zscore
Puntuaciones z estandarizadas
Sintaxis
Descripción
Z = zscore(X)X de manera tal que las columnas de X están centradas para obtener una media de 0 y escaladas para obtener una desviación estándar de 1. Z tiene el mismo tamaño que X.
Si
Xes un vector,Zes un vector de puntuaciones z.Si
Xes una matriz,Zes una matriz del mismo tamaño queX, y cada columna deZtiene una media de 0 y una desviación estándar de 1.En los arreglos multidimensionales, las puntuaciones z de
Zse calculan a lo largo de la primera dimensión no singular deX.
Z = zscore(X,flag)X usando la desviación estándar indicada por flag.
Si
flages 0 (valor predeterminado),zscoreescalaXusando la desviación estándar de la muestra, con n - 1 en el denominador de la fórmula de la desviación estándar.zscore(X,0)es igual quezscore(X).Si
flages 1,zscoreescalaXusando la desviación estándar de la población, con n en el denominador de la fórmula de la desviación estándar.
Ejemplos
Calcule y represente las puntuaciones de dos vectores de datos y compare los resultados.
Cargue los datos de muestra.
load lawdataEn el espacio de trabajo se cargan dos variables: gpa y lsat.
Represente ambas variables en los mismos ejes.
plot([gpa,lsat]) legend('gpa','lsat','Location','East')
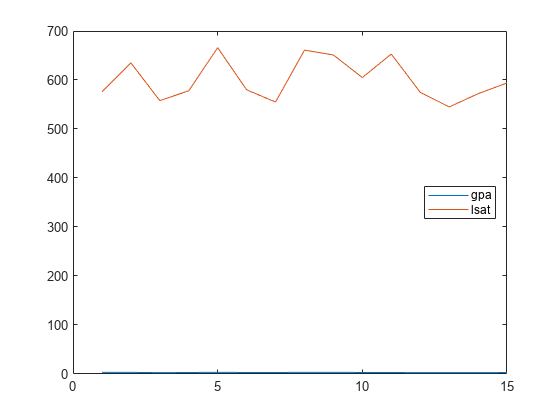
Es difícil comparar estas dos medidas porque están en una escala muy diferente.
Represente las puntuaciones de gpa y lsat en los mismos ejes.
Zgpa = zscore(gpa); Zlsat = zscore(lsat); plot([Zgpa, Zlsat]) legend('gpa z-scores','lsat z-scores','Location','Northeast')

Ahora, puede ver el rendimiento relativo de los individuos con respecto a sus resultados de gpa y lsat. Por ejemplo, los resultados gpa y lsat del tercer individuo son ambos una desviación estándar por debajo de la media de la muestra. El gpa del undécimo individuo está alrededor de la media de la muestra, pero tiene una puntuación lsat de casi 1,25 desviaciones estándar por encima de la media de la muestra.
Compruebe la media y la desviación estándar de las puntuaciones que ha creado.
mean([Zgpa,Zlsat])
ans = 1×2
10-14 ×
-0.1088 0.0357
std([Zgpa,Zlsat])
ans = 1×2
1 1
Por definición, las puntuaciones de gpa y lsat tienen una media de 0 y una desviación estándar de 1.
Cargue los datos de muestra.
load lawdataEn el espacio de trabajo se cargan dos variables: gpa y lsat.
Calcule las puntuaciones de gpa usando la fórmula de la población para la desviación estándar.
Z1 = zscore(gpa,1); % population formula Z0 = zscore(gpa,0); % sample formula disp([Z1 Z0])
1.2554 1.2128
0.8728 0.8432
-1.2100 -1.1690
-0.2749 -0.2656
1.4679 1.4181
-0.1049 -0.1013
-0.4024 -0.3888
1.4254 1.3771
1.1279 1.0896
0.1502 0.1451
0.1077 0.1040
-1.5076 -1.4565
-1.4226 -1.3743
-0.9125 -0.8815
-0.5724 -0.5530
Para una muestra de una población, la fórmula de desviación estándar de la población con en el denominador corresponde a la estimación de máxima verosimilitud de la desviación estándar de la población y podría estar sesgada. La fórmula de la desviación estándar de la muestra, por otro lado, es el estimador no sesgado de la desviación estándar de la población para una muestra.
Calcule las puntuaciones usando la media y la desviación estándar calculadas a lo largo de las columnas o filas de una matriz de datos.
Cargue los datos de muestra.
load fluEl arreglo del conjunto de datos flu se carga en el espacio de trabajo. flu tiene 52 observaciones sobre 11 variables. La primera variable contiene fechas (en semanas). Las otras variables contienen estimaciones sobre la gripe para diferentes regiones de Estados Unidos.
Convierta el arreglo del conjunto de datos en una matriz de datos.
flu2 = double(flu(:,2:end));
La nueva matriz de datos, flu2, es una matriz de datos doble de 52 por 10. Las filas corresponden a las semanas y las columnas corresponden a las regiones de Estados Unidos en el arreglo del conjunto de datos flu.
Estandarice la estimación sobre la gripe para cada región (las columnas de flu2).
Z1 = zscore(flu2,[ ],1);
Puede ver las puntuaciones en el editor de variables haciendo doble clic en la matriz Z1 creada en el espacio de trabajo.
Estandarice la estimación sobre la gripe para cada semana (las filas de flu2).
Z2 = zscore(flu2,[ ],2);
Encuentre las puntuaciones z de un arreglo multidimensional especificando estandarizar los datos a lo largo de diferentes dimensiones. Compare los resultados al usar los argumentos de entrada 'all', dim y vecdim.
Cree un arreglo de 3 por 4 por 2.
X = reshape(1:24,[3 4 2])
X =
X(:,:,1) =
1 4 7 10
2 5 8 11
3 6 9 12
X(:,:,2) =
13 16 19 22
14 17 20 23
15 18 21 24
Estandarice X usando la media y la desviación estándar de todos los valores de X.
Zall = zscore(X,0,'all')Zall =
Zall(:,:,1) =
-1.6263 -1.2021 -0.7778 -0.3536
-1.4849 -1.0607 -0.6364 -0.2121
-1.3435 -0.9192 -0.4950 -0.0707
Zall(:,:,2) =
0.0707 0.4950 0.9192 1.3435
0.2121 0.6364 1.0607 1.4849
0.3536 0.7778 1.2021 1.6263
El arreglo multidimensional resultante de las puntuaciones z tiene una media de 0 y una desviación estándar de 1. Por ejemplo, calcule la media y la desviación estándar de Zall.
mZall = mean(Zall(:,:,:),'all')mZall = -9.2519e-18
sZall = std(Zall(:,:,:),0,'all')sZall = 1.0000
Ahora estandarice X a lo largo de la segunda dimensión.
Zdim = zscore(X,0,2)
Zdim = Zdim(:,:,1) = -1.1619 -0.3873 0.3873 1.1619 -1.1619 -0.3873 0.3873 1.1619 -1.1619 -0.3873 0.3873 1.1619 Zdim(:,:,2) = -1.1619 -0.3873 0.3873 1.1619 -1.1619 -0.3873 0.3873 1.1619 -1.1619 -0.3873 0.3873 1.1619
Los elementos en cada fila de cada página de Zdim tienen una media de 0 y una desviación estándar de 1. Por ejemplo, calcule la media y la desviación estándar de la primera fila de la segunda página de Zdim.
mZdim = mean(Zdim(1,:,2),'all')mZdim = 0
sZdim = std(Zdim(1,:,2),0,'all')sZdim = 1
Finalmente, estandarice X en función de la segunda y la tercera dimensión.
Zvecdim = zscore(X,0,[2 3])
Zvecdim =
Zvecdim(:,:,1) =
-1.4289 -1.0206 -0.6124 -0.2041
-1.4289 -1.0206 -0.6124 -0.2041
-1.4289 -1.0206 -0.6124 -0.2041
Zvecdim(:,:,2) =
0.2041 0.6124 1.0206 1.4289
0.2041 0.6124 1.0206 1.4289
0.2041 0.6124 1.0206 1.4289
Los elementos en cada porción de Zvecdim(i,:,:) tienen una media de 0 y una desviación estándar de 1. Por ejemplo, calcule la media y la desviación estándar de los elementos de Zvecdim(1,:,:).
mZvecdim = mean(Zvecdim(1,:,:),'all')mZvecdim = 2.7756e-17
sZvecdim = std(Zvecdim(1,:,:),0,'all')sZvecdim = 1
Devuelva la media y la desviación estándar usadas para calcular las puntuaciones .
Cargue los datos de muestra.
load lawdataEn el espacio de trabajo se cargan dos variables: gpa y lsat.
Devuelva las puntuaciones , la media y la desviación estándar de gpa.
[Z,gpamean,gpastdev] = zscore(gpa)
Z = 15×1
1.2128
0.8432
-1.1690
-0.2656
1.4181
-0.1013
-0.3888
1.3771
1.0896
0.1451
0.1040
-1.4565
-1.3743
-0.8815
-0.5530
⋮
gpamean = 3.0947
gpastdev = 0.2435
Argumentos de entrada
Argumentos de salida
Puntuaciones z-, devueltas como un vector, una matriz o un arreglo multidimensional. Z tiene las mismas dimensiones que X.
Los valores de Z dependen de si especifica 'all', dim o vecdim. Si no especifica ninguno de estos argumentos de entrada, se aplican las siguientes condiciones:
Si
Xes un vector,Zes un vector de puntuaciones z con una media de 0 y una varianza de 1.Si
Xes un arreglo,zscoreestandariza a lo largo de la primera dimensión no singular deX.
Para ver un ejemplo que demuestre las diferencias en Z cuando usa 'all', dim y vecdim, consulte Puntuaciones z de un arreglo multidimensional.
Media de X usada para calcular las puntuaciones z, devuelta como un escalar, un vector, una matriz o un arreglo multidimensional. mu tiene una longitud de 1 en las dimensiones operativas especificadas. El resto de las longitudes de las dimensiones son iguales para X e mu.
Por ejemplo, si X es un arreglo de 2 por 3 por 3 y vecdim es [1 2], mu es un arreglo de medias de 1 por 1 por 3. Cada valor de mu corresponde a la media de una página de X.

Desviación estándar de X usada para calcular las puntuaciones z, devuelta como un escalar, un vector, una matriz o un arreglo multidimensional. sigma tiene una longitud de 1 en las dimensiones operativas especificadas. El resto de las longitudes de las dimensiones son iguales para X e sigma.
Por ejemplo, si X es un arreglo de 2 por 3 por 3 y vecdim es [1 2], sigma es un arreglo de desviaciones estándar de 1 por 1 por 3. Cada valor de sigma corresponde a la desviación estándar de una página de X.
Más acerca de
Algoritmos
zscore devuelve NaN para cualquier muestra que contenga NaN.
zscore devuelve 0 para cualquier muestra que sea constante (todos los valores son los mismos). Por ejemplo, si X es un vector del mismo valor numérico, Z es un vector de 0.
Capacidades ampliadas
Historial de versiones
Introducido antes de R2006a