textscan
Read formatted data from text file or string
Syntax
Description
C = textscan(fileID,formatSpec)C.
The text file is indicated by the file identifier, fileID.
Use fopen to open the file and obtain the fileID value.
When you finish reading from a file, close the file by calling fclose(fileID).
textscan attempts to match the data in the
file to the conversion specifier in formatSpec.
The textscan function reapplies formatSpec throughout
the entire file and stops when it cannot match formatSpec to
the data.
C = textscan(fileID,formatSpec,N)formatSpec N times,
where N is a positive integer. To read additional
data from the file after N cycles, call textscan again
using the original fileID. If you resume a text
scan of a file by calling textscan with the same
file identifier (fileID), then textscan automatically
resumes reading at the point where it terminated the last read.
C = textscan(chr,formatSpec)chr into cell array C.
When reading text from a character vector, repeated calls to textscan restart
the scan from the beginning each time. To restart a scan from the
last position, request a position output.
textscan attempts to match the data in character
vector chr to the format specified in formatSpec.
C = textscan(chr,formatSpec,N)formatSpec N times, where N is
a positive integer.
C = textscan(___,Name,Value)Name,Value pair arguments,
in addition to any of the input arguments in the previous syntaxes.
[ returns the position in the
file or the character vector at the end of the scan as the second
output argument. For a file, this is the value that C,position]
= textscan(___)ftell(fileID) would
return after calling textscan. For a character
vector, position indicates how many characters
textscan read.
Examples
Read a character vector containing floating-point numbers.
chr = '0.41 8.24 3.57 6.24 9.27'; C = textscan(chr,'%f');
The specifier '%f' in formatSpec tells textscan to match each field in chr to a double-precision floating-point number.
Display the contents of cell array C.
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700
Read the same character vector, and truncate each value to one decimal digit.
C = textscan(chr,'%3.1f %*1d');The specifier %3.1f indicates a field width of 3 digits and a precision of 1. The textscan function reads a total of 3 digits, including the decimal point and the 1 digit after the decimal point. The specifier, %*1d, tells textscan to skip the remaining digit.
Display the contents of cell array C.
celldisp(C)
C{1} =
0.4000
8.2000
3.5000
6.2000
9.2000
Read a character vector that represents a set of hexadecimal numbers. Text that represents hexadecimal numbers includes the digits 0-9, the letters a-f or A-F, and optionally the prefixes 0x or 0X.
To match the fields in hexnums to hexadecimal numbers, use the '%x' specifier. The textscan function converts the fields to unsigned 64-bit integers.
hexnums = '0xFF 0x100 0x3C5E A F 10'; C = textscan(hexnums,'%x')
C = 1×1 cell array
{6×1 uint64}
Display the contents of C as a row vector.
transpose(C{:})ans = 1×6 uint64 row vector
255 256 15454 10 15 16
You can convert the fields to signed or unsigned integers, having 8, 16, 32, or 64 bits. To convert the fields in hexnums to signed 32-bit integers, use the '%xs32' specifier.
C = textscan(hexnums,'%xs32');
transpose(C{:})ans = 1×6 int32 row vector
255 256 15454 10 15 16
You can also specify a field width for interpreting the input. In that case, the prefix counts towards the field width. For example, if you set the field width to three, as in %3x, then textscan splits the text '0xAF 100' into three pieces of text, '0xA', 'F', and '100'. It treats the three pieces of text as different hexadecimal numbers.
C = textscan('0xAF 100','%3x'); transpose(C{:})
ans = 1×3 uint64 row vector
10 15 256
Read a character vector that represents a set of binary numbers. Text that represents binary numbers includes the digits 0 and 1, and optionally the prefixes 0b or 0B.
To match the fields in binnums to binary numbers, use the '%b' specifier. The textscan function converts the fields to unsigned 64-bit integers.
binnums = '0b101010 0b11 0b100 1001 10'; C = textscan(binnums,'%b')
C = 1×1 cell array
{5×1 uint64}
Display the contents of C as a row vector.
transpose(C{:})ans = 1×5 uint64 row vector
42 3 4 9 2
You can convert the fields to signed or unsigned integers, having 8, 16, 32, or 64 bits. To convert the fields in binnums to signed 32-bit integers, use the '%bs32' specifier.
C = textscan(binnums,'%bs32');
transpose(C{:})ans = 1×5 int32 row vector
42 3 4 9 2
You can also specify a field width for interpreting the input. In that case, the prefix counts towards the field width. For example, if you set the field width to three, as in %3b, then textscan splits the text '0b1010 100' into three pieces of text, '0b1', '010', and '100'. It treats the three pieces of text as different binary numbers.
C = textscan('0b1010 100','%3b'); transpose(C{:})
ans = 1×3 uint64 row vector
1 2 4
Load the data file and read each column with the appropriate type.
Load file scan1.dat and preview its contents in a text editor. A screen shot is shown below.
filename = 'scan1.dat';
Open the file, and read each column with the appropriate conversion specifier. textscan returns a 1-by-9 cell array C.
fileID = fopen(filename); C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f'); fclose(fileID); whos C
Name Size Bytes Class Attributes C 1x9 2249 cell
View the MATLAB® data type of each of the cells in C.
C
C=1×9 cell array
{3×1 cell} {3×1 cell} {3×1 single} {3×1 int8} {3×1 uint32} {3×1 double} {3×1 double} {3×1 cell} {3×1 double}
Examine the individual entries. Notice that C{1} and C{2} are cell arrays. C{5} is of data type uint32, so the first two elements of C{5} are the maximum values for a 32-bit unsigned integer, or intmax('uint32').
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i
Remove the literal text 'Level' from each field in the second column of the data from the previous example. A preview of the file is shown below.

Open the file and match the literal text in the formatSpec input.
filename = 'scan1.dat'; fileID = fopen(filename); C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f'); fclose(fileID); C{2}
ans = 3×1 int32 column vector
1
2
3
View the MATLAB® data type of the second cell in C. The second cell of the 1-by-9 cell array, C, is now of data type int32.
disp( class(C{2}) )int32
Read the first column of the file in the previous example into a cell array, skipping the rest of the line.
filename = 'scan1.dat'; fileID = fopen(filename); dates = textscan(fileID,'%s %*[^\n]'); fclose(fileID); dates{1}
ans = 3×1 cell
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}
textscan returns a cell array dates.
Load the file data.csv and preview its contents in a text editor. A screen shot is shown below. Notice the file contains data separated by commas and also contains empty values.
![]()
Read the file, converting empty cells to -Inf.
filename = 'data.csv'; fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f %u8 %f',... 'Delimiter',',','EmptyValue',-Inf); fclose(fileID); column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2×1 uint8 column vector
0
11
textscan returns a 1-by-6 cell array, C. The textscan function converts the empty value in C{4} to -Inf, where C{4} is associated with a floating-point format. Because MATLAB® represents unsigned integer -Inf as 0, textscan converts the empty value in C{5} to 0, and not -Inf.
Load the file data2.csv and preview its contents in a text editor. A screen shot is shown below. Notice the file contains data that can be interpreted as comments and other entries such as 'NA' or 'na' that may indicate empty fields.
filename = 'data2.csv';![]()
Designate the input that textscan should treat as comments or empty values and scan the data into C.
fileID = fopen(filename); C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',... 'TreatAsEmpty',{'NA','na'},'CommentStyle','//'); fclose(fileID);
Display the output.
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
Load the file data3.csv and preview its contents in a text editor. A screen shot is shown below. Notice the file contains repeated delimiters.
filename = 'data3.csv';
To treat the repeated commas as a single delimiter, use the MultipleDelimsAsOne parameter, and set the value to 1 (true).
fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f','Delimiter',',',... 'MultipleDelimsAsOne',1); fclose(fileID); celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
Load the data file grades.txt for this example and preview its contents in a text editor. A screen shot is shown below. Notice the file contains repeated delimiters.
filename = 'grades.txt';
Read the column headers using the format '%s' four times.
fileID = fopen(filename); formatSpec = '%s'; N = 4; C_text = textscan(fileID,formatSpec,N,'Delimiter','|');
Read the numeric data in the file.
C_data0 = textscan(fileID,'%d %f %f %f')C_data0=1×4 cell array
{4×1 int32} {4×1 double} {4×1 double} {4×1 double}
The default value for CollectOutput is 0 (false), so textscan returns each column of the numeric data in a separate array.
Set the file position indicator to the beginning of the file.
frewind(fileID);
Reread the file and set CollectOutput to 1 (true) to collect the consecutive columns of the same class into a single array. You can use the repmat function to indicate that the %f conversion specifier should appear three times. This technique is useful when a format repeats many times.
C_text = textscan(fileID,'%s',N,'Delimiter','|'); C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell array
{4×1 int32} {4×3 double}
The test scores, which are all double, are collected into a single 4-by-3 array.
Close the file.
fclose(fileID);
Read the first and last columns of data from a text file. Skip a column of text and a column of integer data.
Load the file names.txt and preview its contents in a text editor. A screen shot is shown below. Notice that the file contains two columns of quoted text, followed by a column of integers, and finally a column of floating point numbers.
filename = 'names.txt';
Read the first and last columns of data in the file. Use the conversion specifier, %q to read the text enclosed by double quotation marks ("). %*q skips the quoted text, %*d skips the integer field, and %f reads the floating-point number. Specify the comma delimiter using the 'Delimiter' name-value pair argument.
fileID = fopen(filename,'r'); C = textscan(fileID,'%q %*q %*d %f','Delimiter',','); fclose(fileID);
Display the output. textscan returns a cell array C where the double quotation marks enclosing the text are removed.
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000
Load the file german_dates.txt and preview its contents in a text editor. A screen shot is shown below. Notice that the first column of values contains dates in German and the second and third columns are numeric values.
filename = 'german_dates.txt';
Open the file. Specify the character encoding scheme associated with the file as the last input to fopen.
fileID = fopen(filename,'r','n','ISO-8859-15');
Read the file. Specify the format of the dates in the file using the %{dd % MMMM yyyy}D specifier. Specify the locale of the dates using the DateLocale name-value pair argument.
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',... 'DateLocale','de_DE','Delimiter',','); fclose(fileID);
View the contents of the first cell in C. The dates display in the language MATLAB uses depending on your system locale.
C{1}ans = 3×1 datetime
01 January 2014
01 February 2014
01 March 2014
Use sprintf to convert nondefault escape sequences in your data.
Create text that includes a form feed character, \f. Then, to read the text using textscan, call sprintf to explicitly convert the form feed.
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight'); C = textscan(lyric,'%s','delimiter',sprintf('\f')); C{1}
ans = 7×1 cell
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan returns a cell array, C.
Resume scanning from a position other than the beginning.
If you resume a scan of the text, textscan reads from the beginning each time. To resume a scan from any other position, use the two-output argument syntax in your initial call to textscan.
For example, create a character vector called lyric. Read the first word of the character vector, and then resume the scan.
lyric = 'Blackbird singing in the dead of night'; [firstword,pos] = textscan(lyric,'%9c',1); lastpart = textscan(lyric(pos+1:end),'%s');
Input Arguments
File identifier of an open text file, specified as a number.
Before reading a file with textscan, you must use fopen to
open the file and obtain the fileID.
Data Types: double
Format of the data fields, specified as a character vector or
a string of one or more conversion specifiers. When textscan reads
the input, it attempts to match the data to the format specified in formatSpec.
If textscan fails to match a data field, it stops
reading and returns all fields read before the failure.
The number of conversion specifiers determines the number of
cells in output array, C.
Numeric Fields
This table lists available conversion specifiers for numeric inputs.
| Numeric Input Type | Conversion Specifier | Output Class |
|---|---|---|
| Integer, signed | %d | int32 |
%d8 | int8 | |
%d16 | int16 | |
%d32 | int32 | |
%d64 | int64 | |
| Integer, unsigned | %u | uint32 |
%u8 | uint8 | |
%u16 | uint16 | |
%u32 | uint32 | |
%u64 | uint64 | |
| Floating-point number | %f | double |
%f32 | single | |
%f64 | double | |
%n | double | |
| Hexadecimal number, unsigned integer | %x | uint64 |
%xu8 | uint8 | |
%xu16 | uint16 | |
%xu32 | uint32 | |
%xu64 | uint64 | |
| Hexadecimal number, signed integer | %xs8 | int8 |
%xs16 | int16 | |
%xs32 | int32 | |
%xs64 | int64 | |
| Binary number, unsigned integer | %b | uint64 |
%bu8 | uint8 | |
%bu16 | uint16 | |
%bu32 | uint32 | |
%bu64 | uint64 | |
| Binary number, signed integer | %bs8 | int8 |
%bs16 | int16 | |
%bs32 | int32 | |
%bs64 | int64 |
Nonnumeric Fields
This table lists available conversion specifiers for inputs that include nonnumeric characters.
| Nonnumeric Input Type | Conversion Specifier | Details |
|---|---|---|
| Character | %c | Read any single character, including a delimiter. |
| Text Array | %s | Read as a cell array of character vectors. |
%q | Read as a cell array of character vectors.
If the text begins with a double quotation mark ( Example: | |
| Dates and time | %D | Read the same way as |
%{ | Read the same way as For more information
about datetime display formats, see the Example: | |
| Duration | %T |
Read the same way as |
%{ | Read the same way as For more
information about duration display formats, see the Example: | |
| Category | %C | Read the same way as |
| Pattern-matching | %[...] | Read as a cell array of character vectors, the characters
inside the brackets up to the first nonmatching character. To include Example: |
%[^...] | Exclude characters inside the brackets, reading until
the first matching character. To exclude Example: |
Optional Operators
Conversion specifiers in formatSpec can include optional operators, which
appear in the following order (includes spaces for clarity):

Optional operators include:
Fields and Characters to Ignore
textscanreads all characters in your file in sequence, unless you tell it to ignore a particular field or a portion of a field.Insert an asterisk character (*) after the percent character (%) to skip a field or a portion of a character field.
Operator
Action Taken
%*kSkip the field.
kis any conversion specifier identifying the field to skip.textscandoes not create an output cell for any such fields.Example:
'%s %*s %s %s %*s %*s %s'(spaces are optional) converts the text
'Blackbird singing in the dead of night'into four output cells with
'Blackbird' 'in' 'the' 'night''%*ns'Skip up to
ncharacters, wherenis an integer less than or equal to the number of characters in the field.Example:
'%*3s %s'converts'abcdefg'to'defg'. When the delimiter is a comma, the same delimiter converts'abcde,fghijkl'to a cell array containing'de';'ijkl'.'%*nc'Skip
ncharacters, including delimiter characters.Field Width
textscanreads the number of characters or digits specified by the field width or precision, or up to the first delimiter, whichever comes first. A decimal point, sign (+or-), exponent character, and digits in the numeric exponent are counted as characters and digits within the field width. For complex numbers, the field width refers to the individual widths of the real part and the imaginary part. For the imaginary part, the field width includes + or − but notiorj. Specify the field width by inserting a number after the percent character (%) in the conversion specifier.Example:
%5freads'123.456'as123.4.Example:
%5creads'abcdefg'as'abcde'.When the field width operator is used with single characters (
%c),textscanalso reads delimiter, white-space, and end-of-line characters.
Example:%7creads 7 characters, including white-space, so'Day and night'reads as'Day and'.Precision
For floating-point numbers (
%n,%f,%f32,%f64), you can specify the number of decimal digits to read.Example:
%7.2freads'123.456'as123.45.Literal Text to Ignore
textscanignores the text appended to theformatSpecconversion specifier.Example:
Level%u8reads'Level1'as1.Example:
%u8Stepreads'2Step'as2.
Data Types: char | string
Number of times to apply formatSpec, specified
as a positive integer.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Input text to read.
Data Types: char | string
Name-Value Arguments
Output Arguments
Algorithms
textscan converts numeric fields to the specified
output type according to MATLAB rules regarding overflow, truncation,
and the use of NaN, Inf, and -Inf.
For example, MATLAB represents an integer NaN as
zero. If textscan finds an empty field associated
with an integer format specifier (such as %d or %u),
it returns the empty value as zero and not NaN.
When matching data to a text conversion specifier, textscan reads
until it finds a delimiter or an end-of-line character. When matching
data to a numeric conversion specifier, textscan reads
until it finds a nonnumeric character. When textscan can
no longer match the data to a particular conversion specifier, it
attempts to match the data to the next conversion specifier in the formatSpec.
Sign (+ or -), exponent characters,
and decimal points are considered numeric characters.
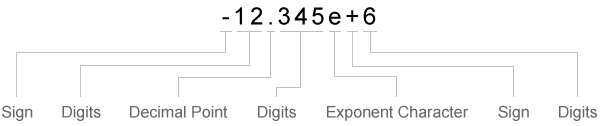
| Sign | Digits | Decimal Point | Digits | Exponent Character | Sign | Digits |
|---|---|---|---|---|---|---|
| Read one sign character if it exists. | Read one or more digits. | Read one decimal point if it exists. | If there is a decimal point, read one or more digits that immediately follow it. | Read one exponent character if it exists. | If there is an exponent character, read one sign character. | If there is an exponent character, read one or more digits that follow it. |
textscan imports any complex number as a
whole into a complex numeric field, converting the real and imaginary
parts to the specified numeric type (such as %d or %f).
Valid forms for a complex number are:
±<real>±<imag>i|j | Example: |
±<imag>i|j | Example: |
Do not include embedded white space in a complex number. textscan interprets
embedded white space as a field delimiter.