Entrenar un codificador automático variacional (VAE) para generar imágenes
En este ejemplo se muestra cómo entrenar un codificador automático variacional (VAE) de deep learning para generar imágenes.
Para generar datos que representen prominentemente observaciones en una colección de datos, puede utilizar un codificador automático variacional. Un codificador automático es un tipo de modelo entrenado para replicar su entrada transformando la entrada en un espacio dimensional menor (el paso de codificación) y reconstruir la entrada a partir de la representación dimensional menor (el paso de descodificación).
Este diagrama ilustra la estructura básica de un codificador automático que reconstruye imágenes de dígitos.
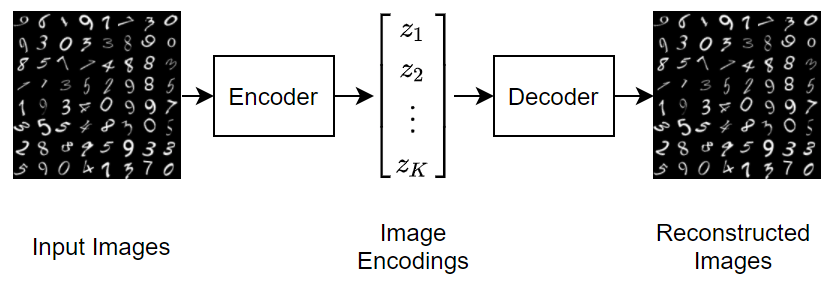
Para generar imágenes nuevas con un codificador automático variacional, introduzca vectores aleatorios en el descodificador.
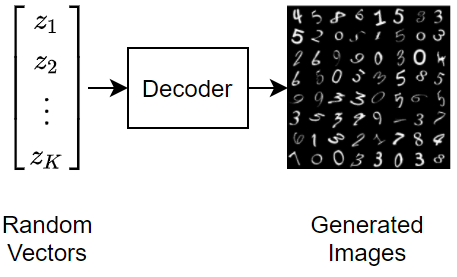
Un codificador automático variacional se diferencia de un codificador automático normal en que impone una distribución de probabilidad en el espacio latente y aprende la distribución para que la distribución de salidas del descodificador coincida con la de los datos observados. En particular, las salidas latentes se muestrean aleatoriamente de la distribución aprendida por el codificador.
Cargar datos
Cargue los datos de dígitos como arreglos numéricos en memoria usando las funciones digitTrain4DArrayData y digitTest4DArrayData. El conjunto de datos de dígitos está compuesto de 10.000 imágenes sintéticas a escala de grises de dígitos manuscritos. Cada imagen tiene 28 por 28 píxeles.
XTrain = digitTrain4DArrayData; XTest = digitTest4DArrayData;
Definir la arquitectura de red
Los codificadores automáticos tienen dos partes: el codificador y el descodificador. El codificador toma una entrada de imágenes y genera una representación de vector latente (la codificación) usando una serie de operaciones de submuestreo, como convoluciones. De forma similar, el descodificador toma como entrada la representación de vector latente y reconstruye la entrada con una serie de operaciones de sobremuestreo, como convoluciones traspuestas.
Para muestrear la entrada, en este ejemplo se usa la capa personalizada samplingLayer. Para acceder a esta capa, abra el ejemplo como un script en vivo. La capa toma como entrada el vector medio concatenado con el vector de varianza logarítmica y muestrea elementos de . La capa utiliza la varianza logarítmica para hacer que el proceso de entrenamiento sea más estable numéricamente.
Definir la arquitectura de red de un codificador
Defina la siguiente red de codificador que submuestrea imágenes de 28 por 28 por 1 a vectores latentes de 32 por 1.
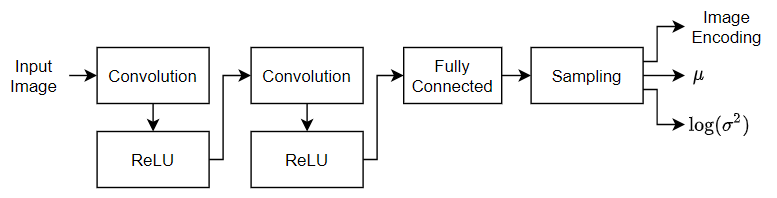
Para la entrada de imagen, especifique una capa de entrada de imagen con un tamaño de entrada que coincida con los datos de entrenamiento. No normalice los datos.
Para submuestrear la entrada, especifique dos bloques de convolución 2D y capas ReLU.
Para generar un vector concatenado de medias y varianzas logarítmicas, especifique una capa totalmente conectada con el doble de canales de salida que de canales latentes.
Para muestrear una codificación especificada por las estadísticas, incluya una capa de muestreo usando la capa personalizada
samplingLayer. Para acceder a esta capa, abra el ejemplo como un script en vivo.
numLatentChannels = 32;
imageSize = [28 28 1];
layersE = [
imageInputLayer(imageSize,Normalization="none")
convolution2dLayer(3,32,Padding="same",Stride=2)
reluLayer
convolution2dLayer(3,64,Padding="same",Stride=2)
reluLayer
fullyConnectedLayer(2*numLatentChannels)
samplingLayer];Definir la arquitectura de red de un descodificador
Defina la siguiente red de descodificador que reconstruye imágenes de 28 por 28 por 1 a partir de vectores latentes de 32 por 1.

Para la entrada de un vector de características, especifique una capa de entrada de características con un tamaño que coincida con el número de canales latentes.
Proyecte y remodele la entrada latente a arreglos de 7 por 7 por 64 con la capa personalizada
projectAndReshapeLayer, que se adjunta a este ejemplo como archivo de apoyo. Para acceder a esta capa, abra el ejemplo como un script en vivo. Especifique un tamaño de proyección de[7 7 64].Para sobremuestrear la entrada, especifique dos bloques de convolución traspuesta y capas ReLU.
Para generar una imagen de tamaño 28 por 28 por 1, incluya una capa de convolución traspuesta con un filtro de 3 por 3.
Para asignar la salida a valores en el intervalo [0,1], incluya una capa de activación sigmoide.
projectionSize = [7 7 64];
numInputChannels = imageSize(3);
layersD = [
featureInputLayer(numLatentChannels)
projectAndReshapeLayer(projectionSize)
transposedConv2dLayer(3,64,Cropping="same",Stride=2)
reluLayer
transposedConv2dLayer(3,32,Cropping="same",Stride=2)
reluLayer
transposedConv2dLayer(3,numInputChannels,Cropping="same")
sigmoidLayer];Para entrenar ambas redes con un bucle de entrenamiento personalizado y habilitar la diferenciación automática, convierta los arreglos de capas a objetos dlnetwork.
netE = dlnetwork(layersE); netD = dlnetwork(layersD);
Definir la función de pérdida del modelo
Defina una función que devuelva la pérdida del modelo y los gradientes de la pérdida con respecto a los parámetros que se pueden aprender.
La función modelLoss, definida en la sección Función de pérdida del modelo del ejemplo, toma como entrada las redes del codificador y el descodificador, y un minilote de datos de entrada, y devuelve la pérdida y los gradientes de la pérdida con respecto a los parámetros que se pueden aprender en las redes. Para calcular la pérdida, la función utiliza la función ELBOloss, definida en la sección Función de pérdida ELBO del ejemplo, toma como entrada la media y las varianzas logarítmicas generadas por el codificador y las utiliza para calcular la pérdida del límite inferior de evidencia (ELBO).
Especificar las opciones de entrenamiento
Entrene con un tamaño de minilote de 128 y una tasa de aprendizaje de 0,001 durante 150 épocas.
numEpochs = 150; miniBatchSize = 128; learnRate = 1e-3;
Entrenar un modelo
Entrene el modelo con un bucle de entrenamiento personalizado.
Cree un objeto minibatchqueue que procese y gestione minilotes de imágenes durante el entrenamiento. Para cada minilote:
Convierta los datos de entrenamiento a un almacén de datos de arreglos. Especifique que se itere sobre la 4.ª dimensión.
Utilice la función de preprocesamiento de minilotes personalizada
preprocessMiniBatch(definida al final de este ejemplo) para concatenar varias observaciones en un único minilote.Dé formato a los datos de imagen con las etiquetas de dimensión
"SSCB"(espacial, espacial, canal, lote). De forma predeterminada, el objetominibatchqueueconvierte los datos en objetosdlarraycon el tipo subyacentesingle.Entrene en una GPU, si se dispone de ella. De forma predeterminada, el objeto
minibatchqueueconvierte cada salida engpuArraysi hay una GPU disponible. Utilizar una GPU requiere Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox).Para garantizar que todos los minilotes tengan el mismo tamaño, descarte cualquier minilote parcial.
dsTrain = arrayDatastore(XTrain,IterationDimension=4); numOutputs = 1; mbq = minibatchqueue(dsTrain,numOutputs, ... MiniBatchSize = miniBatchSize, ... MiniBatchFcn=@preprocessMiniBatch, ... MiniBatchFormat="SSCB", ... PartialMiniBatch="discard");
Inicialice los parámetros para el solver Adam.
trailingAvgE = []; trailingAvgSqE = []; trailingAvgD = []; trailingAvgSqD = [];
Calcule el número total de iteraciones para monitorizar el progreso del entrenamiento
numObservationsTrain = size(XTrain,4); numIterationsPerEpoch = ceil(numObservationsTrain / miniBatchSize); numIterations = numEpochs * numIterationsPerEpoch;
Inicialice la monitorización del progreso del entrenamiento. Dado que el cronómetro empieza cuando crea el objeto de monitorización, asegúrese de crear el objeto cerca del bucle de entrenamiento.
monitor = trainingProgressMonitor( ... Metrics="Loss", ... Info="Epoch", ... XLabel="Iteration");
Entrene la red con un bucle de entrenamiento personalizado. Para cada época, cambie el orden de los datos y pase en bucle por minilotes de datos. Para cada minilote:
Evalúe la pérdida y los gradientes del modelo utilizando las funciones
dlfevalymodelLoss.Actualice los parámetros de red del codificador y el descodificador con la función
adamupdate.Muestre el progreso del entrenamiento.
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Shuffle data. shuffle(mbq); % Loop over mini-batches. while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; % Read mini-batch of data. X = next(mbq); % Evaluate loss and gradients. [loss,gradientsE,gradientsD] = dlfeval(@modelLoss,netE,netD,X); % Update learnable parameters. [netE,trailingAvgE,trailingAvgSqE] = adamupdate(netE, ... gradientsE,trailingAvgE,trailingAvgSqE,iteration,learnRate); [netD, trailingAvgD, trailingAvgSqD] = adamupdate(netD, ... gradientsD,trailingAvgD,trailingAvgSqD,iteration,learnRate); % Update the training progress monitor. recordMetrics(monitor,iteration,Loss=loss); updateInfo(monitor,Epoch=epoch + " of " + numEpochs); monitor.Progress = 100*iteration/numIterations; end end
Probar la red
Pruebe el codificador automático entrenado con un conjunto de prueba retenido. Cree una cola de minilotes de los datos utilizando los mismos pasos que para los datos de entrenamiento, pero no descarte los minilotes parciales.
dsTest = arrayDatastore(XTest,IterationDimension=4); numOutputs = 1; mbqTest = minibatchqueue(dsTest,numOutputs, ... MiniBatchSize = miniBatchSize, ... MiniBatchFcn=@preprocessMiniBatch, ... MiniBatchFormat="SSCB");
Realice predicciones usando el codificador automático entrenado con la función modelPredictions.
YTest = modelPredictions(netE,netD,mbqTest);
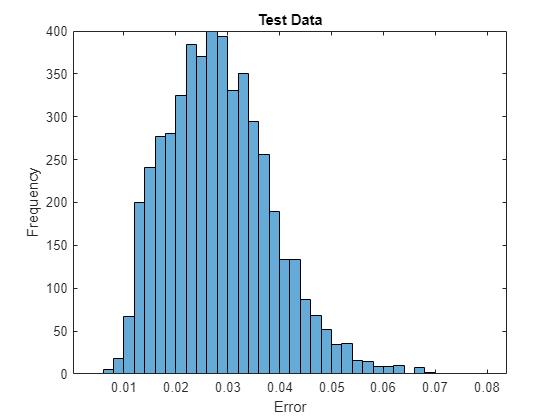
Visualice los errores de reconstrucción tomando el error cuadrático medio de las imágenes de prueba y las imágenes reconstruidas y visualizándolas en un histograma.
err = mean((XTest-YTest).^2,[1 2 3]); figure histogram(err) xlabel("Error") ylabel("Frequency") title("Test Data")
Generar imágenes nuevas
Genere un lote de imágenes nuevas pasando codificaciones de imágenes muestreadas aleatoriamente a través del descodificador.
numImages = 64;
ZNew = randn(numLatentChannels,numImages);
ZNew = dlarray(ZNew,"CB");
YNew = predict(netD,ZNew);
YNew = extractdata(YNew);Muestre las imágenes generadas en una figura.
figure
I = imtile(YNew);
imshow(I)
title("Generated Images")
En este caso, el VAE ha aprendido una representación de características fuerte, que permite generar imágenes similares a los datos de entrenamiento.
Funciones de ayuda
Función de pérdida del modelo
La función modelLoss toma como entrada las redes del codificador y el descodificador, y un minilote de datos de entrada, y devuelve la pérdida y los gradientes de la pérdida con respecto a los parámetros que se pueden aprender en las redes. La función pasa las imágenes de entrenamiento por el codificador y pasa las codificaciones de imágenes resultantes a través del descodificador. Para calcular la pérdida, la función usa la función elboLoss con las estadísticas de media y varianza logarítmica generadas por la capa de muestreo del codificador.
function [loss,gradientsE,gradientsD] = modelLoss(netE,netD,X) % Forward through encoder. [Z,mu,logSigmaSq] = forward(netE,X); % Forward through decoder. Y = forward(netD,Z); % Calculate loss and gradients. loss = elboLoss(Y,X,mu,logSigmaSq); [gradientsE,gradientsD] = dlgradient(loss,netE.Learnables,netD.Learnables); end
Función de pérdida ELBO
La función ELBOloss toma la media y las varianzas logarítmicas generadas por el codificador y las utiliza para calcular la pérdida del límite inferior de evidencia (ELBO). La pérdida ELBO viene dada por la suma de dos términos de pérdida separados:
.
La pérdida de reconstrucción mide el grado de cercanía de la salida del codificador y la entrada original usando el error cuadrático medio (MSE):
.
La pérdida KL loss, o divergencia de Kullback–Leibler, mide la diferencia entre dos distribuciones de probabilidad. En este caso, minimizar la pérdida KL significa garantizar que las medias y varianzas aprendidas estén lo más cerca posible de las de la distribución objetivo (normal). Para una dimensión latente de tamaño , la pérdida KL se obtiene como
.
El efecto práctico de incluir un término de pérdida KL es concentrar las agrupaciones, aprendidas a consecuencia de la pérdida de reconstrucción, en torno al centro del espacio latente, formando así un espacio continuo a partir del que muestrear.
function loss = elboLoss(Y,T,mu,logSigmaSq) % Reconstruction loss. reconstructionLoss = mse(Y,T); % KL divergence. KL = -0.5 * sum(1 + logSigmaSq - mu.^2 - exp(logSigmaSq),1); KL = mean(KL); % Combined loss. loss = reconstructionLoss + KL; end
Función de predicciones del modelo
La función modelPredictions toma como entrada los objetos de red del codificador y el descodificador y minibatchqueue de los datos de entrada mbq y calcula las predicciones del modelo iterando sobre todos los datos en el objeto minibatchqueue.
function Y = modelPredictions(netE,netD,mbq) Y = []; % Loop over mini-batches. while hasdata(mbq) X = next(mbq); % Forward through encoder. Z = predict(netE,X); % Forward through decoder. XGenerated = predict(netD,Z); % Extract and concatenate predictions. Y = cat(4,Y,extractdata(XGenerated)); end end
Función de preprocesamiento de minilotes
La función preprocessMiniBatch preprocesa un minilote de predictores concatenando la entrada a lo largo de la cuarta dimensión.
function X = preprocessMiniBatch(dataX) % Concatenate. X = cat(4,dataX{:}); end
Consulte también
trainnet | trainingOptions | dlnetwork | dlarray | adamupdate | dlfeval | dlgradient | sigmoid