Esta página es para la versión anterior. La página correspondiente en inglés ha sido eliminada en la versión actual.
Cómo funcionan las redes neuronales dinámicas
Redes neuronales prealimentadas y recurrentes
Las redes dinámicas pueden dividirse en dos categorías: las que tienen solo conexiones prealimentadas y las que tienen conexiones con retroalimentación o recurrentes. Para entender las diferencias entre las redes estáticas, dinámicas prealimentadas y dinámicas recurrentes, cree algunas redes y observe cómo responden a una secuencia de entrada. (En primer lugar, tal vez desee revisar ).
Los siguientes comandos crean una secuencia de entrada de pulsos y la representan:
p = {0 0 1 1 1 1 0 0 0 0 0 0};
stem(cell2mat(p))
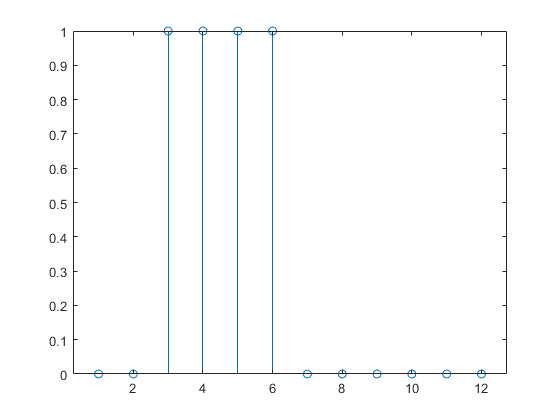
Ahora, cree una red estática y encuentre la respuesta de red a la secuencia de pulsos. Los siguientes comandos crean una red lineal sencilla con una capa, una neurona, sin sesgos y un peso de 2:
net = linearlayer;
net.inputs{1}.size = 1;
net.layers{1}.dimensions = 1;
net.biasConnect = 0;
net.IW{1,1} = 2;
view(net)

Ahora puede simular la respuesta de la red a la entrada de pulsos y representarla:
a = net(p); stem(cell2mat(a))
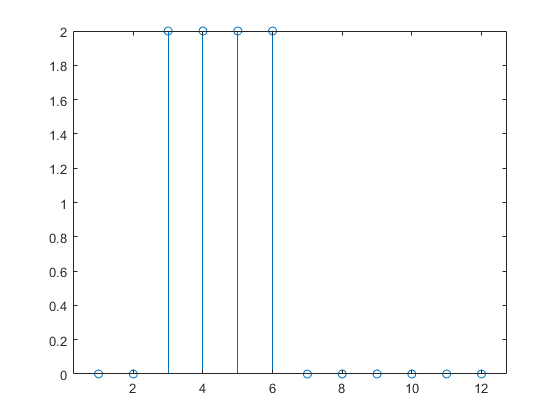
Tenga en cuenta que la respuesta de la red estática dura tanto como el pulso de entrada. La respuesta de la red estática en cualquier punto de tiempo depende únicamente del valor de la secuencia de entrada en ese mismo punto de tiempo.
Ahora, cree una red dinámica, pero una que no tenga conexiones de retroalimentación (una red no recurrente). Puede usar la misma red utilizada en , que era una red lineal con una línea de retardo en pulsación en la entrada:
net = linearlayer([0 1]);
net.inputs{1}.size = 1;
net.layers{1}.dimensions = 1;
net.biasConnect = 0;
net.IW{1,1} = [1 1];
view(net)

Puede volver a simular la respuesta de la red a la entrada de pulsos y representarla:
a = net(p); stem(cell2mat(a))
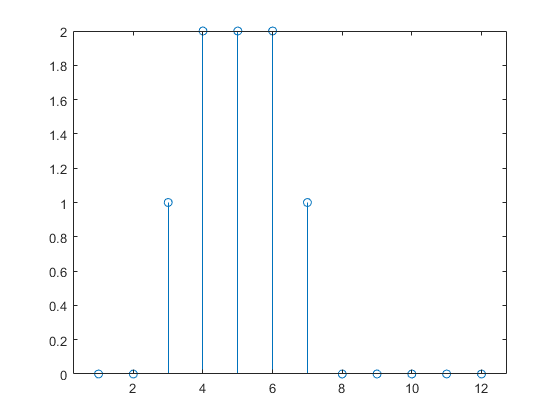
La respuesta de la red dinámica dura más que el pulso de entrada. La red dinámica tiene memoria. Su respuesta en cualquier momento dado depende no solo de la entrada actual, sino también del historial de la secuencia de entrada. Si la red no tiene conexiones de retroalimentación, solo una cantidad finita de historial afectará a la respuesta. En esta figura, puede ver que la respuesta al pulso dura una unidad de tiempo más que la duración del pulso. Esto se debe a que la línea de retardo en pulsación en la entrada tiene un retardo máximo de 1.
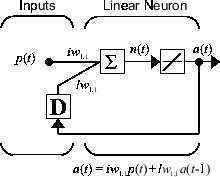
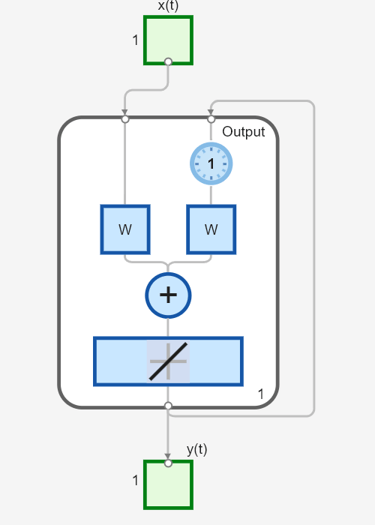
Ahora, considere una red dinámica recurrente sencilla, que se muestra en la siguiente figura.
Puede crear la red, verla y simularla con los siguientes comandos. El comando narxnet se explica en Diseñar redes neuronales de retroalimentación NARX para series de tiempo.
net = narxnet(0,1,[],'closed');
net.inputs{1}.size = 1;
net.layers{1}.dimensions = 1;
net.biasConnect = 0;
net.LW{1} = .5;
net.IW{1} = 1;
view(net)
Los siguientes comandos representan la respuesta de la red.
a = net(p); stem(cell2mat(a))

Observe que las redes dinámicas recurrentes suelen tener una respuesta más larga que las redes dinámicas prealimentadas. Para redes lineales, las redes dinámicas prealimentadas se llaman respuesta al impulso finita (FIR), ya que la respuesta a la entrada de un impulso se convertirá en cero después de una cantidad finita de tiempo. Las redes dinámicas recurrentes lineales se llaman respuesta al impulso infinita (IIR), ya que la respuesta a un impulso puede decaer hasta cero (para una red estable), pero nunca será exactamente igual a cero. No se puede definir una respuesta al impulso para una red no lineal, pero las ideas de respuestas finitas e infinitas sí se aplican.
Aplicaciones de las redes dinámicas
Por lo general, las redes dinámicas son más potentes que las redes estáticas (aunque son algo más difíciles de entrenar). Dado que las redes dinámicas tienen memoria, se pueden entrenar para aprender patrones secuenciales o patrones variables en el tiempo. Esto tiene aplicaciones en áreas tan distintas como la predicción en mercados financieros [RoJa96], la ecualización de canales en sistemas de comunicación [FeTs03], la detección de fases en sistemas de energía [KaGr96], la clasificación [JaRa04], la detección de fallos [ChDa99], el reconocimiento del habla [Robin94] e incluso la predicción de estructuras de proteínas en genética [GiPr02]. Puede encontrar información sobre muchas más aplicaciones de las redes dinámicas en [MeJa00].
Una aplicación principal de las redes neuronales dinámicas es en los sistemas de control. Esta aplicación se analiza con detalle en . Las redes dinámicas también son adecuadas para el filtrado. Verá el uso de algunas redes dinámicas lineales para filtrar y algunas de esas ideas se amplían en este tema usando redes dinámicas no lineales.
Estructuras de redes dinámicas
El software Deep Learning Toolbox™ está diseñado para entrenar una clase de red denominada red dinámica digital en capas (LDDN). Cualquier red que pueda disponerse en forma de una LDDN se puede entrenar con la toolbox. Aquí se muestra una descripción básica de las LDDN.
Cada capa de la LDDN está compuesta de las siguientes partes:
Conjunto de matrices de pesos que llegan a esa capa (que se pueden conectar desde otras capas o desde entradas externas), regla de funciones de peso asociadas utilizada para combinar la matriz de pesos con su entrada (normalmente multiplicación de matrices estándar,
dotprod) y línea de retardo en pulsación asociadaVector de sesgo
Regla de función de entrada combinada que se usa para combinar las salidas de distintas funciones de pesos con el sesgo para producir la entrada combinada (normalmente una unión de suma,
netprod)Función de transferencia
La red tiene entradas que están conectadas a pesos especiales, denominados pesos de entrada, y denotados por IWi,j (net.IW{i,j} en el código), donde j denota el número del vector de entrada que introduce el peso e i denota el número de la capa a la que se conecta el peso. Los pesos que conectan una capa a otra se llaman pesos de capa y están denotados por LWi,j (net.LW{i,j} en el código), donde j denota el número de la capa que llega al peso e i denota el número de la capa en la salida del peso.
La siguiente figura es un ejemplo de una LDDN de tres capas. La primera capa tiene tres pesos asociados a ella: un peso de entrada, un peso de capa desde la capa 1 y un peso de capa desde la capa 3. Los dos pesos de capa tienen líneas de retardo en pulsación asociadas a ellos.
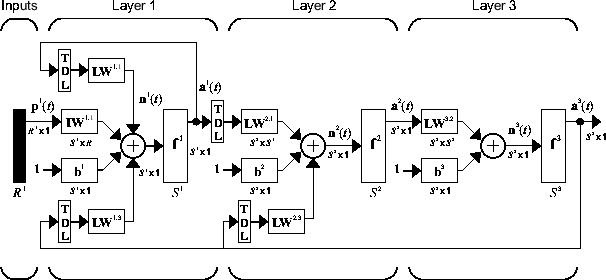
El software Deep Learning Toolbox se puede utilizar para entrenar cualquier LDDN, siempre que las funciones de peso, las funciones de entrada combinada y las funciones de transferencia tengan derivadas. La mayoría de las arquitecturas de redes dinámicas más conocidas se pueden representar con un formato LDDN. En el resto de este tema aprenderá a usar algunos comandos sencillos para crear y entrenar varias redes dinámicas muy potentes. Otras redes LDDN no recogidas en este tema se pueden crear usando el comando de red genérico, tal como se explica en .
Entrenamiento de redes dinámicas
Las redes dinámicas se entrenan en el software Deep Learning Toolbox usando los mismos algoritmos basados en gradientes que se describieron en Redes neuronales superficiales multicapa y entrenamiento de retropropagación. Puede seleccionar cualquiera de las funciones de entrenamiento que se presentaron en ese tema. Se proporcionan ejemplos en las siguientes secciones.
Aunque las redes dinámicas se pueden entrenar usando los mismos algoritmos basados en gradientes que se usan para las redes estáticas, el rendimiento de los algoritmos en redes dinámicas puede ser algo diferente y el gradiente debe calcularse de una manera más compleja. Considere de nuevo la red recurrente sencilla mostrada en esta figura.
Los pesos tienen dos efectos diferentes en la salida de red. El primero es el efecto directo, porque un cambio en el peso provoca un cambio inmediato en la salida en la unidad de tiempo actual. (El primer efecto se puede calcular usando retropropagación estándar). El segundo es un efecto indirecto, porque algunas de las entradas a la capa, como a(t − 1), también son funciones de los pesos. Para tener en cuenta este efecto indirecto, debe usar la retropropagación dinámica para calcular los gradientes, que requiere más cantidad de recursos computacionales. (Consulte [DeHa01a], [DeHa01b] y [DeHa07]). Puede que la retropropagación dinámica tarde más tiempo en entrenar, en parte debido a esta razón. Además, las superficies de error para redes dinámicas pueden ser más complejas que las de redes estáticas. Es más probable que el entrenamiento quede atrapado en mínimos locales. Esto sugiere que es posible que necesite entrenar la red varias veces para alcanzar un resultado óptimo. Consulte [DHH01] y [HDH09] para ver información sobre el entrenamiento de redes dinámicas.
El resto de secciones de este tema muestran cómo crear, entrenar y aplicar algunas redes dinámicas para los problemas de modelado, detección y pronóstico. Algunas de las redes requieren retropropagación dinámica para calcular gradientes y otras no. Como usuario, no es necesario que decida si es necesaria o no la retropropagación dinámica. Esto lo determina automáticamente el software, que también decide cuál es la mejor forma de retropropagación que se puede usar. Solo es necesario que cree la red y que después invoque el comando train estándar.