detect
Syntax
Description
Add-On Required: This feature requires the Computer Vision Toolbox Model for RetinaFace Face Detection add-on.
bboxes = detect(detector,I)I, using a
pretrained RetinaFace face detector, detector. The
detect function returns the locations of detected faces in the input
image as a set of bounding boxes.
Note
This functionality requires Deep Learning Toolbox™ and the Computer Vision Toolbox™ Model for RetinaFace Face Detection. You can install the Computer Vision Toolbox Model for RetinaFace Face Detection from Add-On Explorer. For more information about installing add-ons, see Get and Manage Add-Ons.
detectionResults = detect(detector,ds)ds.
[___] = detect(___,
detects faces within the rectangular region of interest roi)roi, in
addition to any combination of arguments from previous syntaxes.
[___] = detect(___,
specifies options using one or more name-value arguments. For example,
Name=Value)Threshold=0.75 specifies a detection threshold of 0.75.
Examples
Read an input image into the MATLAB® workspace.
I = imread("visionteam1.jpg");Create a face detector object using the faceDetector function. The default configuration of the object loads a small, pretrained RetinaFace deep learning detector for face detection. The small network uses MobileNet-0.25 as the backbone network.
detector = faceDetector
detector =
faceDetector with properties:
ModelName: "small-network"
ClassNames: face
InputSize: [640 640]
Detect faces in the image using the detect function of the faceDetector object. The detect function returns bounding boxes, detection scores, and labels for the detected faces.
[bboxes,scores,labels] = detect(detector,I);
Overlay bounding boxes, labels, and scores on the image using the insertObjectAnnotation function.
detectedImg = insertObjectAnnotation(I,"rectangle",bboxes,scores);Display the detection results.
table(bboxes,scores,labels)
ans=6×3 table
bboxes scores labels
________________________ _______ ______
571 70 38 61 0.99237 face
333 99 31 40 0.98568 face
217 122 21 31 0.96641 face
107 124 37 47 0.99897 face
510 128 29 38 0.97089 face
648 132 26 38 0.99424 face
figure imshow(detectedImg)

Create a face detector object using the faceDetector function. Specify the detector name as "large-network". This configuration loads a pretrained RetinaFace face detector with ResNet-50 as the backbone network for face detection. The network has many layers and offers improved detection accuracy.
detector = faceDetector("large-network")detector =
faceDetector with properties:
ModelName: "large-network"
ClassNames: face
InputSize: [640 640]
Read an input image into the MATLAB® workspace.
I = imread("boats.png");Specify a region of interest (ROI) in the image to detect faces.
roi = [5 400 400 200];
Display the image and the ROI.
roiImg = insertObjectAnnotation(I,"rectangle",roi,"ROI"); figure imshow(roiImg)

Detect faces in the specified ROI using the detect function of the faceDetector object.
[bboxes,scores,labels] = detect(detector,I,roi);
Display the computed bounding boxes, scores, and the corresponding labels as a table.
table(bboxes,scores,labels)
ans=2×3 table
bboxes scores labels
________________________ _______ ______
253 551 7 10 0.94679 face
222 557 7 10 0.9767 face
Overlay bounding boxes and scores on the image using the insertObjectAnnotation function.
detectedImg = insertObjectAnnotation(roiImg,"rectangle",bboxes,scores);Display the detection results.
figure imshow(detectedImg)

Create a face detector object using the faceDetector function. Specify the detector name as "large-network". This configuration loads a pretrained RetinaFace face detector with ResNet-50 as the backbone network for face detection.
detector = faceDetector("large-network");Create a VideoReader object to read video data from a video file.
reader = VideoReader('handshake_right.avi');Configure a VideoPlayer object to display the video frames and the face detection results.
videoPlayer = vision.VideoPlayer(Position=[0 0 400 400]);
Read and iterate over each frame in the video using a while loop. Perform these steps to detect faces and display the detection results.
Step 1: Read the current video frame with the
readFramefunction of theVideoReaderobject.Step 2: Detect faces in the video frame using the
detectfunction of thefaceDetectorobject. Thedetectfunction returns bounding boxes and detection scores for the detected faces.Step 3: Overlay bounding boxes and scores on the video frame using the
insertObjectAnnotationfunction.Step 4: Display the annotated frame using the
stepfunction of theVideoPlayerobject.
while hasFrame(reader) % Step 1 % videoFrame = readFrame(reader); % Step 2 % [bboxes,scores] = detect(detector,videoFrame); % Step 3 % videoFrame= insertObjectAnnotation(videoFrame,"rectangle",bboxes,scores); % Step 4 % step(videoPlayer,videoFrame) end
Call the release function to free up the resources allocated to the VideoPlayer object.
release(videoPlayer)

Create a face detector object using the faceDetector function. By default, the function uses the RetinaFace detector with a small backbone network for face detection.
detector = faceDetector;
Create a VideoReader object to read video data from a video file.
reader = VideoReader('tilted_face.avi');Configure a VideoPlayer object to display the video frames and the face detection results.
videoPlayer = vision.VideoPlayer(Position=[0 0 600 600]);
Read and iterate over each frame in the video using a while loop. Perform these steps to detect faces and display the detection results.
Step 1: Read the current video frame with the
readFramefunction of theVideoReaderobject.Step 2: Detect faces in the video frame using the
detectfunction of thefaceDetectorobject. Thedetectfunction returns bounding boxes for the detected faces.Step 3: If the current frame has detected faces, use the helper function
helperBlurFacesto blur the faces in the frame. The helper function applies Gaussian filtering to blur the areas of the frame defined by the bounding boxes. This effectively obscures the detected faces.Step 4: Display the processed frame using the
stepfunction of theVideoPlayerobject.
while hasFrame(reader) % Step 1 % videoFrame = readFrame(reader); % Step 2 % bboxes = detect(detector,videoFrame,Threshold=0.2); % Step 3 % if ~isempty(bboxes) videoFrame = helperBlurFaces(videoFrame,bboxes); end % Step 4 % step(videoPlayer,videoFrame) end
Call the release function to free up the resources allocated to the VideoPlayer object.
release(videoPlayer)
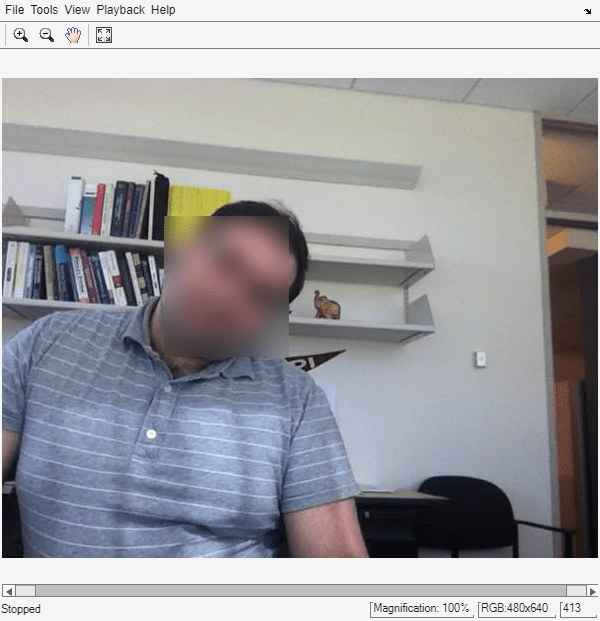
The helperBlurFaces function applies Gaussian filtering to the regions defined by each bounding box, which correspond to detected faces.
function I = helperBlurFaces(I,bbox) for j=1:size(bbox,1) xbox = round(bbox(j,:)); subImage = imcrop(I,xbox); blurred = imgaussfilt(subImage,12); I(xbox(2):xbox(2)+xbox(4),xbox(1):xbox(1)+xbox(3),1:end) = blurred; end end
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Deng, Jiankang, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. “RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild.” In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5202–11. Seattle, WA, USA: IEEE, 2020. https://doi.org/10.1109/CVPR42600.2020.00525.
[2] Yang, Shuo, Ping Luo, Chen Change Loy, and Xiaoou Tang. “WIDER FACE: A Face Detection Benchmark.” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5525–33. Las Vegas, NV, USA: IEEE, 2016. https://doi.org/10.1109/CVPR.2016.596.
Extended Capabilities
Version History
Introduced in R2025a