loss
Class: RegressionLinear
Regression loss for linear regression models
Description
L = loss(Mdl,Tbl,ResponseVarName)Tbl and the true
responses in Tbl.ResponseVarName.
L = loss(___,Name,Value)
Input Arguments
Name-Value Arguments
Output Arguments
Examples
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Train a linear regression model. Reserve 30% of the observations as a holdout sample.
CVMdl = fitrlinear(X,Y,'Holdout',0.3);
Mdl = CVMdl.Trained{1}Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0066
Lambda: 1.4286e-04
Learner: 'svm'
Properties, Methods
CVMdl is a RegressionPartitionedLinear model. It contains the property Trained, which is a 1-by-1 cell array holding a RegressionLinear model that the software trained using the training set.
Extract the training and test data from the partition definition.
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
Estimate the training- and test-sample MSE.
mseTrain = loss(Mdl,X(trainIdx,:),Y(trainIdx))
mseTrain = 0.1496
mseTest = loss(Mdl,X(testIdx,:),Y(testIdx))
mseTest = 0.1798
Because there is one regularization strength in Mdl, mseTrain and mseTest are numeric scalars.
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility n = 1e4; d = 1e3; nz = 0.1; X = sprandn(n,d,nz); Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1); X = X'; % Put observations in columns for faster training
Train a linear regression model. Reserve 30% of the observations as a holdout sample.
CVMdl = fitrlinear(X,Y,'Holdout',0.3,'ObservationsIn','columns'); Mdl = CVMdl.Trained{1}
Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0066
Lambda: 1.4286e-04
Learner: 'svm'
Properties, Methods
CVMdl is a RegressionPartitionedLinear model. It contains the property Trained, which is a 1-by-1 cell array holding a RegressionLinear model that the software trained using the training set.
Extract the training and test data from the partition definition.
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
Create an anonymous function that measures Huber loss ( = 1), that is,
where
is the residual for observation j. Custom loss functions must be written in a particular form. For rules on writing a custom loss function, see the 'LossFun' name-value pair argument.
huberloss = @(Y,Yhat,W)sum(W.*((0.5*(abs(Y-Yhat)<=1).*(Y-Yhat).^2) + ...
((abs(Y-Yhat)>1).*abs(Y-Yhat)-0.5)))/sum(W);Estimate the training set and test set regression loss using the Huber loss function.
eTrain = loss(Mdl,X(:,trainIdx),Y(trainIdx),'LossFun',huberloss,... 'ObservationsIn','columns')
eTrain = -0.4186
eTest = loss(Mdl,X(:,testIdx),Y(testIdx),'LossFun',huberloss,... 'ObservationsIn','columns')
eTest = -0.4010
Simulate 10000 observations from this model
is a 10000-by-1000 sparse matrix with 10% nonzero standard normal elements.
e is random normal error with mean 0 and standard deviation 0.3.
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);Create a set of 15 logarithmically-spaced regularization strengths from through .
Lambda = logspace(-4,-1,15);
Hold out 30% of the data for testing. Identify the test-sample indices.
cvp = cvpartition(numel(Y),'Holdout',0.30);
idxTest = test(cvp);Train a linear regression model using lasso penalties with the strengths in Lambda. Specify the regularization strengths, optimizing the objective function using SpaRSA, and the data partition. To increase execution speed, transpose the predictor data and specify that the observations are in columns.
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Solver','sparsa','Regularization','lasso','CVPartition',cvp); Mdl1 = CVMdl.Trained{1}; numel(Mdl1.Lambda)
ans = 15
Mdl1 is a RegressionLinear model. Because Lambda is a 15-dimensional vector of regularization strengths, you can think of Mdl1 as 15 trained models, one for each regularization strength.
Estimate the test-sample mean squared error for each regularized model.
mse = loss(Mdl1,X(:,idxTest),Y(idxTest),'ObservationsIn','columns');
Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a regression model. Retrain the model using the entire data set and all options used previously, except the data-partition specification. Determine the number of nonzero coefficients per model.
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
In the same figure, plot the MSE and frequency of nonzero coefficients for each regularization strength. Plot all variables on the log scale.
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
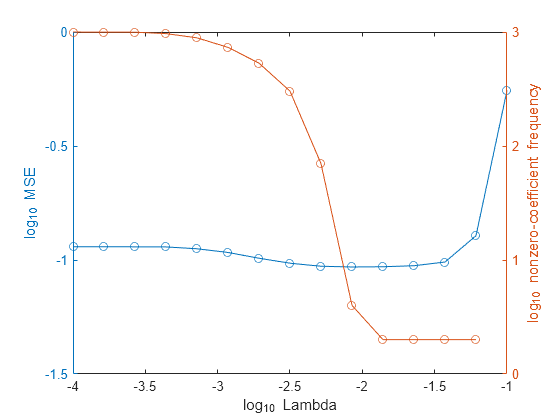
Select the index or indices of Lambda that balance minimal classification error and predictor-variable sparsity (for example, Lambda(11)).
idx = 11; MdlFinal = selectModels(Mdl,idx);
MdlFinal is a trained RegressionLinear model object that uses Lambda(11) as a regularization strength.