.5 2.7 2 33 1
19.1 -155 1952 3 17 3 58 NaN 4 {'definite tsunami' } 1 {'Earthquake' } 4.5 {'USA' } {'HAWAII' } 1 NaN NaN NaN NaN
43.1 -82.4 1952 5 6 NaN NaN NaN 1 {'very doubtful tsunami'} 9 {'Meteorological'} NaN {'USA' } {'LAKE HURON, MI' } 1.52 NaN NaN NaN NaN
52.75 159.5 1952 11 4 16 58 NaN 4 {'definite tsunami' } 1 {'Earthquake' } 9 {'RUSSIA' } {'KAMCHATKA' } 18 4.2 4 2236 3
50 156.5 1953 3 18 NaN NaN NaN 3 {'probable tsunami' } 1 {'Earthquake' } 5.8 {'RUSSIA' } {'N. KURIL ISLANDS' } 1.5 0.6 NaN NaN NaN
Cree una partición aleatoria no estratificada para la validación cruzada de cinco particiones en las observaciones de Tbl. Asegúrese de que las observaciones con el mismo valor de Country están en la misma partición usando el argumento nombre-valor GroupingVariables.
rng(0,"twister") % For reproducibility c = cvpartition(size(Tbl,1),KFold=5, ... GroupingVariables=Tbl.Country)
c =
Group k-fold cross validation partition
NumObservations: 162
NumTestSets: 5
TrainSize: [126 130 130 131 131]
TestSize: [36 32 32 31 31]
IsCustom: 0
IsGrouped: 1
IsStratified: 0
Properties, Methods
c es un objeto cvpartition. El valor de la propiedad IsGrouped es 1 (true), lo que indica que se usó al menos una variable de agrupación para crear el objeto.
Muestre un resumen del objeto cvpartition c.
summaryTbl = summary(c)
summaryTbl=150×5 table
Set SetSize GroupLabel GroupCount PercentInSet
________ _______ ___________________ __________ ____________
"train1" 126 {'INDONESIA' } 25 19.841
"train1" 126 {'USA' } 15 11.905
"train1" 126 {'SOLOMON ISLANDS'} 10 7.9365
"train1" 126 {'JAPAN' } 19 15.079
"train1" 126 {'RUSSIA' } 19 15.079
"train1" 126 {'FIJI' } 1 0.79365
"train1" 126 {'GREENLAND' } 1 0.79365
"train1" 126 {'CHILE' } 6 4.7619
"train1" 126 {'GREECE' } 5 3.9683
"train1" 126 {'ECUADOR' } 1 0.79365
"train1" 126 {'VANUATU' } 5 3.9683
"train1" 126 {'TONGA' } 1 0.79365
"train1" 126 {'PHILIPPINES' } 7 5.5556
"train1" 126 {'CANADA' } 1 0.79365
"train1" 126 {'ATLANTIC OCEAN' } 1 0.79365
"train1" 126 {'FRANCE' } 1 0.79365
⋮
La primera fila de summaryTbl muestra que 25 de las 126 observaciones del primer conjunto de entrenamiento Tbl(training(c,1),:) (aproximadamente un 20%) tienen INDONESIA como valor de Country. El software garantiza que el primer conjunto de prueba Tbl(test(c,1),:) no contiene ninguna observación con este valor.
Compruebe los valores de Country en las observaciones del primer conjunto de prueba.
summaryTest1 = summaryTbl(summaryTbl.Set=="test1",:)summaryTest1=6×5 table
Set SetSize GroupLabel GroupCount PercentInSet
_______ _______ ____________________ __________ ____________
"test1" 36 {'PAPUA NEW GUINEA'} 13 36.111
"test1" 36 {'MEXICO' } 8 22.222
"test1" 36 {'PERU' } 9 25
"test1" 36 {'JAPAN SEA' } 1 2.7778
"test1" 36 {'MONTSERRAT' } 4 11.111
"test1" 36 {'TURKEY' } 1 2.7778
Como se esperaba, el primer conjunto de prueba no contiene ninguna observación con INDONESIA como valor de Country.
Cree una partición de retención no estratificada y una estratificada para un arreglo alto. En los dos conjuntos de retención, compare el número de observaciones de cada clase.
Cuando realiza cálculos en arreglos altos, MATLAB® utiliza un grupo paralelo (el valor predeterminado si dispone de Parallel Computing Toolbox™) o la sesión local de MATLAB. Para ejecutar el ejemplo utilizando la sesión local de MATLAB cuando se dispone de Parallel Computing Toolbox, cambie el entorno de ejecución global con la función mapreducer.
mapreducer(0)
Cree un vector numérico de dos clases donde la clase 1 y la clase 2 se den en la proporción 1:10.
group = [ones(20,1);2*ones(200,1)]
group = 220×1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
⋮
Cree un arreglo alto de group.
tgroup = tall(group)
tgroup =
220×1 tall double column vector
1
1
1
1
1
1
1
1
:
:
Holdout es la única opción de cvpartition que se admite para arreglos altos. Cree una partición de retención aleatoria no estratificada.
CV0 = cvpartition(tgroup,Holdout=1/4,Stratify=false)
CV0 =
Hold-out cross validation partition
NumObservations: [M×N×... tall]
NumTestSets: 1
TrainSize: [M×N×... tall]
TestSize: [M×N×... tall]
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
Devuelva el resultado de CV0.test a la memoria mediante la función gather.
testIdx0 = gather(CV0.test);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.32 sec Evaluation completed in 0.42 sec
Calcule el número de veces que cada clase aparece en el conjunto de prueba o retención.
accumarray(group(testIdx0),1)
ans = 2×1
5
51
cvpartition produce aleatoriedad en los resultados, por lo que su número de observaciones en cada clase puede variar respecto a los que se muestran.
Dado que CV0 es una partición no estratificada, no se garantiza que las observaciones de la clase 1 y las observaciones de la clase 2 en el conjunto de retención se produzcan en la misma proporción que en tgroup. Sin embargo, debido a la aleatoriedad inherente en cvpartition, a veces se puede obtener un conjunto de retención en el que las clases ocurran en la misma proporción que en tgroup, aunque se especifique Stratify=false. Como el conjunto de entrenamiento es el complemento del conjunto de retención, excluyendo cualquier valor NaN u observación que falte, puede obtener un resultado similar para el conjunto de entrenamiento.
Devuelva el resultado de CV0.training a la memoria.
trainIdx0 = gather(CV0.training);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.12 sec Evaluation completed in 0.16 sec
Calcule el número de veces que aparece cada clase en el conjunto de entrenamiento.
accumarray(group(trainIdx0),1)
ans = 2×1
15
149
No se garantiza que las clases del conjunto de entrenamiento no estratificado aparezcan en la misma proporción que en tgroup.
Cree una partición de retención estratificada aleatoria.
CV1 = cvpartition(tgroup,Holdout=1/4)
CV1 =
Hold-out cross validation partition
NumObservations: [M×N×... tall]
NumTestSets: 1
TrainSize: [M×N×... tall]
TestSize: [M×N×... tall]
IsCustom: 0
IsGrouped: 0
IsStratified: 1
Properties, Methods
Devuelva el resultado de CV1.test a la memoria.
testIdx1 = gather(CV1.test);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.066 sec Evaluation completed in 0.083 sec
Calcule el número de veces que cada clase aparece en el conjunto de prueba o retención.
accumarray(group(testIdx1),1)
ans = 2×1
5
51
En el caso de la partición de retención estratificada, la proporción de clase en el conjunto de retención y la proporción de clase en tgroup son iguales (1:10).
Cree una partición aleatoria de datos para la validación cruzada dejando una observación fuera. Calcule y compare las medias del conjunto de entrenamiento. Si una repetición tiene una media significativamente diferente, esto sugiere la presencia de una observación influyente.
Cree un conjunto de datos X que contenga un valor que sea mucho mayor que los demás.
X = [1 2 3 4 5 6 7 8 9 20]';
Cree un objeto cvpartition que tenga 10 observaciones y 10 repeticiones de datos de entrenamiento y de prueba. En cada repetición, cvpartition selecciona una observación para eliminarla del conjunto de entrenamiento y reservarla para el conjunto de prueba.
c = cvpartition(10,"Leaveout")c =
Leave-one-out cross validation partition
NumObservations: 10
NumTestSets: 10
TrainSize: [9 9 9 9 9 9 9 9 9 9]
TestSize: [1 1 1 1 1 1 1 1 1 1]
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
Aplique la partición dejando una observación fuera a X y tome la media de las observaciones de entrenamiento para cada repetición mediante crossval.
values = crossval(@(Xtrain,Xtest)mean(Xtrain),X,Partition=c)
values = 10×1
6.5556
6.4444
7.0000
6.3333
6.6667
7.1111
6.8889
6.7778
6.2222
5.0000
Visualice la distribución de las medias del conjunto de entrenamiento mediante un diagrama de caja (o gráfica de caja). La gráfica muestra un valor atípico.
boxchart(values)

Busque la repetición correspondiente al valor atípico. En esa repetición, busque la observación del conjunto de prueba.
[~,repetitionIdx] = min(values)
repetitionIdx = 10
observationIdx = test(c,repetitionIdx); influentialObservation = X(observationIdx)
influentialObservation = 20
Los conjuntos de entrenamiento que contienen la observación tienen medias sustancialmente diferentes de la media del conjunto de entrenamiento sin la observación. Este cambio significativo en la media sugiere que el valor de 20 en X es una observación influyente.
Cree un árbol de regresión de validación cruzada especificando una partición de validación cruzada de 4 particiones personalizada.
Cargue el conjunto de datos carbig. Cree una tabla Tbl que contenga la variable de respuesta MPG y las variables predictoras Acceleration, Cylinders, etc.
load carbig Tbl = table(Acceleration,Cylinders,Displacement, ... Horsepower,Model_Year,Weight,Origin,MPG);
Elimine las observaciones con valores faltantes. Compruebe el tamaño de los datos de la tabla después de eliminar las observaciones con valores faltantes.
Tbl = rmmissing(Tbl); dimensions = size(Tbl)
dimensions = 1×2
392 8
La tabla resultante contiene 392 observaciones, donde .
Cree una partición personalizada de validación cruzada de 4 particiones de los datos de Tbl. Coloque las primeras 98 observaciones en el primer conjunto de prueba, las siguientes 98 observaciones en el segundo conjunto de prueba y así sucesivamente.
testSet = ones(98,1);
testIndices = [testSet; 2*testSet; ...
3*testSet; 4*testSet];
c = cvpartition(CustomPartition=testIndices)c =
K-fold cross validation partition
NumObservations: 392
NumTestSets: 4
TrainSize: [294 294 294 294]
TestSize: [98 98 98 98]
IsCustom: 1
IsGrouped: 0
IsStratified: 0
Properties, Methods
Entrene un árbol de regresión con validación cruzada utilizando la partición personalizada c. Para evaluar el rendimiento del modelo, calcule el error cuadrático medio (MSE) de la validación cruzada.
cvMdl = fitrtree(Tbl,"MPG",CVPartition=c);
cvMSE = kfoldLoss(cvMdl)cvMSE = 21.2223
Sugerencias
Si especifica
stratvarcomo primer argumento de entrada acvpartition, la función descarta las filas de observaciones correspondientes a valores faltantes enstratvar. De manera similar, si especifica una o más variables de agrupación usandogroupingVariables, la función descarta las filas de observaciones correspondientes a valores faltantes engroupingVariables.Si especifica
stratvarcomo primer argumento de entrada acvpartition, la función aplica la estratificación de forma predeterminada. Puede especificarStratify=falsepara crear una partición aleatoria no estratificada.Puede especificar
Stratify=truesolo cuando el primer argumento de entrada acvpartitionesstratvar.