Reinforcement Learning Agents
The goal of reinforcement learning is to train an agent to complete a task within an uncertain environment. At each time interval, the agent receives observations and a reward from the environment and sends an action to the environment. The reward is an immediate measure of how successful the previous action (taken from the previous state) was with respect to completing the task goal.
The agent and the environment interact at each of a sequence of discrete time steps as described in Reinforcement Learning Environments and illustrated in the following figure.
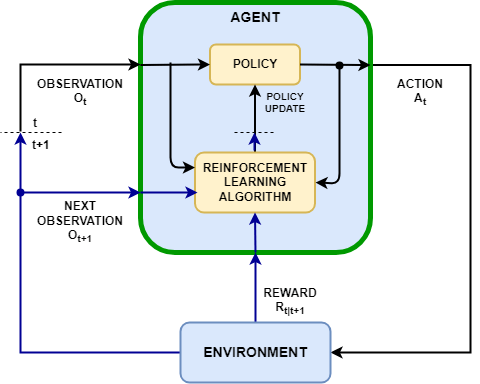
By convention, the observation can be divided into one or more
channels each of which carries a group of single elements all belonging
to either a numeric (infinite and continuous) set or to a finite (discrete) set. Each group
can be organized according to any number of dimensions (for example a vector or a matrix).
Note that only one channel is allowed for the action, while the reward must be a numeric
scalar. For more information on specification objects for actions and observations, see
rlFiniteSetSpec and
rlNumericSpec.
The agent contains two components: a policy and a learning algorithm.
The policy is a mapping from the current environment observation to a probability distribution of the actions to be taken. Within an agent, the policy is implemented by a function approximator with tunable parameters and a specific approximation model, such as a deep neural network.
The learning algorithm continuously updates the policy learnable parameters based on the actions, observations, and rewards. The goal of the learning algorithm is to find an optimal policy that maximizes the expected discounted cumulative long-term reward received during the task.
Depending on the agent, the learning algorithm operates on one or more parameterized function approximators that learn the policy. Approximators can be used in two ways.
Critics — For a given observation and action, a critic returns an approximation of the policy value (that is, the policy expected discounted cumulative long-term reward).
Actor — For a given observation, an actor returns the action that (often) maximizes the policy value.
Agents that use only critics to select their actions rely on an indirect policy representation. These agents are also referred to as value-based, and they use an approximator to represent a value function (value as a function of the observation) or Q-value function (value as a function of observation and action). In general, these agents work better with discrete action spaces but can become computationally expensive for continuous action spaces.
Agents that use only actors to select their actions rely on a direct policy representation. These agents are also referred to as policy-based. The policy can be either deterministic or stochastic. In general, these agents are simpler and can handle continuous action spaces, though the training algorithm can be sensitive to noisy measurement and can converge on local minima.
Agents that use both an actor and a critic are referred to as actor-critic agents. In these agents, during training, the actor learns the best action to take using feedback from the critic (instead of using the reward directly). At the same time, the critic learns the value function from the rewards so that it can properly criticize the actor. In general, these agents can handle both discrete and continuous action spaces.
For more information on actors, critics, and their theoretical underpinnings, see [1] and the references therein.
Agent Objects
Reinforcement Learning Toolbox™ represents agents with MATLAB® objects. Such objects interact with environments using object functions
(methods) such as getAction, which returns an action as output given an
environment observation.
Note
Agent objects are handle objects, so if you copy the agent into a new variable, the new variable will also always point to the most recent agent version with updated states and parameters. For more information about handle objects, see Handle Object Behavior.
After you create an agent object for a given environment in the MATLAB workspace, you can then use both the environment and agent variables as
arguments for the built-in functions train and sim, which train or
simulate the agent within the environment, respectively.
The software provides different types of built-in agents. For each of these you can manually configure its approximation objects (such as actor or critic) and models (such as neural networks or custom basis function). For most built-in agents you can also use a default network configuration. Alternatively, you can also create your custom agent object.
Built-In Agents
The following tables summarize the types, action spaces, and used approximators for all the built-in agents provided with Reinforcement Learning Toolbox software.
On-policy agents attempt to evaluate or improve the policy that they are using to make decisions, whereas off-policy agents evaluate or improve a policy that can be different from the one that they are using to make decisions, (or from the one that has been used to generate data). For each agent, the observation space can be discrete, continuous or mixed.
On-Policy Built-In Agents: Type and Action Space
| Agent | Type | Action Space |
|---|---|---|
| SARSA Agent | Value-Based | Discrete |
| REINFORCE Policy Gradient (PG) Agent | Policy-Based | Discrete or continuous |
| Actor-Critic (AC) Agent | Actor-Critic | Discrete or continuous |
| Trust Region Policy Optimization (TRPO) Agent | Actor-Critic | Discrete or continuous |
| Proximal Policy Optimization (PPO) Agent | Actor-Critic | Discrete or continuous |
Off-Policy Built-In Agents: Type and Action Space
| Agent | Type | Action Space |
|---|---|---|
| Q-Learning Agent | Value-Based | Discrete |
| LSPI Agent | Value-Based | Discrete |
| Deep Q-Network (DQN) Agent | Value-Based | Discrete |
| Deep Deterministic Policy Gradient (DDPG) Agent | Actor-Critic | Continuous |
| Twin-Delayed Deep Deterministic (TD3) Policy Gradient Agent | Actor-Critic | Continuous |
| Soft Actor-Critic (SAC) Agent | Actor-Critic | Discrete, Continuous, or Hybrid |
| Model-Based Policy Optimization (MBPO) Agent | Actor-Critic | Discrete or continuous |
Built-In Agents: Critics Used by Each Agent
| Critic | Q,SARSA, DQN | PG | AC, PPO, TRPO | SAC | DDPG, TD3 |
|---|---|---|---|---|---|
Value function critic V(S), which you can create using | X (if baseline is used) | X | |||
Q-value function critic Q(S,A), which you can create using | X | X (continuous action space SAC) | X | ||
Multi-output Q-value function critic Q(S), for discrete action spaces, which you can create using | X | X (discrete and hybrid action space SAC) |
The LSPI agent must use a linear-in-the-parameters custom basis function, which you can
create using rlQValueFunction.
Built-In Agents: Actors Used by Each Agent
| Actor | Q, DQN, SARSA | PG | AC, PPO, TRPO | SAC | DDPG, TD3 |
|---|---|---|---|---|---|
Deterministic policy actor π(S), which you can create using | X | ||||
Stochastic (Multinoulli) policy actor π(S), for discrete action spaces, which you can create using | X | X | X | ||
Stochastic (Gaussian) policy actor π(S), for continuous action spaces, which you can create using | X | X | |||
Stochastic policy actor π(S), for hybrid action spaces, which you can create using | X | X |
Default Built-In Agents — A default built-in agent is an agent with default approximators and options, that is, an agent in which the actor and critics use default networks and have default options. You can create default agents of any type (except Q-learning, LSPI and SARSA) using just the observation and action specifications from the environment. To do so, at the MATLAB command line, perform the following steps.
Create observation specifications for your environment. If you already have an environment object, you can obtain these specifications using
getObservationInfo.Create action specifications for your environment. If you already have an environment object, you can obtain these specifications using
getActionInfo.If needed, specify the number of neurons in each learnable layer of the default network or whether to use an LSTM layer. To do so, create an agent initialization option object using
rlAgentInitializationOptions.If needed, specify agent options by creating an options object set for the specific agent. This option object in turn includes
rlOptimizerOptionsobjects that specify optimization objects for the agent actor or critic.Create the agent using the corresponding agent constructor function. The resulting agent contains the appropriate actor and critics listed in the previous table. The actor and critic use default agent-specific deep neural networks as internal approximators. The agent and approximator options are set to their default values.
Built-In Agents with Custom Approximators —Alternatively, you can create built-in agents using custom actor and critic approximators (typically approximators relying on custom neural networks). To do so, first you create your own approximators, and use them to create your actor and critic objects. Then, you use these actor and critic objects to create the agent. For more information on actors and critics, see Create Actors, Critics, and Policy Objects.
You can also use the Reinforcement Learning Designer app to import an existing environment and interactively design DQN, DDPG, PPO, TRPO, TD3 and SAC agents. The app allows you to train and simulate the agent within your environment, analyze the simulation results, refine the agent parameters, and export the agent to the MATLAB workspace for further use and deployment. For more information, see Create Agents Using Reinforcement Learning Designer.
Choosing Agent Type
When choosing an agent, best practice is to start with a simpler (and faster to train) algorithm that is compatible with your action and observation spaces. You can then try progressively more complicated algorithms if the simpler ones do not perform as desired.
Note that PG and AC agents are earlier (and simpler) implementation of policy gradient and actor-critic concepts. While these agents might be relatively easier to tune and memory efficient, in general they have very little functional advantages with respect to PPO, SAC, TD3 and DQN, and are provided mostly for educational purposes.
Similarly, PPO generally performs better than TRPO along all dimensions (with TRPO also being particularly hard to tune). Furthermore, TRPO only supports actors and critics with deep networks for which higher order derivatives can be calculated (therefore, you cannot use actors or critics with recurrent networks, custom basis functions or tables within a TRPO agent).
Discrete action spaces — For deterministic problems in which a satisfying linear-in-the-parameters approximation of a Q value function might exist (given a suitable set of features), the LSPI agent can learn a good policy quickly and in a relatively stable way, even when the state space is large.
For simple environments with a relatively small discrete action spaces, using a tabular approximator can be viable (provided that the observation space is also discrete). In these cases, the Q-learning and SARSA agents are the simplest compatible agent, with Q-learning usually performing better in terms of training speed and SARSA being slightly more robust.
Because the number of state-action pairs increases exponentially with the number of states and actions, tabular approximation does not scale well to environments with large state and action spaces, because it requires increasing memory and training time as the state space grows larger. In these cases, or when part of your observation space is continuous, unless a custom basis function suffices, use a network approximator.
The agents with discrete action space that support neural approximators are compared in the following picture. The off-policy agents (DQN and SAC) are on top and the four on-policy agents (PPO, TRPO, AC and PG) are on the bottom.
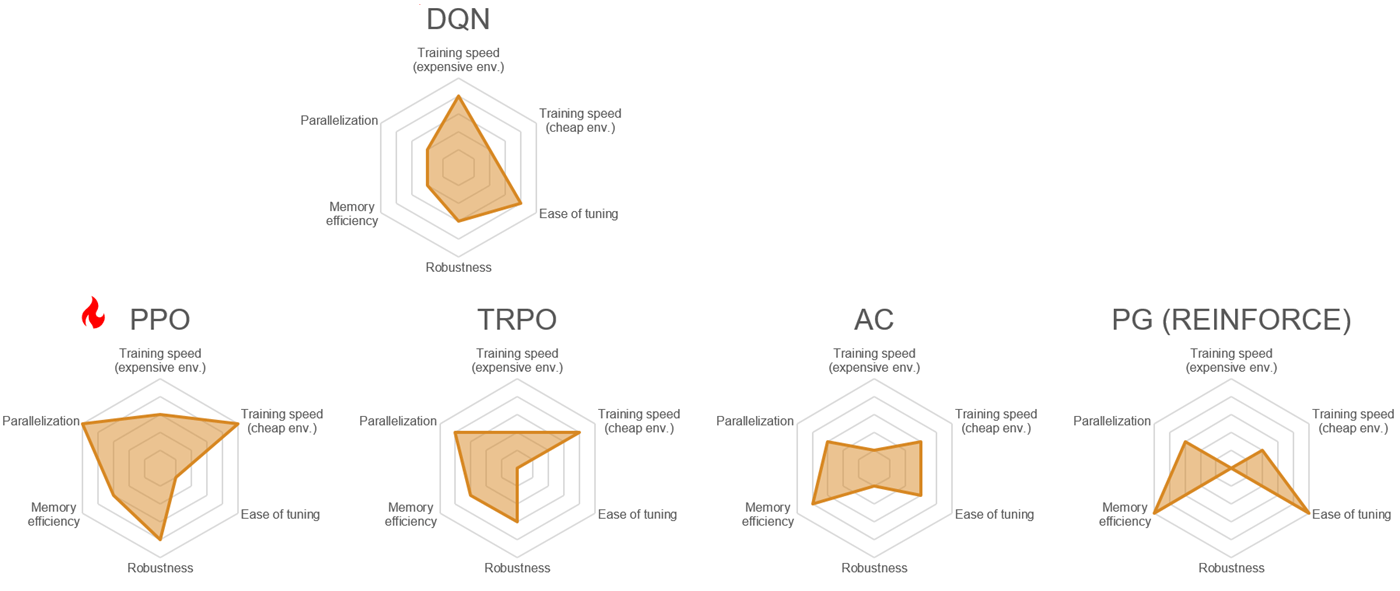
The agents are compared using six different metrics. There are two training speed metrics, for computationally expensive and computationally cheap environments, respectively. Ease of tuning is higher for agents that have less hyperparameters, or hyperparameters that are easier to understand and tune. Robustness is inversely related to the sensitivity to hyperparameters, weights, and initial conditions. Memory efficiency is inversely related to memory usage during training, and parallelization indicates how well the agent learning algorithm scales with the number of parallel workers.
The picture can be summarized as follows:
DQN and PPO exhibit good performance overall.
DQN is generally easier to tune (hence potentially a good starting point) and a relatively good choice for computationally expensive environments.
PPO and SAC have been developed recently, as indicated by the red symbol.
PPO tends to perform better in terms of parallelization and training speed for computationally cheap environments.
SAC tends to perform better in terms of robustness and training speed for computationally expensive environments.
Continuous action spaces — The agents with continuous action space that support neural approximators are compared in the following picture, with the three off-policy agents on the top and the four on-policy agents on the bottom.
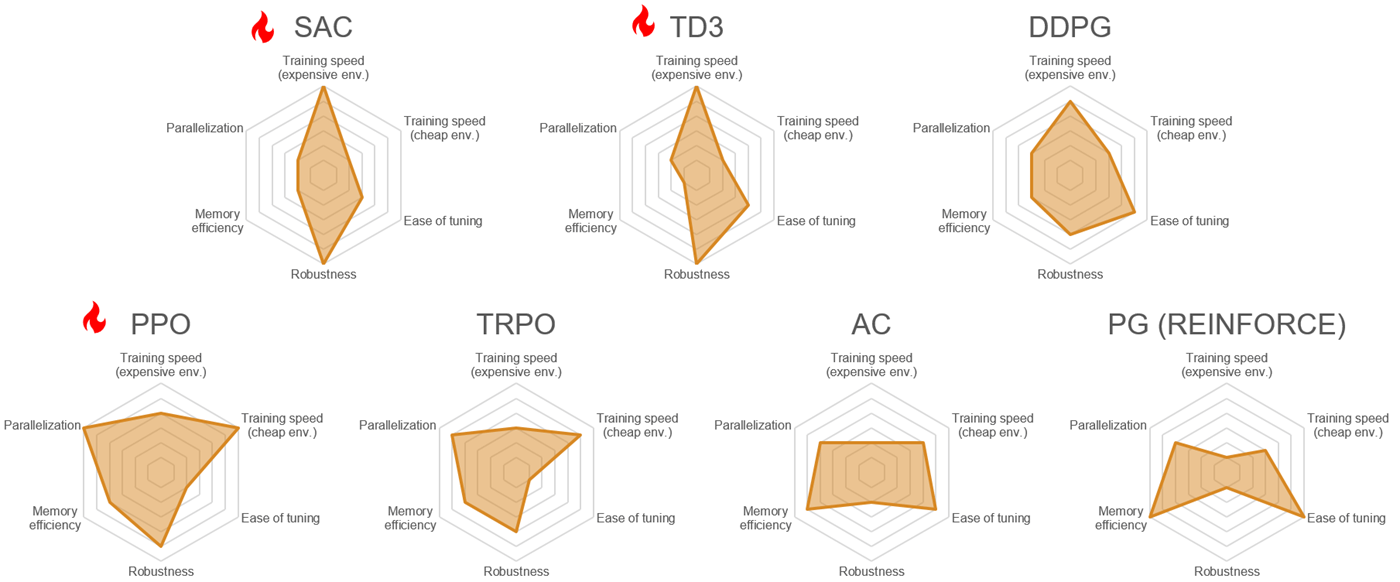
As for the previous picture, the first two metrics are the training speed for computationally expensive and computationally cheap environments, respectively. The ease of tuning is higher for agents that have less hyperparameters, or hyperparameters that are easier to understand and tune. Robustness is inversely related to the sensitivity to hyperparameters, weights, and initial conditions. Memory efficiency is inversely related to memory usage during training, and parallelization indicates how well the agent learning algorithm scales with the number of parallel workers.
The picture for agents that support continuous action spaces can be summarized as follows:
DDPG is the easiest to tune, followed by TD3, SAC and PPO.
DDPG is a good starting point, and tends to perform well overall.
Both TD3 and SAC are improved, more complex, and robust versions of DDPG, and are excellent choices for computationally expensive environments.
PPO is harder to tune but generally performs well overall. In particular, it is an excellent choice for computationally cheap environments, and is highly parallelizable.
SAC, which generates stochastic policies that can be useful for exploration, is slightly harder to tune but can be more memory efficient. This agent tends to perform very well for many environments.
Hybrid action spaces — Only SAC supports hybrid action spaces (that is, action spaces containing both a discrete and a continuous part). Hybrid action spaces are specified by two action channels, a discrete one and a continuous one. You can define these channels using a vector containing one
rlFiniteSetSpecobject followed by onerlNumericSpecobject.
Model-Based Policy Optimization
If you are using an off-policy agent different than Q-learning, (DQN, DDPG, TD3, SAC), you can consider using a model-based policy optimization (MBPO) agent to improve your sample efficiency during training. An MBPO agent contains an internal model of the environment, which it uses to generate additional experiences without interacting with the environment.
During training, the MBPO agent generates real experiences by interacting with the environment. These experiences are used to train the internal environment model, which is used to generate additional experiences. The training algorithm then uses both the real and generated experiences to update the agent policy.
An MBPO agent can be more sample efficient than model-free agents because the model can generate large sets of diverse experiences. However, MBPO agents require much more computational time than model-free agents, because they must train the environment model and generate samples in addition to training the base agent.
For more information, see Model-Based Policy Optimization (MBPO) Agent.
Extract Policy Objects from Agents
You can extract a policy object from an agent and then use the getAction function
to generate deterministic or stochastic actions from the policy, given an input observation.
Working with policy objects can be useful for application deployment or custom training
purposes. For more information, see Create Actors, Critics, and Policy Objects.
Custom Agents
You can also train policies using other learning algorithms by creating a custom agent.
Creating a custom agent allows you to use built-in functions train and sim, which can
train or simulate your agent. To do so, you create a subclass of a custom agent class, and
define the agent behavior using a set of required and optional methods. For more
information, see Create Custom Reinforcement Learning Agents.
Alternatively, to implement a custom learning algorithm which does not rely on
train or sim, you can create a custom training
loop. For more information about custom training loops, see Train Reinforcement Learning Policy Using Custom Training Loop.
References
[1] Sutton, Richard S., and Andrew G. Barto. Reinforcement Learning: An Introduction. Second edition. Adaptive Computation and Machine Learning. Cambridge, Mass: The MIT Press, 2018.
See Also
Objects
rlQAgent|rlSARSAAgent|rlLSPIAgent|rlDQNAgent|rlPGAgent|rlDDPGAgent|rlTD3Agent|rlACAgent|rlSACAgent|rlPPOAgent|rlTRPOAgent|rlMBPOAgent