Visualización de datos multivariados
En este ejemplo se muestra cómo visualizar datos multivariados utilizando varias gráficas estadísticas. Muchos análisis estadísticos incluyen dos variables únicamente: una variable de predicción y una variable de respuesta. Estos datos pueden visualizarse fácilmente con gráficas de dispersión en 2D, histogramas bivariables, gráficas de caja, etc. También se pueden visualizar datos de tres variables con gráficas de dispersión en 3D, o gráficas de dispersión en 2D con una tercera variable codificada, por ejemplo, en otro color. Sin embargo, muchos conjuntos de datos incluyen un número de variables mayor, lo que hace más difícil la visualización directa. Este ejemplo explora algunos de los modos en los que visualizar datos de altas dimensiones en MATLAB®, utilizando Statistics and Machine Learning Toolbox™.
En este ejemplo, utilizaremos el conjunto de datos carbig, que contiene varias variables medidas de aproximadamente 400 automóviles de las décadas de 1970 y 1980. Ilustraremos la visualización multivariable utilizando las variables de eficiencia de combustible (en millas por galón, MPG), aceleración (0 a 60 millas por hora en segundos), cilindrada del motor (en pulgadas cúbicas), peso y potencia. Utilizaremos el número de cilindros para las observaciones de grupo.
load carbig X = [MPG,Acceleration,Displacement,Weight,Horsepower]; varNames = {'MPG'; 'Acceleration'; 'Displacement'; 'Weight'; 'Horsepower'};
Matrices de las gráficas de dispersión
La visualización de porciones a través de subespacios de menor dimensión es una forma de evitar parcialmente la limitación de dos o tres dimensiones. Por ejemplo, podemos utilizar la función gplotmatrix para mostrar un arreglo de todas las gráficas de dispersión bivariadas entre nuestras cinco variables, junto con un histograma univariado para cada variable.
figure gplotmatrix(X,[],Cylinders,['c' 'b' 'm' 'g' 'r'],[],[],false); text([.08 .24 .43 .66 .83], repmat(-.1,1,5), varNames, 'FontSize',8); text(repmat(-.12,1,5), [.86 .62 .41 .25 .02], varNames, 'FontSize',8, 'Rotation',90);

Los puntos de cada gráfica de dispersión están codificados por colores según el número de cilindros: azul para 4 cilindros, verde para 6 y rojo para 8. También hay varios coches de 5 cilindros y coches con motor rotativo que figuran como de 3 cilindros. Este arreglo de gráficas facilita elegir patrones en las relaciones entre pares de variables. Sin embargo, puede haber patrones importantes en dimensiones superiores que no resultan fáciles de reconocer en esta gráfica.
Gráficas de coordenadas paralelas
La matriz de gráficas de dispersión muestra relaciones bivariables. Existen otras alternativas que muestran todas las variables juntas, que permiten investigar relaciones de mayor dimensión entre las variables. La gráfica multivariable más directa es la gráfica de coordenadas paralelas. En esta gráfica, los ejes de coordenadas se sitúan horizontalmente en lugar de utilizar los ejes ortogonales como ocurre en la gráfica cartesiana estándar. Cada observación se representa en la gráfica como una serie de segmentos lineales conectados. Por ejemplo, podemos crear una gráfica con los coches con 4, 6 u 8 cilindros y observaciones de color por grupo.
Cyl468 = ismember(Cylinders,[4 6 8]); parallelcoords(X(Cyl468,:), 'group',Cylinders(Cyl468), ... 'standardize','on', 'labels',varNames)

La dirección horizontal de esta gráfica representa los ejes de coordenadas, y la dirección vertical representa los datos. Cada observación se realiza con medidas de cinco variables, y cada medida se representa como la altura a la que cada línea correspondiente cruza cada eje de coordenadas. Puesto que las cinco variables tienen distintos rangos, esta gráfica se realizó con valores estandarizados, en los que cada variable se ha estandarizado para tener cero medias y variaciones de unidades. Con el código de color, la gráfica muestra, por ejemplo, que los coches de 8 cilindros normalmente tienen valores bajos de millas por galón y aceleración, y valores altos de cilindrada, peso y potencia.
Incluso con la asignación de colores en los grupos, una gráfica de coordenadas paralelas con un número alto de observaciones puede resultar difícil de leer. También podemos crear una gráfica de coordenadas paralelas en la que solo se muestren la media y los cuartiles (25% y 75%) de cada grupo. Esto hace que sea más fácil distinguir las típicas diferencias y similitudes entre grupos. Por otra parte, puede que los valores atípicos sean los más interesantes y, sin embargo, no se muestran en este tipo de gráfica.
parallelcoords(X(Cyl468,:), 'group',Cylinders(Cyl468), ... 'standardize','on', 'labels',varNames, 'quantile',.25)

Gráficas de Andrew
Otro tipo de visualización multivariable es la gráfica de Andrew. Esta gráfica representa cada observación como una función suave sobre el intervalo [0,1].
andrewsplot(X(Cyl468,:), 'group',Cylinders(Cyl468), 'standardize','on')

Cada función es una serie de Fourier, con coeficientes que equivalen a los valores de observación correspondientes. En este ejemplo, la serie tiene cinco términos: una constante, dos términos de seno con periodos 1 y 1/2 y dos términos de coseno similares. Los efectos en las formas de las funciones debidos a los tres términos principales son los más evidentes en una gráfica de Andrews, por lo que los patrones en las tres primeras variables tienden a ser los más fáciles de reconocer.
Hay una clara diferencia entre los grupos en t = 0, lo que indica que la primera variable, MPG, es una de las características distintivas entre los coches de 4, 6 y 8 cilindros. Resulta más interesante la diferencia entre los tres grupos alrededor de t = 1/3. Introduciendo este valor en la fórmula de las funciones gráficas de Andrews, obtenemos un conjunto de coeficientes que definen una combinación lineal de las variables que distingue entre grupos.
t1 = 1/3; [1/sqrt(2) sin(2*pi*t1) cos(2*pi*t1) sin(4*pi*t1) cos(4*pi*t1)]
ans =
0.7071 0.8660 -0.5000 -0.8660 -0.5000
A partir de estos coeficientes, podemos ver que una forma de distinguir los coches de 4 cilindros de los de 8 cilindros es que los primeros tienen valores más altos de MPG y aceleración, y valores más bajos de cilindrada, potencia y, sobre todo, peso, mientras que los segundos tienen lo contrario. Es la misma conclusión que extrajimos de la gráfica de coordenadas paralelas.
Gráficas de glifo
Otra manera de visualizar los datos multivariables es utilizar "glifos" para representar las dimensiones. La función glyphplot es compatible con dos tipos de glifos: estrellas y caras de Chernoff. Por ejemplo, aquí hay una gráfica de estrella de los primeros 9 modelos de coches. Cada radio de la estrella representa una variable, y la longitud del radio es proporcional al valor de esa variable para esa observación.
h = glyphplot(X(1:9,:), 'glyph','star', 'varLabels',varNames, 'obslabels',Model(1:9,:)); set(h(:,3),'FontSize',8);

En una ventana de figuras de MATLAB en vivo, este gráfico permitiría la exploración interactiva de los valores de los datos, utilizando cursores de datos. Por ejemplo, si se hace clic en el punto derecho de la estrella del Ford Torino se verá que tiene un valor de MPG de 17.
Gráficas de glifo y escalas multidimensionales
Representar las estrellas en una cuadrícula, sin un orden determinado, puede dar lugar a una figura confusa, ya que las estrellas adyacentes pueden tener un aspecto muy diferente. Por lo tanto, puede que no haya un patrón suave que detectar. A menudo resulta útil combinar el escalado multidimensional (MDS) con una gráfica de glifos. Para ilustrar este ejemplo, seleccionaremos primero todos los coches de 1977, y utilizaremos la función zscore para estandarizar cada una de las cinco variables para tener una media de cero y varianza de unidad. Después calcularemos las distancias euclídeas entre las observaciones estandarizadas como medidas de diferenciación. Esta elección puede resultar demasiado simple en una aplicación real, pero sirve para ilustrar el ejemplo.
models77 = find((Model_Year==77)); dissimilarity = pdist(zscore(X(models77,:)));
Finalmente, utilizaremos mdscale para crear un conjunto de ubicaciones en dos dimensiones cuyas distancias entre puntos se aproximen a las diferencias entre los datos originales de alta dimensión, y trazar los glifos utilizando esas ubicaciones. Las distancias en esta gráfica 2D pueden reproducir los datos solo de manera aproximada, pero para este tipo de gráfica es suficiente.
Y = mdscale(dissimilarity,2); glyphplot(X(models77,:), 'glyph','star', 'centers',Y, ... 'varLabels',varNames, 'obslabels',Model(models77,:), 'radius',.5); title('1977 Model Year');

En esta gráfica, hemos utilizado MDS como un método de reducción de dimensión para crear una gráfica en 2D. Normalmente eso significaría una pérdida de información, pero al trazar los glifos, hemos incorporado toda la información de alta dimensión de los datos. El propósito de utilizar el MDS es imponer cierta regularidad a la variación de los datos, para que los patrones entre los glifos sean más fáciles de ver.
Al igual que con la gráfica anterior, una exploración interactiva resultaría posible en una ventana de figuras.
Otro tipo de glifo es la cara de Chernoff. Este glifo representa los valores de los datos de cada observación en rasgos faciales, como el tamaño de la cara, la forma del rostro, la posición de los ojos, etc.
glyphplot(X(models77,:), 'glyph','face', 'centers',Y, ... 'varLabels',varNames, 'obslabels',Model(models77,:)); title('1977 Model Year');
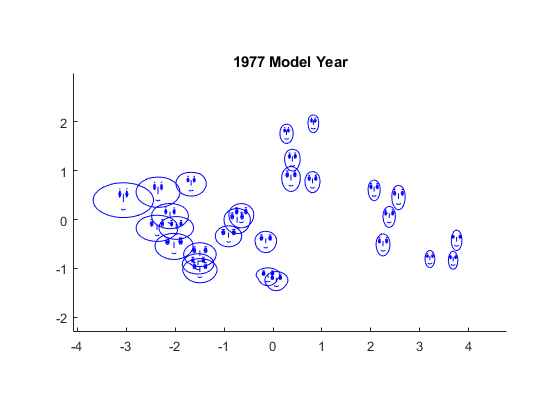
En este caso, los dos rasgos más aparentes, el tamaño de la cara y el tamaño relativo de la frente y la mandíbula, representan las MPG y la aceleración, mientras que la forma de la frente y la mandíbula corresponden a la cilindrada y al peso. La distancia entre los ojos simboliza la potencia. Llama la atención que haya pocas caras con frentes anchas y mandíbulas estrechas, o viceversa, lo que indica una correlación lineal positiva entre las variables cilindrada y peso. Eso es también lo que vimos en la gráfica de dispersión.
La correspondencia de las características con las variables determina qué relaciones son más fáciles de ver, y glyphplot permite cambiar la selección fácilmente.
close