Use Machine Learning and Deep Learning to Categorize Risk in Underground Utility Distribution Cable Systems
Steffen Ziegler, IMCORP
Use machine learning algorithms and deep learning algorithms to predict underground distribution cable system failures. Predictive maintenance begins with understanding how cable system failures occur. Analyzing and interpreting results from partial discharge (PD) measurements taken in the field can be a complex task for humans. Machine learning algorithms and deep learning algorithms are used to automatically identify and categorize markers of defects contained in the PD measurements. These algorithms are used to categorize different defect types by risk of going to failure soon. Differentiating cables with “high to low risk defects” along with those that are “defect free” enables predictive maintenance. Examples of identified defects will be presented.
Published: 22 Jun 2020
My name is Steffen Ziegler. I'm the director for signal analysis and artificial intelligence at IMCORP. I'm presenting today with Shishir Shekkar, who is the worldwide manager of energy powered utilities industry at The MathWorks, an approach of machine learning and deep learning that provides risk categorization to underground utility distribution cable systems.
So underground distribution cable system failures can be predicted. Each year, millions of people and thousands of businesses are impacted by underground cable system failures. Also, it's important to know that over the past 40 years cable and accessory manufacturers have used offline 50/60 hertz PD testing of specific pC sensitivity levels.
So different approaches for cable system maintenance are possible-- reactive, preventive, and predictive. Predictive maintenance begins with understanding how cable system failures occur. Analyzing and interpreting results from partial discharge measurements taken in the field can be a very complex task for humans.
So machine learning and deep learning approaches were used to solve specific challenges with partial defect classification. Machine learning algorithms and deep learning algorithms are used to automatically identify and categorize specific markers of defects contained in the partial discharge measurements.
These algorithms are used to classify different defect types by risk of going to failure soon. Differentiating cables with high to low-risk defects along with those that are defect free enables predictive maintenance. Examples of identified defects will be presented. The predictive maintenance workflow is being presented at the end of this presentation.
So why performing predictive maintenance? As I already said, each year, millions of people and thousands of businesses are without power or impacted by an underground cable system failure. Those failures can be predicted. So identifying cable defects before failure begins with understanding how cable system failures occur.
Differentiating cables with high to low-risk effects along with those that defect free, and by the way, the defect-free group is quite large and able to predict this cable system maintenance. So over 99% of solid dielectric cable system failures are associated with that effect that's called partial discharge.
Partial discharge is a slow degeneration of the cable insulating material, which eventually leads to a failure. So for over 40 years, cable and accessory manufacturers have used offline 50 o or 60 hertz PD testing with specific sensitivity levels as a quality control standard.
So the manufacturers are using their factory and offline tests. They [Excite] the cable with an over-voltage at 50 or 60 hertz sinusoidal voltage. They do at the same time the sensitivity and calibration measurements to ensure that the measurement actually makes sense. And it's done in a shielded environment in the factory. So in a Faraday cage, that's how the ambient noise gets removed.
But how do you do the same thing in the field? In the field, it's a little different. You don't have that Faraday cage or the EMC chamber. You need to actually have equipment that is exciting the cable at 50/60 hertz, removes the noise, and you can calibrate to the specific standards as the manufacturers do and collect the data.
The reason I'm saying this is it's very important if you want to predict the future condition of an underground cable system, that's the measurement is as close as possible to the actual operating conditions.
Very commonly used is the reactive approach for maintaining cable system assets. So a cable system failure causes an unpredicted service interruption. But that's not the only bad thing about it. Economically, the owner of the cable loses a lot of money. First of all, the service crews have to be sent out, and it's at an unknown and unpredictable time.
It's the reactive approach that costs quite a bit of money. The customer is not pleased with an outage. And the loss of image from an energy provider is a very important thing to consider. The liability indices are impacted. SAIDI, SAIFI, CADI, and MAIFI. And those should be kept at specific levels that are prescribed.
And then very interest could be the potential collateral damage. Just think about manholes, manhole covers that could fly up in the air during a cable failure. All these things that are of high visibility and are not just causing collateral damage but damage the reputation of an energy provider.
So as Steffen just mentioned, why reactive approach is not a good approach, because it can be very expensive to replace that piece of cable. So what we have seen historically, many of the utility companies use reactive approach to do maintenance. Most recently, they have been moving from reactive to more preventative approach that is to maintain a particular improvements.
But there is still a problem with that. You have to do unnecessary maintenance, which can be wasteful of time and money. So how do you save both in time and money? And one way to do that is predictive maintenance. [However] predictive maintenance is not easy. Forecasting when a problem will arise within equipment, it is a very difficult thing to do forecast.
So now we have technologies that enable you to do predictive maintenance, technology that has machine learning, deep learning, can help you identify when your equipment might fail in the field and even show you how you can actually develop these predictive measurement algorithms for different application areas with the underground cables.
So when you're trying to develop a predictive maintenance algorithm, you could use multiple approaches. I believe could do a more incremental approach within a white-box approach, which is the first principles modeling, or you could do a black-box approach that is more data-driven approach that is a method of applying data-driven modeling that is the data you have some sensors.
However, there are both pros and cons of both of these approaches. The model-driven approach combined with a data-driven approach can be a better technique, because that lets you do highly accurate predictive model.
So in many cases, you might have data or you know how the figures look like. In many cases, you may not know how the figure look like. So when you do not know how the figure look like, you can actually develop system models, run multiple simulations, and then use the data from those simulations, combine it with sensor data to develop predictive algorithms.
As I mentioned, you could use AI technique to develop predictive maintenance algorithms. So when we talk about AI, what is actually AI? Artificial intelligence uses different techniques, which is either machine learning techniques or a deep learning technique. You would use machine learning or deep learning, depending on the type of data you have, but also depending on if you know what that figure looked like.
So if you do not have labeled data or if you do not know voltage can then look like, you generally use unsupervised learning, where you're trying to use clustering technique. Then you know what the failure look like or you have label data, then you mostly take supervised learning approach. You use techniques of classification or regression.
Another approach is by using deep learning technique. So when you have a nice amount of data, especially when you have time series data or image data, you could also use deep learning techniques. And we will show you when can you use second type of techniques and when it is more useful to use deep learning or when it is more useful to use machine learning.
The main difference between machine learning and deep learning is that machine learning typically involves some kind of feature extraction. So when you have signal waveforms or [hundreds of] waveforms, and you want to work with certain features, then you typically use machine learning techniques. These learning methods typically involve feature extraction. You kind of [skip that step] and that's another advantage of deep learning.
So I will bring back the differences between machine learning and deep learning. And it's that deep learning performs end-to-end learning. That is, we are skipping the [feature] extraction process. So basically, we are doing end-to-end learning by the learning features, the presentations, and tasks that appear from data, which could be images, text, or sound data or data from your sensors.
The main difference between machine learning and deep learning is deep learning algorithms can retrieve the data. Particularly, you want to use machine learning when you have huge amounts of data, whereas If you're using machine learning approach for not a whole lot of data, your models are going to be saturated. So when you're working with huge amount of data, it would be better to use deep learning approaches.
So many people in the [utility] industry ask, what kind of data should we have where we can use machine learning or deep learning techniques? It doesn't really matter. You can use different types of data. Although, depending on the type of data, you might use a different approach or a different technique.
For example, if you're working with numeric data, you generally use machine learning or LSTM. If you have time series data, data from your sensors, or if you have fixed data, that is logs recorded by your linemen or your crews in different formats, you can actually use either CNN, convolutional neural networks, or LSTM. That is Long Short-Term Memory. If you're looking at image data, if you have images of the assets or you have [vegetation] images, you generally want to use learning technique.
As Shishir has already mentioned, different types of learning approaches lend themselves to the application phase. In our case, we have chosen two approaches. One is the machine learning approach, and the other one is the deep learning approach when it comes to partial discharge signal waveforms.
Those partial discharge signals are time series digitized signals, and they lend themselves very well to machine learning model where the extracted features of time series are being processed or to a deep learning approach, the long short-term memory approach where the waveforms are actually classified based on the features in the time series data.
The reason to develop such a system is simple. It is very difficult for humans to interpret partial discharge signals very consistent. So you might have humans that interpret signals one way and other humans that interpret them the other way. So we would like to have a system that is actually learning from humans and at the same time being very precise and consistent. That's why we have chosen those two approaches.
In this example, I would like to demonstrate to you that machine learning approach that was based on a boosted tree of methodology was very successful on a data pool of 353,000 labeled waveform parameters. The waveforms were actually labeled by human expert analysts and were not labeled one by one, as you can imagine. They were labeled with a very specific tool that humans can use and classify partial discharge signals with spot operation and others from processing needs.
So we found out that out of 43 abstracted features, only eight were necessary to predict to the overall accuracy of 94%. So 94% is a success. We wanted to find out how much closer to 100% we can go, and I'll give you a little update in a couple of slides about that.
The next approach that we applied to our challenge was the deep learning approach on the partial discharge time series. So we used a long short-term memory approach, where we used the time remain signal as a feature and as well as added other features on there. And this time, we employed this model on a pool of about 900,000 human labeled signal waveforms. Then we found out the overall validation accuracy is 93%.
As Shishir has mentioned before, for deep learning it is more advisable to actually have more data. So we process more data, and studies have been performed in larger pools that I wanted to give you an example on, about 900,000 human labeled waveforms. So 93% is not bad either. But the question is why isn't it working closer to 100%?
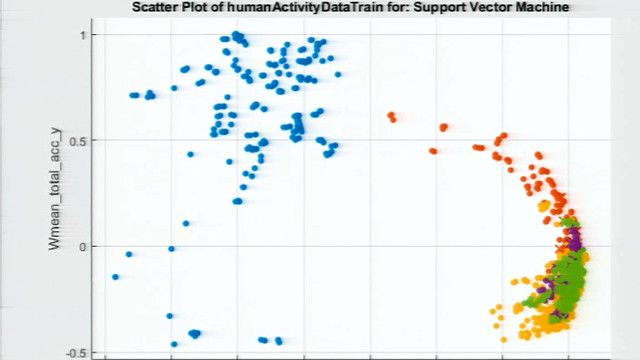
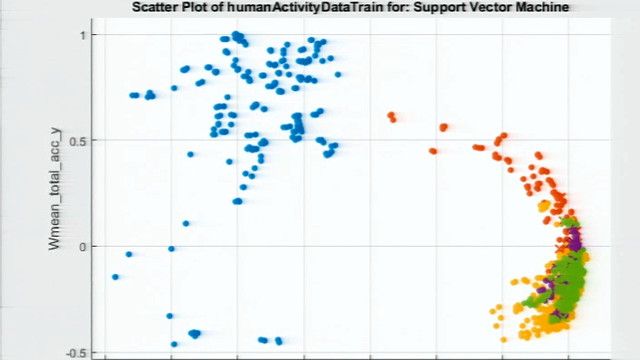
So here are the reasons. When you look at this curve, the probability is being plotted against the partial discharge signals. And they have been sorted by probability from 1 being a true partial discharge right here to 0, like the very clear nonpartial discharge signal.
And you see that you can categorize that pool of data into three main buckets. One is the clear partial discharge. The other one is the clear nonpartial discharge. And in the middle there is a transition which you would have wished would be a little steeper. Those are ambiguous waveforms.
So when we went back and looked, especially at the ambiguous pool, we found out that some of those signals actually have features that make them look either way. And this depends more or less on the signal data quality. So we know the inputs have to be of a specific quality if you would like to classify very precisely.
So we can either do better training in that zone or we can clean up our signals to begin with. That's all for signal capture and signal processing issue. Or we can apply different models to that specific zone in order to have a higher validation accuracy.
As you know, working with images is far more easier compared to working with signals. And we kind of use the same ideas when we're trying to use deep learning approaches for signal applications. So as Steffen explained, how they use LSTM on those signals, so taking it forward from the same example, you could actually convert those signal data for time series data into images or into time frequency transformations.
And that technique is very easy for you to interpret or analyze those partially discharge signals. And you'll see how converting these time series data into time frequency domain, you can actually identify risks in the [underground] cables by looking at different image patterns.
So this specific slide shows you how an LSTM long short-term memory network is being trained inside MATLAB. I told you about this pool of 900,000 people before. So when actually selecting data for training, there are considerations about the ratio between positive features and negative thought features, the specific number of epochs you want to run, the number of iterations, and the specific data conditioning before you start training a model.
In this case, the model training takes several hours, sometimes even several days. And we found out that's important condition of the data than to find the right training method in an LSTM network. As I mentioned before, 93% or 94% accuracy is pretty good, but we would like to improve that so that the model compared to a human is almost equally as good.
Another approach that Shishir has mentioned before that helps us to learn some information is the convolutional neural network approach. Convolutional neural network lends itself very well to image recognition or feature recognition on images.
So partial discharge data can also be converted into plots where the partial discharge magnitude in [pico coloumbs] is being plotted against a phase of the excitation voltage. So those are the two pictures you see at the bottom of this presentation.
Those actually have significance. Those pictures can reveal the nature of the partial discharge defect in a cable. Specifically, when partial discharge defects are based on associated electrical treeing, which is a microdefect in the cable insulation, those defects are much higher of risk of failure than other types of defects.
So we are interested and our customers are interested in finding out the high-risk defect that eventually make a cable fail. In this case, we found out that the convolutional neural network was trained very successfully on identifying those partial discharge defects related to electrical treeing. That allowed us and enabled us to devise a partial discharge severity factor that is actually serving now as a risk categorization for a specific partial discharge defect.
This is done automatically with a machine so the human will be alerted that there might be defects that might be more risky than others, which actually helps us to inform our customers that there are specific defects in the cable that need much more urgent attention than other defects. So it allows actually operational people at-- network owners, cable network owners-- to categorize and classify and prioritize there for repairs on cables.
Here are just a few examples of those electrical tree-type defects that the machine has found automatically for us. And sure enough, when we looked back into data, went a little closer into the data, we found out those would be the ones that a cable network owner should take care of first.
And this is something that is all being retained in the database that automatically categorizes and prioritizes risk of partial discharge defects going to failure.
So one question that we often got by engineers who are trying to address predictive maintenance algorithms is, when do we start? So one thing that I also ask them is, do you have data? So if you have operational data, and you know how does failure look like, you have logged those failures, you can use that data to get the critical maintenance algorithms and get insights.
But in many cases, you may not have figured it out. You may not have logged failures in the past. So how do you then develop predictive maintenance algorithms? So at that point of time, you could use another approach called [digital twin] approach, where you could actually develop simulation model of various equipment, and then you run multiple simulations, define faults, and [generate] data. So you can use that simulated data to then develop predictive maintenance algorithm to gain insights.
In other cases, if you already have operational data, and you know how this data look like, and you can also work with certain models of equipment. You can actually use both the approaches. You can then run multiple simulations, combining the results of the simulations with the known failure data and then develop predictive maintenance algorithms.
In this case, you have a much better outcome, because you have a lot more data to train your machine learning and deep learning algorithms. And lastly, depending on the type of application, you can deploy this predictive maintenance algorithm either through the cloud or through the hardware edge device.
So once you have built these predictive maintenance algorithms, what next? So in many cases, you can also go beyond doing predictive maintenance. You can also identify the many use for life of your equipment. Again, you can actually know well in advance how much remaining useful life of the equipment exists so that you can do planning much ahead of time to replace those [equipment] on the field.
Now, to develop remaining useful life algorithms, there are multiple methods. You could use similarity-based methods. If you have run-to-failure data, capture data over system's lifetime, you could use degradation method. If the only information that you have is threshold values and their equipment has not failed in the past, then you could use survival method. Then you have only data that is available which corresponds to your trained machine. So you can use different methods to develop remaining use of life algorithms.
As Shishir has just mentioned, the remaining useful life is a very important question that needs to be answered. Especially when you maintain and operate underground cable systems, the costs are very high when you need to replace a cable system. So the question that always comes up and everyone would like to answer is, how much remaining useful life is in my underground cable system?
The remaining useful life is not just a question of time to failure, it's also a question of when economically it's not viable anymore to operate an underground cable system. So typically, and that's why there is a curve that we would like to explain briefly, a cable failure develops over time. And long before the cable actually fails, that defect is already active in a cable.
What is plotted here on the x-axis is time and on the y-axis is the partial discharge inception voltage of a defect. The higher the voltage, the less likely it is that a transient event, a transient over-voltage event, which means it's a very temporary short event, is there that can ignite and make this partial discharge defect active for a very short time.
So there are a few things that you know that can actually make a defect active-- lightning. If lightning strike strikes close to cable or hits actually a visor that is connected to a cable, that cable will see an over-voltage, and the already existing partial discharge defect is becoming active for a short amount of time for this event and continues to grow and degrade the insulating material or something.
Something is actually a methodology, where artificial over-voltage or high-voltage pulses are injected in an underground power cable to find a failure. Something is not helping you to find an existing failure. It's also continuing to degrade existing defects that are elsewhere in the cable as the over-voltage pauses or switching events. Switching off cables is obviously generating transient over-voltages for a short amount of time.
So every time a partial discharge defect is active in a cable, the inception voltage, a partial discharge inception voltage, is decreasing. So eventually, it will decrease to the level of the operating voltage. But the operating voltage, which is always on, this partial discharge would be continuously being active and very quickly go to failure.
So somewhere in between here-- this is between the blue and the yellow-shaded region, the condition-based assessment, partial discharge assessment has been performed. So we have a point in time measurement of the condition across the cable. Based on that one point in time, it should be possible, and it is possible to actually give predictions about how much longer does it take before the cable will go to failure. We will get to what else you would need to know to make that prediction.
So in summary, what does predictive maintenance algorithm actually do? So there are actually three steps to developing your predictive maintenance algorithm. And basically you are using predictive maintenance algorithm, you're making decisions on your important equipment.
So basically, you have data, and then depending on these questions, is my system operating normally, you would generate an anomaly detection. If your system is behaving abnormally, you would do condition monitoring, and if you want to know how much longer can you operate your equipment, then basically you try to develop remaining useful life estimation.
And by looking at these different aspects of predictive maintenance, then you take certain decisions to either replace your cables or you perform maintenance.
As Shishir just mentioned, the remaining useful life depends on many variables for underground power cable systems. It maybe depends on transient over-voltages, as I have just explained, something in other over-voltages that artificially generated, the operation of the asset is in the lower flow, the current, the temperature of the cable, and also the age and other intrinsic asset data. For instance, how old is the cable? What manufacturer is it? What kind of jacket type does the cable have or does it even a jacket?
So when you look to the very last on this slide, you see a whole layer of different information that is actually being used to predict the remaining useful life of a cable. Other data. You know, when lightning strikes happen, where they happen. Geographical information. How likely is it that this cable will be flooded or not? All these kinds of information flow into the model that helps you to predict how long will the cable endure before it actually fails?
So I will explain before you could also deploy your algorithms on the cloud or on a piece of hardware. So this slide basically talks about the different options that you have with respect deployment. So depending on the different types of applications, for example, if you're going to do [asset health] monitoring and predictive maintenance of your transmission towers, transmission lines, or insulators on transmission towers, or you're trying to do with vegetation management, you typically run-- or you do surveys using helicopters nowadays.
Companies are trying to explore drone technology. So basically, your drone is flying over the transmission lines, flying over the right of way and taking images of vegetation, take images of transmission towers, transmission lines, and other equipment. And particularly, once the images have been taken, images are sent to the cloud.
When you have this MATLAB code [slash] algorithm that's running on the cloud and then giving you results from those predictive algorithms. And then you can then use the results to pick specific decisions. So depending on the type of application, you could do deployment either on the cloud or on the hardware.
So in summary, [as Steffan] have gone through a very good application of doing predictive maintenance of underground cables. So if you're planning to build similar applications for other equipment, you could take either a digital approach or a digital twin approach, or you could do both of it, depending on if you have historical data, if you have the voltage data that kind of shows what the [fault] look like, you can combine that data with simulated data and then use that data to train your predictive models.
So one important ever more here is, a lot of time's actually spent on doing preprocessing, because you might have data from multiple sources. And in the beginning, I showed you a slide that talks about different forms of data. So if you're combining test data, signal data, digital data, monitored data, text data, so it can be a huge task to actually combine all of this data in the different formats, so we can actually run them through these predictive models.
So on average, engineers might spend 50% of their time only doing preprocessing. So that becomes a very important step. The better your data, the better your predictive models, and the better your results.
So once you have the data, you want to make sure that you [clean up] the data and the data is in right format before you can actually [start] develop in predictive models. Once you have those predictive models, you can then deploy them on the cloud or on the hardware, and then you can use them for different applications.
Thank you so much for your attention. Shishir and I would be very happy to answer any possible questions that you might have for us. Thank you very much.
Featured Product