kruskalwallis
Prueba de Kruskal-Wallis
Sintaxis
Descripción
p = kruskalwallis(x)x proceden de la misma distribución, utilizando la prueba de Kruskal-Wallis. La hipótesis alternativa es que no todas las muestras proceden de la misma distribución. La prueba de Kruskal-Wallis proporciona una alternativa no paramétrica al ANOVA de un factor. Para obtener más información, consulte Prueba de Kruskal-Wallis.
p = kruskalwallis(x,group,displayopt)
Ejemplos
Cree dos objetos diferentes de distribución de probabilidad normal. La primera distribución tiene mu = 0 y sigma = 1 y la segunda distribución tiene mu = 2 y sigma = 1.
pd1 = makedist('Normal'); pd2 = makedist('Normal','mu',2,'sigma',1);
Cree una matriz de datos de muestra generando números aleatorios a partir de estas dos distribuciones.
rng('default'); % for reproducibility x = [random(pd1,20,2),random(pd2,20,1)];
Las dos primeras columnas de x contienen datos generados a partir de la primera distribución, mientras que la tercera columna contiene datos generados a partir de la segunda distribución.
Pruebe la hipótesis nula de que los datos de muestra de cada columna de x proceden de la misma distribución.
p = kruskalwallis(x)


p = 3.6896e-06
El valor devuelto de p indica que kruskalwallis rechaza la hipótesis nula de que las tres muestras de datos proceden de la misma distribución a un nivel de significación del 1%. La tabla ANOVA proporciona resultados adicionales de las pruebas y la gráfica de cajas presenta visualmente las estadísticas descriptivas de cada columna de x.
Cree dos objetos diferentes de distribución de probabilidad normal. La primera distribución tiene mu = 0 y sigma = 1. La segunda distribución tiene mu = 2 y sigma = 1.
pd1 = makedist('Normal'); pd2 = makedist('Normal','mu',2,'sigma',1);
Cree una matriz de datos de muestra generando números aleatorios a partir de estas dos distribuciones.
rng('default'); % for reproducibility x = [random(pd1,20,2),random(pd2,20,1)];
Las dos primeras columnas de x contienen datos generados a partir de la primera distribución, mientras que la tercera columna contiene datos generados a partir de la segunda distribución.
Pruebe la hipótesis nula de que los datos de muestra de cada columna de x proceden de la misma distribución. Suprima las visualizaciones de salida y genere la estructura stats para utilizarla en pruebas posteriores.
[p,tbl,stats] = kruskalwallis(x,[],'off')p = 3.6896e-06
tbl=4×6 cell array
{'Source' } {'SS' } {'df'} {'MS' } {'Chi-sq' } {'Prob>Chi-sq'}
{'Columns'} {[7.6311e+03]} {[ 2]} {[3.8155e+03]} {[ 25.0200]} {[ 3.6896e-06]}
{'Error' } {[1.0364e+04]} {[57]} {[ 181.8228]} {0×0 double} {0×0 double }
{'Total' } {[ 17995]} {[59]} {0×0 double } {0×0 double} {0×0 double }
stats = struct with fields:
gnames: [3×1 char]
n: [20 20 20]
source: 'kruskalwallis'
meanranks: [26.7500 18.9500 45.8000]
sumt: 0
El valor devuelto de p indica que la prueba rechaza la hipótesis nula al nivel de significación del 1%. Puede utilizar la estructura stats para hacer pruebas de seguimiento adicionales. El arreglo de celdas tbl contiene los mismos datos que la tabla gráfica ANOVA, incluidas las etiquetas de columnas y filas.
Realice una prueba de seguimiento para identificar qué muestra de datos procede de una distribución diferente.
c = multcompare(stats);
Note: Intervals can be used for testing but are not simultaneous confidence intervals.
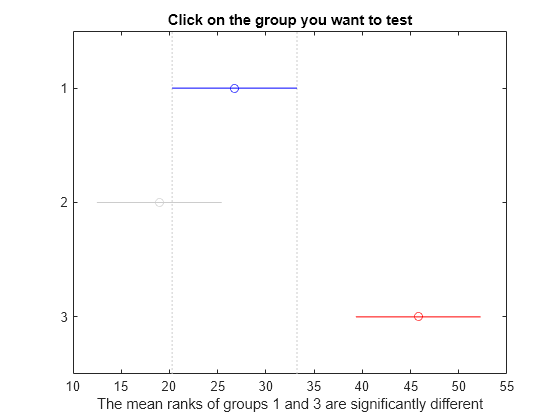
Muestre los resultados de la comparación múltiple en una tabla.
tbl = array2table(c,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ______ ___________ __________
1 2 -5.1435 7.8 20.744 0.33446
1 3 -31.994 -19.05 -6.1065 0.0016282
2 3 -39.794 -26.85 -13.906 3.4768e-06
Los resultados indican que existe una diferencia significativa entre los grupos 1 y 3, por lo que la prueba rechaza la hipótesis nula de que los datos de estos dos grupos proceden de la misma distribución. Lo mismo ocurre con los grupos 2 y 3. Sin embargo, no hay una diferencia significativa entre los grupos 1 y 2, por lo que la prueba no rechaza la hipótesis nula de que estos dos grupos proceden de la misma distribución. Por lo tanto, estos resultados sugieren que los datos de los grupos 1 y 2 proceden de la misma distribución, y los datos del grupo 3 proceden de una distribución diferente.
Cree un vector, strength, que contenga mediciones de la resistencia de vigas metálicas. Cree un segundo vector, alloy, que indique el tipo de aleación metálica de la que está hecha la viga correspondiente.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
Pruebe la hipótesis nula de que las mediciones de la resistencia del haz tienen la misma distribución en las tres aleaciones.
p = kruskalwallis(strength,alloy,'off')p = 0.0018
El valor devuelto de p indica que la prueba rechaza la hipótesis nula al nivel de significación del 1%.
Argumentos de entrada
Argumentos de salida
Más acerca de
Historial de versiones
Introducido antes de R2006a