optimalleaforder
Optimal leaf ordering for hierarchical clustering
Description
leafOrder = optimalleaforder(tree,D)tree, using the distances, D. An optimal
leaf ordering of a binary tree maximizes the sum of the similarities between
adjacent leaves by flipping tree branches without dividing the clusters.
leafOrder = optimalleaforder(tree,D,Name,Value)
Examples
Create a hierarchical binary cluster tree using linkage. Then, compare the dendrogram plot with the default ordering to a dendrogram with an optimal leaf ordering.
Generate sample data.
rng(0,"twister") % For reproducibility X = rand(10,2);
Create a distance vector and a hierarchical binary clustering tree. Use the distances and clustering tree to determine an optimal leaf order.
D = pdist(X);
tree = linkage(D,"average");
leafOrder = optimalleaforder(tree,D);Plot the dendrogram with the default ordering and the dendrogram with the optimal leaf ordering.
figure() subplot(2,1,1) dendrogram(tree) title("Default Leaf Order") subplot(2,1,2) dendrogram(tree,reorder=leafOrder) title("Optimal Leaf Order")
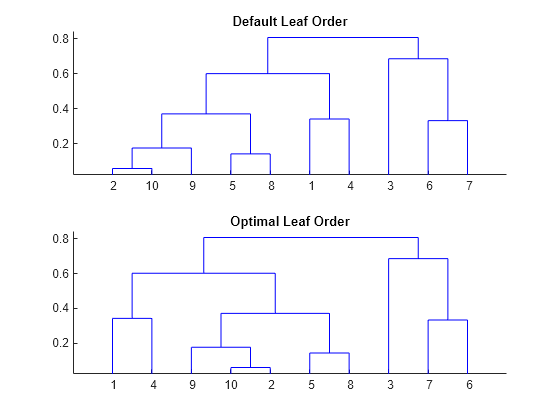
The order of the leaves in the bottom figure corresponds to the elements in leafOrder. The optimal leaf order flips tree branches to maximize the sum of the similarities between adjacent leaves.
leafOrder
leafOrder = 1×10
1 4 9 10 2 5 8 3 7 6
Create a scatter plot of the sample data and label the points.
figure()
plot(X(:,1),X(:,2),".")
text(X(:,1),X(:,2),num2str((1:size(X,1))'))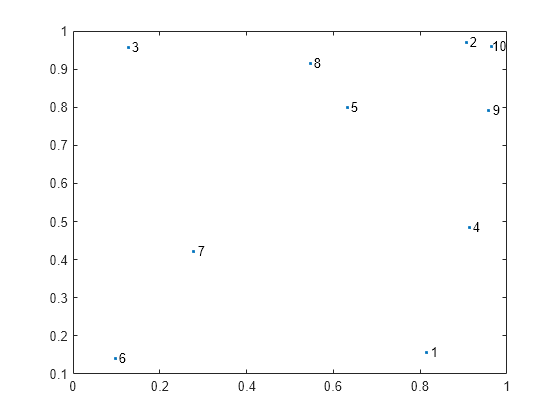
In the default leaf ordering, points 1 and 4 are located next to points 3 and 8. In the optimal leaf ordering, points 1 and 4 are located next to point 9, which reflects their relative positions in the scatter plot.
Generate sample data.
rng('default') % For reproducibility X = rand(10,2);
Create a distance vector and a hierarchical binary clustering tree.
D = pdist(X);
tree = linkage(D,'average');Use the inverse distance similarity transformation to determine an optimal leaf order.
leafOrder = optimalleaforder(tree,D,'Transformation','inverse')
leafOrder = 1×10
1 4 9 10 2 5 8 3 7 6
Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Bar-Joseph, Z., Gifford, D.K., and Jaakkola, T.S. (2001). "Fast optimal leaf ordering for hierarchical clustering." Bioinformatics Vol. 17, Suppl 1:S22–9. PMID: 11472989.
Version History
Introduced in R2012b
See Also
dendrogram | linkage | pdist