Incorporating Machine Learning Models into Safety-Critical Systems
Overview
Neural networks can obtain state-of-the-art performance in various tasks, including image classification, object detection, speech recognition, and machine translation. Due to this impressive performance, there has been a desire to utilize neural networks for applications in industries with safety-critical components, such as aerospace, automotive, and healthcare. However, while these industries have established processes for verifying and validating traditional software, it is often unclear how to verify the reliability of neural networks. This issue is especially prevalent in aviation, where there is potential to revolutionize the industry. However, existing airborne certification standards present major incompatibilities with Machine Learning technology. These include issues with ML model traceability and explainability and the inadequacy of traditional coverage metrics. The certification of ML-based airborne systems is problematic due to these incompatibilities. Furthermore, new certification standards intended to address these challenges are not yet released.
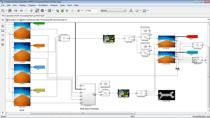
In this session, we’ll introduce a case study for certifying an airborne machine learning system. We’ll build a runway sign classification system that receives images from a forward-facing camera in the aircraft and then detects airport runway signs, aiding the pilot in navigation and situational awareness at the airport. We propose and implement a custom ML certification workflow for machine learning systems based on existing certification standards to tackle the previously mentioned challenges. We will walk you through all the steps in the workflow, from defining the ML requirements, managing the data, training the model, and verifying its performance to the implementation of the system in hardware and validation of the requirements. This case study will provide insights and potential solutions across industries with safety-critical components seeking to integrate neural networks into their operations.
Highlights
- Learn about gaps between Machine Learning development and Certification (e.g., for DO-178C, ISO26262).
- Learn about a custom ML certification workflow designed to tackle these certification challenges within the framework of existing standards.
- Explore a case study of an airborne system developed in compliance with the proposed custom ML certification workflow.
About the Presenter
Lucas Garcia is a principal product manager for deep learning at MathWorks with more than 15 years of machine learning experience and research in the computer software industry. He works with customer-facing and development teams to define, develop, and launch new capabilities and applications that meet customer needs and market trends in deep learning. Lucas joined MathWorks in 2008 as a customer-facing engineer and has worked with engineers and scientists across industries to help them tackle real-world problems in AI. Before joining MathWorks, he worked as a software developer in finance. Lucas holds a Ph.D. in applied mathematics from the Complutense University of Madrid and Polytechnic University of Madrid.
Recorded: 26 Mar 2024
Featured Product