Cuantificación, proyección y poda
Utilice Deep Learning Toolbox™ junto con el paquete de soporte Deep Learning Toolbox Model Compression Library para reducir el uso de memoria y los requisitos computacionales de una red neuronal:
Podando filtros desde las capas de convolución mediante una aproximación de Taylor de primer orden. Después, podrá generar código C/C++, CUDA® o HDL a partir de esta red podada.
Proyectando capas realizando un análisis de componentes principales (PCA) en las activaciones de capa empleando un conjunto de datos representativo de los datos de entrenamiento y aplicando proyecciones lineales en los parámetros que se pueden aprender de la capa. Los pasos hacia adelante de una red neuronal profunda proyectada suelen ser más rápidos cuando se despliega la red en hardware integrado utilizando la generación de código C/C++ sin biblioteca.
Cuantificando los pesos, los sesgos y las activaciones de capas en tipos de datos de precisión enteros escalados. Después, podrá generar código C/C++, CUDA o HDL a partir de esta red cuantificada para el despliegue de GPU, FPGA o CPU.
Analizando su red para la compresión usando la app Deep Network Designer.
Para obtener una descripción detallada de las técnicas de compresión disponibles en Deep Learning Toolbox Model Compression Library, consulte Reduce Memory Footprint of Deep Neural Networks.
Funciones
Apps
| Deep Network Quantizer | Quantize deep neural network to 8-bit scaled integer data types |
Temas
Visión general
- Reduce Memory Footprint of Deep Neural Networks
Learn about neural network compression techniques, including pruning, projection, and quantization.
Poda
- Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection. (Desde R2024b) - Parameter Pruning and Quantization of Image Classification Network
Use parameter pruning and quantization to reduce network size. - Prune Image Classification Network Using Taylor Scores
Reduce the size of a deep neural network using Taylor pruning. - Prune Filters in a Detection Network Using Taylor Scores
Reduce network size and increase inference speed by pruning convolutional filters in a you only look once (YOLO) v3 object detection network. - Prune and Quantize Convolutional Neural Network for Speech Recognition
Compress a convolutional neural network (CNN) to prepare it for deployment on an embedded system.
Proyección y destilación de conocimiento
- Compress Neural Network Using Projection
Compress a neural network using projection and principal component analysis (PCA). - Evaluate Code Generation Inference Time of Compressed Deep Neural Network
This example shows how to compare the inference time of a compressed deep neural network for battery state of charge estimation. (Desde R2023b) - Train Smaller Neural Network Using Knowledge Distillation
Reduce the memory footprint of a deep neural network using knowledge distillation. (Desde R2023b)
Cuantificación
- Quantization of Deep Neural Networks
Learn about deep learning quantization tools and workflows. - Data Types and Scaling for Quantization of Deep Neural Networks
Understand effects of quantization and how to visualize dynamic ranges of network convolution layers. - Quantization Workflow System Requirements
See what products are required for the quantization of deep neural networks. - Supported Layers for Quantization
Learn which deep neural network layers are supported for quantization. - Prepare Data for Quantizing Networks
Learn about supported data formats for quantization workflows. - Quantize Multiple-Input Network Using Image and Feature Data
Quantize a network with multiple inputs. - Export Quantized Networks to Simulink and Generate Code
Export a quantized neural network to Simulink and generate code from the exported model.
Cuantificación para un objetivo GPU
- Generate INT8 Code for Deep Learning Networks (GPU Coder)
Quantize and generate code for a pretrained convolutional neural network. - Quantize Residual Network Trained for Image Classification and Generate CUDA Code
This example shows how to quantize the learnable parameters in the convolution layers of a deep learning neural network that has residual connections and has been trained for image classification with CIFAR-10 data. - Quantize Layers in Object Detectors and Generate CUDA Code
This example shows how to generate CUDA® code for an SSD vehicle detector and a YOLO v2 vehicle detector that performs inference computations in 8-bit integers for the convolutional layers. - Quantize Semantic Segmentation Network and Generate CUDA Code
Quantize a convolutional neural network trained for semantic segmentation and generate CUDA code.
Cuantificación para un objetivo FPGA
- Quantize Network for FPGA Deployment (Deep Learning HDL Toolbox)
Reduce the memory footprint of a deep neural network by quantizing the weights, biases, and activations of convolution layers to 8-bit scaled integer data types. - Classify Images on FPGA Using Quantized Neural Network (Deep Learning HDL Toolbox)
This example shows how to use Deep Learning HDL Toolbox™ to deploy a quantized deep convolutional neural network (CNN) to an FPGA. - Classify Images on FPGA by Using Quantized GoogLeNet Network (Deep Learning HDL Toolbox)
This example shows how to use the Deep Learning HDL Toolbox™ to deploy a quantized GoogleNet network to classify an image.
Cuantificación para un objetivo CPU
- Generate int8 Code for Deep Learning Networks (MATLAB Coder)
Quantize and generate code for a pretrained convolutional neural network. - Generate INT8 Code for Deep Learning Network on Raspberry Pi (MATLAB Coder)
Generate code for deep learning network that performs inference computations in 8-bit integers. - Compress Image Classification Network for Deployment to Resource-Constrained Embedded Devices
Reduce the memory footprint and computation requirements of an image classification network for deployment to resource-constrained embedded devices such as the Raspberry Pi®.
Ejemplos destacados

Prune Image Classification Network Using Taylor Scores
Reduce the size of a deep neural network using Taylor pruning.
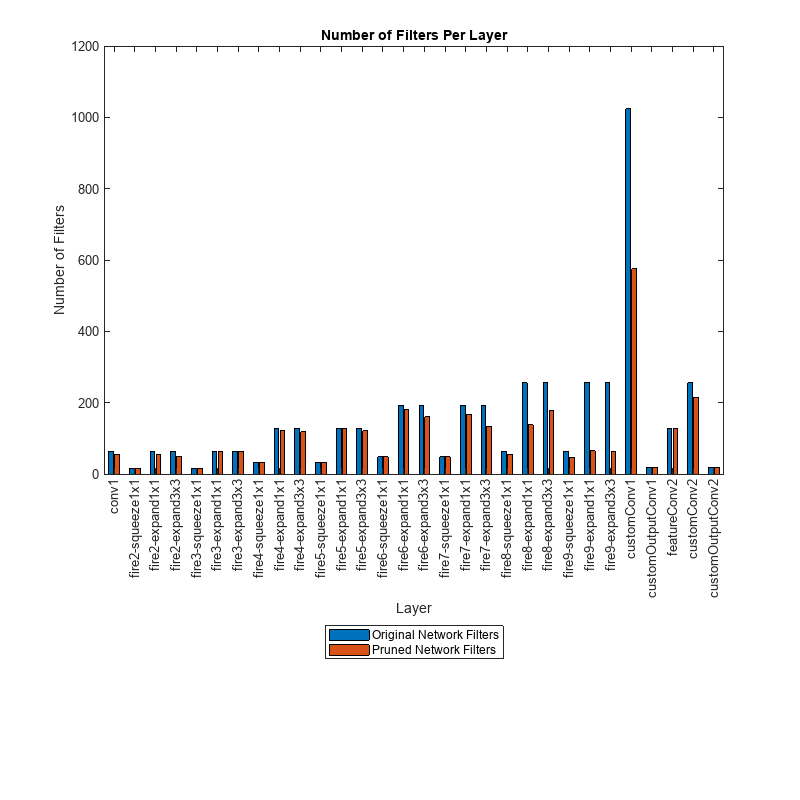
Prune Filters in a Detection Network Using Taylor Scores
Reduce network size and increase inference speed by pruning convolutional filters in a you only look once (YOLO) v3 object detection network.

Compress Neural Network Using Projection
Compress a neural network using projection and principal component analysis (PCA).

Quantize Residual Network Trained for Image Classification and Generate CUDA Code
Quantize the learnable parameters in the convolution layers of a deep learning neural network that has residual connections and has been trained for image classification with CIFAR-10 data.

Prune and Quantize Semantic Segmentation Network
Reduce the memory footprint of a semantic segmentation network and speed-up inference by compressing the network using pruning and quantization.