forward
Calcular salidas de redes de deep learning para entrenamiento
Sintaxis
Descripción
Algunas capas de deep learning se comportan de forma diferente durante el entrenamiento y la inferencia (predicción). Por ejemplo, durante el entrenamiento, las capas de abandono establecen elementos en cero de forma aleatoria para ayudar a evitar el sobreajuste, pero, durante la inferencia, las capas de abandono no cambian la entrada.
Para calcular salidas de red para entrenamiento, utilice la función forward. Para calcular salidas de red para inferencia, utilice la función predict.
[ también devuelve un arreglo de celdas de activaciones de las capas de poda. Esta sintaxis solo se puede aplicar si Y1,...,YN,state,pruningActivations] = forward(X1,...,XM)net es un objeto TaylorPrunableNetwork.
Para podar una red neuronal profunda, se requiere el paquete de soporte Deep Learning Toolbox™ Model Compression Library. Este paquete es un complemento gratuito que puede descargarse a través de Add-On Explorer. Como alternativa, consulte Deep Learning Toolbox Model Compression Library.
___ = forward(___, especifica opciones adicionales con uno o más argumentos nombre-valor.Name=Value)
Ejemplos
En este ejemplo se muestra cómo entrenar una red que clasifica dígitos manuscritos con una programación de tasa de aprendizaje personalizada.
Puede entrenar la mayoría de tipos de redes neuronales utilizando las funciones trainnet y trainingOptions. Si la función trainingOptions no proporciona las opciones que necesita (por ejemplo, un solver personalizado), puede definir su propio bucle de entrenamiento personalizado mediante los objetos dlarray y dlnetwork para la diferenciación automática. Para ver un ejemplo de cómo volver a entrenar una red de deep learning preentrenada mediante la función trainnet, consulte Volver a entrenar redes neuronales para clasificar nuevas imágenes.
El entrenamiento de una red neuronal profunda es una tarea de optimización. Considerando una red neuronal como una función , donde es la entrada de la red y es el conjunto de parámetros que se pueden aprender, puede optimizar para que minimice parte del valor de pérdida en función de los datos de entrenamiento. Por ejemplo, optimice los parámetros que se pueden aprender de modo que, para unas entradas determinadas con los objetivos correspondientes , minimicen el error entre las predicciones y .
La función de pérdida usada depende del tipo de tarea. Por ejemplo:
En tareas de clasificación, puede minimizar el error de entropía cruzada entre las predicciones y los objetivos.
En tareas de regresión, puede minimizar el error cuadrático medio entre las predicciones y los objetivos.
Puede optimizar el objetivo mediante el gradiente descendente: minimice la pérdida actualizando iterativamente los parámetros que se pueden aprender dando pasos hacia el mínimo utilizando los gradientes de pérdida con respecto a los parámetros que se pueden aprender. Los algoritmos de gradiente descendente suelen actualizar los parámetros que se pueden aprender utilizando una variante de un paso de actualización de la forma , donde es el número de iteración, es la tasa de aprendizaje y denota los gradientes (las derivadas de la pérdida con respecto a los parámetros que se pueden aprender).
En este ejemplo se entrena una red para clasificar dígitos manuscritos con el algoritmo de gradiente descendente estocástico (sin momento).
Cargar los datos de entrenamiento
Cargue los datos de dígitos como un almacén de datos de imágenes mediante la función imageDatastore y especifique la carpeta que contiene los datos de imagen.
unzip("DigitsData.zip") imds = imageDatastore("DigitsData", ... IncludeSubfolders=true, ... LabelSource="foldernames");
Divida los datos en conjuntos de prueba y de entrenamiento. Reserve el 10% de los datos para las pruebas con la función splitEachLabel.
[imdsTrain,imdsTest] = splitEachLabel(imds,0.9,"randomize");La red usada en este ejemplo requiere imágenes de entrada de un tamaño de 28 por 28 por 1. Para cambiar automáticamente el tamaño de las imágenes de entrenamiento, utilice un almacén de datos de imágenes aumentado. Especifique operaciones de aumento adicionales para realizar en las imágenes de entrenamiento: traslade aleatoriamente las imágenes hasta 5 píxeles a lo largo de los ejes vertical y horizontal. El aumento de datos ayuda a evitar que la red se sobreajuste y memorice los detalles exactos de las imágenes de entrenamiento.
inputSize = [28 28 1]; pixelRange = [-5 5]; imageAugmenter = imageDataAugmenter( ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain,DataAugmentation=imageAugmenter);
Para cambiar el tamaño de las imágenes de prueba de forma automática sin realizar más aumentos de datos, utilice un almacén de datos de imágenes aumentadas sin especificar ninguna operación adicional de preprocesamiento.
augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
Determine el número de clases de los datos de entrenamiento.
classes = categories(imdsTrain.Labels); numClasses = numel(classes);
Definir la red
Defina la red para la clasificación de imágenes.
Para la entrada de imagen, especifique una capa de entrada de imagen con un tamaño de entrada que coincida con los datos de entrenamiento.
No normalice la entrada de la imagen; establezca la opción
Normalizationde la capa de entrada en"none".Especifique tres bloques convolución-batchnorm-ReLU.
Rellene la entrada a las capas de convolución de modo que la salida tenga el mismo tamaño estableciendo la opción
Paddingcomo"same".Para la primera capa de convolución, especifique 20 filtros de tamaño 5. Para las capas de convolución restantes, especifique 20 filtros de tamaño 3.
Para la clasificación, especifique una capa totalmente conectada con un tamaño que coincida con el número de clases.
Para asignar la salida a probabilidades, incluya una capa softmax.
Al entrenar una red mediante un bucle de entrenamiento personalizado, no incluya una capa de salida.
layers = [
imageInputLayer(inputSize,Normalization="none")
convolution2dLayer(5,20,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,20,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,20,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];Cree un objeto dlnetwork a partir del arreglo de capas.
net = dlnetwork(layers)
net =
dlnetwork with properties:
Layers: [12×1 nnet.cnn.layer.Layer]
Connections: [11×2 table]
Learnables: [14×3 table]
State: [6×3 table]
InputNames: {'imageinput'}
OutputNames: {'softmax'}
Initialized: 1
View summary with summary.
Definir la función de pérdida del modelo
El entrenamiento de una red neuronal profunda es una tarea de optimización. Considerando una red neuronal como una función , donde es la entrada de la red y es el conjunto de parámetros que se pueden aprender, puede optimizar para que minimice parte del valor de pérdida en función de los datos de entrenamiento. Por ejemplo, optimice los parámetros que se pueden aprender de modo que, para unas entradas determinadas con los objetivos correspondientes , minimicen el error entre las predicciones y .
Defina la función modelLoss. La función modelLoss toma un objeto net de dlnetwork, un minilote de datos de entrada X con objetivos correspondientes T y devuelve la pérdida, los gradientes de la pérdida con respecto a los parámetros que se pueden aprender en net y el estado de la red. Para calcular los gradientes automáticamente, utilice la función dlgradient.
function [loss,gradients,state] = modelLoss(net,X,T) % Forward data through network. [Y,state] = forward(net,X); % Calculate cross-entropy loss. loss = crossentropy(Y,T); % Calculate gradients of loss with respect to learnable parameters. gradients = dlgradient(loss,net.Learnables); end
Definir funciones de SGD
Cree la función sgdStep, que toma los parámetros y los gradientes de la pérdida con respecto a los parámetros y devuelve los parámetros actualizados utilizando el algoritmo de gradiente descendente estocástico, expresado como , donde es el número de iteración, es la tasa de aprendizaje y denota los gradientes (las derivadas de la pérdida con respecto a los parámetros que se pueden aprender).
function parameters = sgdStep(parameters,gradients,learnRate) parameters = parameters - learnRate .* gradients; end
No es necesario definir una función de actualización personalizada para los bucles de entrenamiento personalizados. Como alternativa, puede utilizar funciones de actualización integradas como sgdmupdate, adamupdate y rmspropupdate.
Especificar las opciones de entrenamiento
Entrene con un tamaño de minilote de 128 y una tasa de aprendizaje de 0,01 durante quince épocas.
numEpochs = 15; miniBatchSize = 128; learnRate = 0.01;
Entrenar un modelo
Cree un objeto minibatchqueue que procese y gestione minilotes de imágenes durante el entrenamiento. Para cada minilote:
Utilice la función de preprocesamiento de minilotes personalizada
preprocessMiniBatch(definida al final de este ejemplo) para convertir los objetivos en vectores codificados one-hot.Dé formato a los datos de imagen con las etiquetas de dimensión
"SSCB"(espacial, espacial, canal, lote). De forma predeterminada, el objetominibatchqueueconvierte los datos en objetosdlarraycon el tipo subyacentesingle. No dé formato a los objetivos.Descarte los minilotes parciales.
Entrene en una GPU, si se dispone de ella. De forma predeterminada, el objeto
minibatchqueueconvierte cada salida engpuArraysi hay una GPU disponible. Utilizar una GPU requiere Parallel Computing Toolbox™ y un dispositivo GPU compatible. Para obtener información sobre los dispositivos compatibles, consulte GPU Computing Requirements (Parallel Computing Toolbox).
mbq = minibatchqueue(augimdsTrain,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB" ""], ... PartialMiniBatch="discard");
Calcule el número total de iteraciones para monitorizar el progreso del entrenamiento.
numObservationsTrain = numel(imdsTrain.Files); numIterationsPerEpoch = floor(numObservationsTrain / miniBatchSize); numIterations = numEpochs * numIterationsPerEpoch;
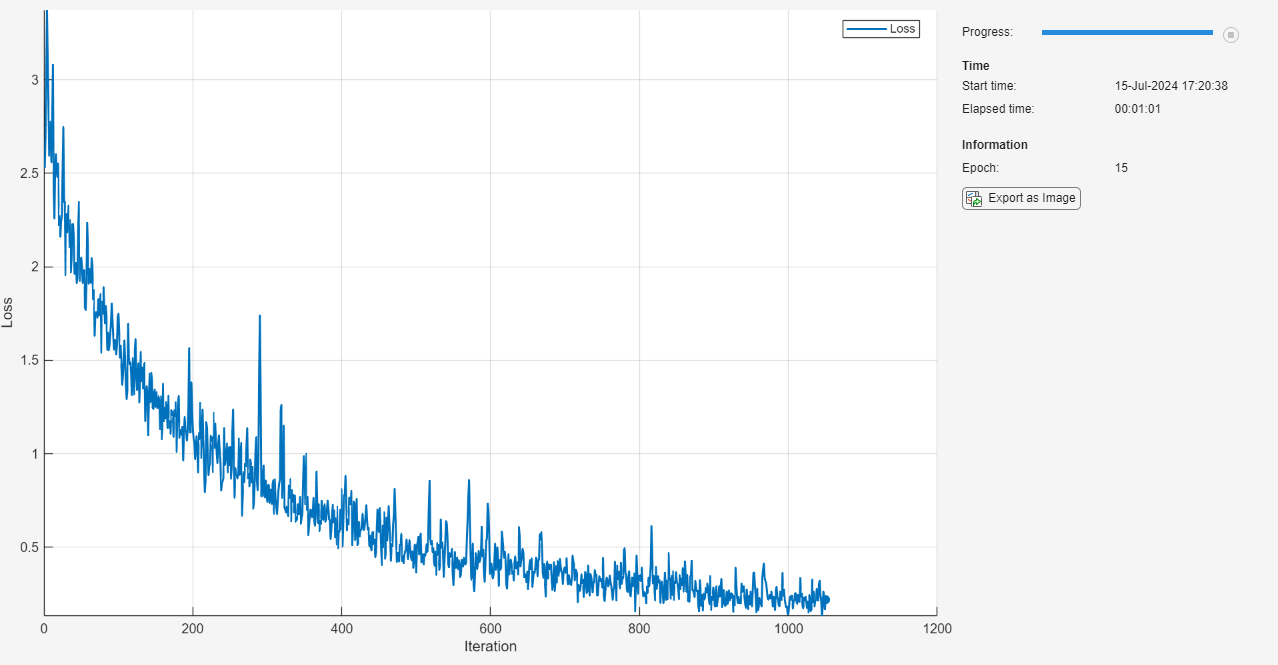
Inicialice el objeto TrainingProgressMonitor. Dado que el cronómetro empieza cuando crea el objeto de monitorización, asegúrese de crear el objeto cerca del bucle de entrenamiento.
monitor = trainingProgressMonitor( ... Metrics="Loss", ... Info="Epoch", ... XLabel="Iteration");
Entrene la red con un bucle de entrenamiento personalizado. Para cada época, cambie el orden de los datos y pase en bucle por minilotes de datos. Para cada minilote:
Evalúe la pérdida, los gradientes y el estado del modelo utilizando las funciones
dlfevalymodelLossy actualice el estado de la red.Actualice los parámetros de red usando la función
dlupdatecon la función de actualización personalizada.Actualice la pérdida y los valores de época en la monitorización del progreso del entrenamiento.
Detenga el proceso si la propiedad Stop de la monitorización se ha establecido como verdadero. El valor de la propiedad Stop del objeto
TrainingProgressMonitorcambia a verdadero cuando hace clic en el botón Stop.
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Shuffle data. shuffle(mbq); % Loop over mini-batches. while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; % Read mini-batch of data. [X,T] = next(mbq); % Evaluate the model gradients, state, and loss using dlfeval and the % modelLoss function and update the network state. [loss,gradients,state] = dlfeval(@modelLoss,net,X,T); net.State = state; % Update the network parameters using SGD. updateFcn = @(parameters,gradients) sgdStep(parameters,gradients,learnRate); net = dlupdate(updateFcn,net,gradients); % Update the training progress monitor. recordMetrics(monitor,iteration,Loss=loss); updateInfo(monitor,Epoch=epoch); monitor.Progress = 100 * iteration/numIterations; end end
Probar un modelo
Pruebe la red neuronal con la función testnet. Evalúe la precisión de la clasificación de una sola etiqueta. La precisión es el porcentaje de predicciones correctas. De forma predeterminada, la función testnet usa una GPU en caso de que esté disponible. Para seleccionar el entorno de ejecución manualmente, utilice el argumento ExecutionEnvironment de la función testnet.
accuracy = testnet(net,augimdsTest,"accuracy")accuracy = 96.3000
Visualice las predicciones en una gráfica de confusión. Realice predicciones con la función minibatchpredict y convierta las puntuaciones de clasificación en etiquetas con la función scores2label. De forma predeterminada, la función minibatchpredict usa una GPU en caso de que esté disponible. Para seleccionar el entorno de ejecución manualmente, utilice el argumento ExecutionEnvironment de la función minibatchpredict.
scores = minibatchpredict(net,augimdsTest); YTest = scores2label(scores,classes);
Visualice las predicciones en una gráfica de confusión.
TTest = imdsTest.Labels; figure confusionchart(TTest,YTest)
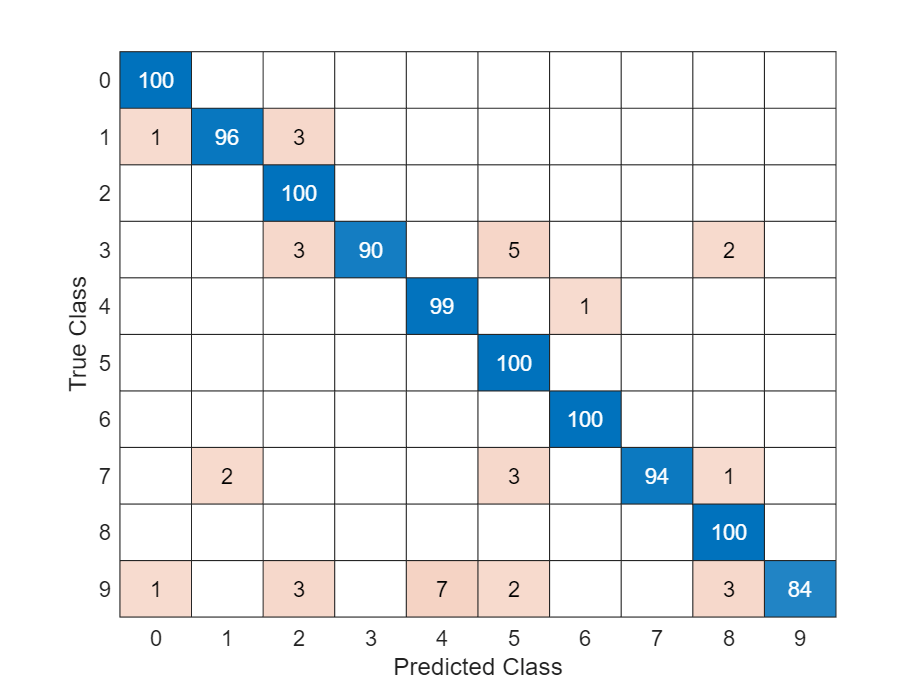
Los valores grandes de la diagonal indican predicciones precisas para la clase correspondiente. Los valores grandes fuera de la diagonal indican una fuerte confusión entre las clases correspondientes.
Funciones de apoyo
Función de preprocesamiento de minilotes
La función preprocessMiniBatch preprocesa un minilote de predictores y etiquetas dando los siguientes pasos:
Preprocesa las imágenes usando la función
preprocessMiniBatchPredictors.Extrae los datos de la etiqueta del arreglo de celdas entrante y los concatena en un arreglo categórico a lo largo de la segunda dimensión.
Hace una codificación one-hot de las etiquetas categóricas en arreglos numéricos. La codificación en la primera dimensión produce un arreglo codificado que coincide con la forma de la salida de la red.
function [X,T] = preprocessMiniBatch(dataX,dataT) % Preprocess predictors. X = preprocessMiniBatchPredictors(dataX); % Extract label data from cell and concatenate. T = cat(2,dataT{:}); % One-hot encode labels. T = onehotencode(T,1); end
Función de preprocesamiento de predictores de minilotes
La función preprocessMiniBatchPredictors preprocesa un minilote de predictores extrayendo los datos de imagen del arreglo de celdas de entrada y concatenándolos en un arreglo numérico. Para la entrada en escala de grises, la concatenación sobre la cuarta dimensión añade una tercera dimensión a cada imagen, para usarla como dimensión de canal única.
function X = preprocessMiniBatchPredictors(dataX) % Concatenate. X = cat(4,dataX{:}); end