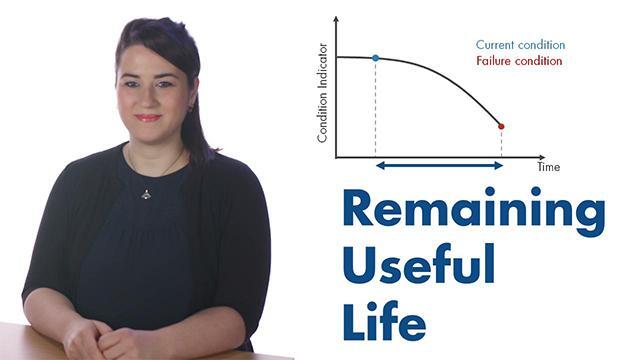
Remaining Useful Life Estimation | Predictive Maintenance, Part 3
From the series: Predictive Maintenance
Melda Ulusoy, MathWorks
Predictive maintenance lets you estimate the remaining useful life (RUL) of your machine. RUL prediction gives you insights about when your machine will fail so you can schedule maintenance in advance.
You’ll learn about the most common RUL estimator models: similarity, survival, and degradation. You can use similarity models to estimate RUL when you have complete histories from similar machines. However, if you have data only from time of failure, then you can use survival models. If failure data is not available but you have knowledge of a safety threshold, you can use degradation models. The video gives an overview of all these models and then discusses one of these techniques – the similarity model – in more detail with an aircraft engine example.
Check out the examples below for the data reduction techniques mentioned in this video:
Published: 11 Feb 2019
One of the goals of predictive maintenance is to estimate the remaining useful life, or RUL in short. In this video, we’re going to learn what RUL is and discuss three common ways to estimate RUL. Here, we see the deterioration of a machine over time. If this is the current health of a machine, then the remaining useful life is computed as the time between this point and failure. Depending on your system, this time period can be represented in terms of days, miles, cycles, or any other quantity.
There are three common ways to estimate RUL: similarity, survival, and degradation models. How do you know which model to use? It really depends on how much you know. Does your data capture the degradation from healthy state to failure, or do you only have data from time of failure, or do you have something in between but know a safety threshold that shouldn’t be exceeded?
Now we’re going to use an aircraft engine example to better understand how these estimator models work. Then, using the same example, we’ll discuss the similarity model more in detail and look at the simulation results of an RUL prediction.
Let’s say this is our engine, and it’s been in operation for 20 flights. What we want to figure out is how many more flights the engine can operate until its parts need repair or replacement. This is data from a fleet with the same type of engine. If we don’t have the complete histories from the fleet but have only the failure data, then we can use survival models to estimate RUL. We know how many engines failed after how many flights, and we also know how many flights the engine has been in operation. The survival model uses a probability distribution of this data to estimate the remaining useful life.
In some cases, no failure data is available from similar machines. But we may have knowledge about a safety threshold that shouldn’t be crossed as this may cause failure. We can use this information as follows. We can fit a degradation model to the condition indicator, which uses the past information from our engine to predict how the condition indicator will change in the future. This way, we can statistically estimate how many cycles there are until the condition indicator crosses the threshold, which helps us estimate the remaining useful life.
The third common way to estimate RUL is to use similarity models. These models are used when we have run-to-failure data. What this means is that we have the complete histories from a fleet with the same type of engine. This includes data from healthy state, degradation, and failure.
Let’s wrap up what we’ve discussed so far: These are the three common ways to estimate RUL. If you have data only from time of failure, then you can use survival models. If failure data is not available but you have knowledge of a safety threshold, you can use degradation models. And if you have complete histories from similar machines, then you can use similarity models to estimate RUL.
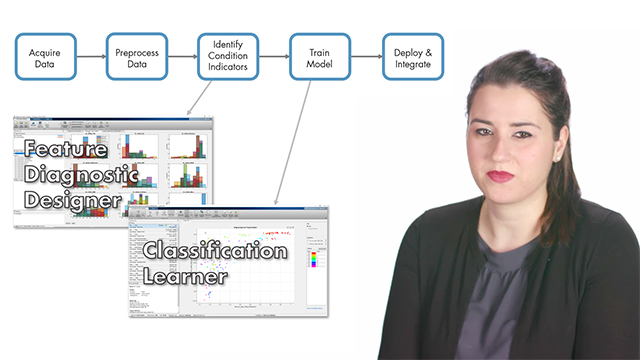
Next, we’ll discuss in more detail one of these techniques—the similarity model—to give you intuition into how the RUL prediction is performed. As you’ll remember from previous videos, the first step of the predictive maintenance workflow is to collect data. For our example here, we’ll be using the Prognostics and Health Management challenge data set that is publicly available on NASA’s data repository. This data set includes the complete histories from 218 different engines, where each engine data contains measurements from 21 sensors. These are sensors such as fuel flow, temperature, and pressure that are placed in various locations in the engine to provide measurements to the control system and monitor the engine’s health. Here’s how one of these sensor measurements looks like for all the engines. On the plot, the x axis shows the number of cycles or flights, whereas the y values represent the averaged sensor values at each flight. Each engine starts in a healthy state and ends in failure.
This data is from one of the sensors, but remember that we have 20 more sensors. So, this is a large data set. If we take a closer look at other sensor readings as well, we see that some of these measurements don’t show a significantly changing trend between healthy state and failure. Therefore, they won’t contribute to the selection of useful features for training a similarity model. So, in the preprocessing step, data reduction is performed by selecting only the most trendable sensors and combining them together to compute condition indicators. In this video, we’re not going to discuss computations performed in these steps, but you can check out the links given in the video description to find out more on different data reduction techniques.
Now that we have the degradation profiles of all the engines, the next step is to train a similarity model using these trajectories and estimate remaining useful life of our engine. This animation shows us how this training is performed. Let’s pause this for a second to discuss what different colors mean. The yellow profile represents our engine for which we want to estimate the remaining useful life. At the current time, the engine is at 60 cycles. The similarity model first finds the closest engine profiles to our engine up to the current cycle. Since our engine deteriorates similar to these engines, they can give us an idea about the expected failure time of our engine because we already know their failure times and we can use this data to fit a probability distribution as seen here. The median of this distribution gives us the remaining useful life estimate of our engine. Note that the original data set is split into two, where we use a larger portion of it to train a similarity model and the rest to test the trained model. This means that we already know the actual RUL for our engine that will later help us evaluate the trained model’s accuracy.
Let’s play the rest of the animation. As we just discussed, at each iteration the similarity model finds the closest paths that are shown in green and computes the RUL using a probability distribution plot. On this plot, the orange line shows the predicted RUL and the black line shows the actual RUL. What we notice here is that the predicted RUL gets closer to the actual RUL as the similarity model gets more and more flight data from our engine over time. If we rewind to the beginning of the animation, we see that the data fed to the model from our engine is only this much and the prediction is 40 cycles off from the true value. And on the upper plot, we see that the closest paths are widely distributed. However, as we get new data from our engine, we train the similarity model with a larger set of data. As a result of this, the prediction accuracy improves over time. We observe that the closest paths become more concentrated, and the predicted RUL starts to converge to the actual RUL. We might consider scheduling maintenance for this engine somewhere around this time as we’re getting closer to the expected failure times of other engines.
In this video, we’ve talked about three common ways to estimate remaining useful life and used an aircraft engine example for training a similarity model. Check out the links given in the video description for more information on how to develop predictive maintenance algorithms with MATLAB and Simulink.










Seleccione un país/idioma
Seleccione un país/idioma para obtener contenido traducido, si está disponible, y ver eventos y ofertas de productos y servicios locales. Según su ubicación geográfica, recomendamos que seleccione: United States.
También puede seleccionar uno de estos países/idiomas:
América
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)