Distribución normal
Visión general
La distribución normal, a veces llamada gausiana, es una familia de curvas de dos parámetros. La justificación habitual del uso de la distribución normal para la modelización es el teorema del límite central, que establece, a grandes rasgos, que la suma de muestras independientes de cualquier distribución con media y varianza finitas converge a la distribución normal a medida que el tamaño de la muestra se eleva al infinito.
Statistics and Machine Learning Toolbox™ ofrece distintas formas de trabajar con la distribución normal.
Cree un objeto de distribución de probabilidad
NormalDistributionajustando una distribución de probabilidad a datos de muestra (fitdist) o especificando valores de parámetros (makedist). Después, utilice las funciones del objeto para evaluar la distribución, generar números aleatorios, etc.Trabaje con la distribución normal de forma interactiva utilizando la app Distribution Fitter. Puede exportar un objeto de la app y utilizar las funciones del objeto.
Utilice funciones de distribución específicas (
normcdf,normpdf,norminv,normlike,normstat,normfit,normrnd) con los parámetros de distribución especificados. Las funciones específicas de distribución pueden aceptar parámetros de varias distribuciones normales.Utilice funciones de distribución genéricas (
cdf,icdf,pdf,random) con un nombre de distribución específico ('Normal') y parámetros.
Parámetros
La distribución normal utiliza estos parámetros.
| Parámetro | Descripción | Soporte |
|---|---|---|
mu (μ) | Media | |
sigma (σ) | Desviación estándar |
La distribución normal estándar tiene una media de cero y una desviación estándar de la unidad. Si z es normal estándar, σz + µ también es normal con una media de µ y una desviación estándar de σ. A la inversa, si x es normal con una media de µ y una desviación estándar de σ, z = (x – µ) / σ es normal estándar.
Estimación de parámetros
Las estimaciones de máxima verosimilitud (MLE) son las estimaciones del parámetro que maximizan la función de probabilidad. Los estimadores de máxima verosimilitud de μ y σ2 para la distribución normal, respectivamente, son
y
es la media de la muestra para las muestras x1, x2, …, xn. La media de la muestra es un estimador no sesgado del parámetro μ. Sin embargo, s2MLE es un estimador sesgado del parámetro σ2, lo que significa que se espera que el valor no se equipare al parámetro.
El estimador insesgado de varianza mínima (MVUE) se usa de manera habitual para estimar los parámetros de la distribución normal. El MVUE es el estimador que tiene la varianza mínima de todos los estimadores insesgados de un parámetro. Los MVUE de los parámetros μ y σ2 de la distribución normal son la media de la muestra x̄ y varianza de la muestra s2, respectivamente.
Para ajustar la distribución normal a los datos y encontrar las estimaciones del parámetro, utilice normfit, fitdist o mle.
Para los datos no censurados,
normfityfitdistencuentran las estimaciones insesgadas ymleencuentra las estimaciones de máxima verosimilitud.Para los datos censurados,
normfit,fitdistymleencuentran las estimaciones de máxima verosimilitud.
A diferencia de normfit y mle que devuelven estimaciones de parámetros, fitdist devuelve el objeto de distribución de probabilidad ajustado NormalDistribution. Las propiedades del objeto mu y sigma almacenan las estimaciones del parámetro.
Para ver un ejemplo, consulte Ajustar un objeto de distribución normal.
Función de densidad de probabilidad
La función de densidad de probabilidad normal (pdf) es
La función de verosimilitud es la pdf vista como una función de los parámetros. Las estimaciones de máxima verosimilitud (MLE) son las estimaciones del parámetro que maximizan la función de probabilidad para los valores fijos de x.
Para ver un ejemplo, consulte Calcular y representar la pdf de distribución normal.
Función de distribución acumulativa
La función de distribución acumulativa (cdf) normal es
p es la probabilidad de que una sola observación de una distribución normal con parámetros μ y σ caiga en el intervalo (-∞,x].
La función de distribución acumulativa normal estándar de Φ(x) se relaciona de manera funcional con la función del error erf.
donde
Para ver un ejemplo, consulte Representar la cdf de distribución normal estándar
Ejemplos
Ajustar un objeto de distribución normal
Cargue los datos de muestra y cree un vector que contenga la primera columna de datos de notas de exámenes de los alumnos.
load examgrades
x = grades(:,1);Cree un objeto de distribución normal ajustándolo a los datos.
pd = fitdist(x,'Normal')pd =
NormalDistribution
Normal distribution
mu = 75.0083 [73.4321, 76.5846]
sigma = 8.7202 [7.7391, 9.98843]
Los intervalos que aparecen junto a las estimaciones de los parámetros son los intervalos de confianza del 95% para los parámetros de la distribución.
Estimar parámetros
Estime los parámetros de la distribución normal (la media y la desviación estándar) usando la función normfit.
Cargue los datos de muestra y cree un vector que contenga la primera columna de datos de notas de exámenes de los alumnos.
load examgrades
x = grades(:,1);Busque las estimaciones de los parámetros y los intervalos de confianza del 95%.
[mu,s,muci,sci] = normfit(x)
mu = 75.0083
s = 8.7202
muci = 2×1
73.4321
76.5846
sci = 2×1
7.7391
9.9884
La función normfit devuelve el estimador insesgado de la varianza mínima (MVUE) para , la raíz cuadrada del MVUE para y los intervalos de confianza del 95% para y .
Tenga en cuenta que el cuadrado de s es el MVUE de la varianza.
s^2
ans = 76.0419
Calcular y representar la pdf de distribución normal
Calcule la pdf de una distribución normal estándar, con los parámetros iguales a 0 y iguales a 1.
x = [-3:.1:3]; y = normpdf(x,0,1);
Represente la pdf.
plot(x,y)

Representar la cdf de distribución normal estándar
Cree un objeto de distribución normal estándar.
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
Especifique los valores de x y calcule la cdf.
x = -3:.1:3; p = cdf(pd,x);
Represente la cdf de la distribución normal estándar.
plot(x,p)

Comparar las pdf de distribución normal y gamma
La distribución tiene el parámetro de forma y el parámetro de ampliación . Para un a grande, , la distribución gamma se aproxima estrechamente a la distribución normal con la media y la varianza .
Calcule la pdf de una distribución gamma con los parámetros a = 100 y b = 5.
a = 100; b = 5; x = 250:750; y_gam = gampdf(x,a,b);
A modo de comparación, calcule la media, la desviación estándar y la pdf de la distribución normal a la que se aproxima gamma.
mu = a*b
mu = 500
sigma = sqrt(a*b^2)
sigma = 50
y_norm = normpdf(x,mu,sigma);
Represente las pdf de la distribución gamma y la distribución normal en la misma figura.
plot(x,y_gam,'-',x,y_norm,'-.') title('Gamma and Normal pdfs') xlabel('Observation') ylabel('Probability Density') legend('Gamma Distribution','Normal Distribution')

La pdf de la distribución normal se aproxima a la pdf de la distribución gamma.
Relación entre las distribuciones normal y lognormal
Si X sigue la distribución lognormal con los parámetros µ y σ, log(X) sigue la distribución normal con la media µ y la desviación estándar σ. Utilice los objetos de distribución para inspeccionar la relación entre las distribuciones normales y lognormales.
Cree un objeto de distribución lognormal especificando los valores del parámetro.
pd = makedist('Lognormal','mu',5,'sigma',2)
pd =
LognormalDistribution
Lognormal distribution
mu = 5
sigma = 2
Calcule la media de la distribución lognormal.
mean(pd)
ans = 1.0966e+03
La media de la distribución lognormal no es igual al parámetro mu. La media de los valores logarítmicos es igual a mu. Confirme esta relación generando números aleatorios.
Genere números aleatorios de la distribución lognormal y calcule sus valores logarítmicos.
rng('default'); % For reproducibility x = random(pd,10000,1); logx = log(x);
Calcule la media de los valores logarítmicos.
m = mean(logx)
m = 5.0033
La media del logaritmo de x está cerca del parámetro mu de x, porque x tiene una distribución lognormal.
Construya un histograma de logx con un ajuste de distribución normal.
histfit(logx)

La gráfica muestra que los valores logarítmicos de x se distribuyen de manera normal.
histfit utiliza fitdist para ajustar una distribución a los datos. Utilice fitdist para obtener los parámetros utilizados en el ajuste.
pd_normal = fitdist(logx,'Normal')pd_normal =
NormalDistribution
Normal distribution
mu = 5.00332 [4.96445, 5.04219]
sigma = 1.98296 [1.95585, 2.01083]
Los parámetros de distribución normales estimados están cerca de los parámetros de distribución lognormal 5 y 2.
Comparar las pdf de la distribución normal y t de Student
La distribución t de Student es una familia de curvas que depende de un solo parámetro v (los grados de libertad). A medida que los grados de libertad de v se acercan a infinito, la distribución t se acerca a la distribución normal estándar.
Calcule las pdf de la distribución t de Student con el parámetro nu = 5 y la distribución t de Student con el parámetro nu = 15.
x = [-5:0.1:5]; y1 = tpdf(x,5); y2 = tpdf(x,15);
Calcule la pdf de una distribución normal estándar.
z = normpdf(x,0,1);
Represente las pdf de la distribución t de Student y la pdf normal estándar en la misma figura.
plot(x,y1,'-.',x,y2,'--',x,z,'-') legend('Student''s t Distribution with \nu=5', ... 'Student''s t Distribution with \nu=15', ... 'Standard Normal Distribution','Location','best') xlabel('Observation') ylabel('Probability Density') title('Student''s t and Standard Normal pdfs')
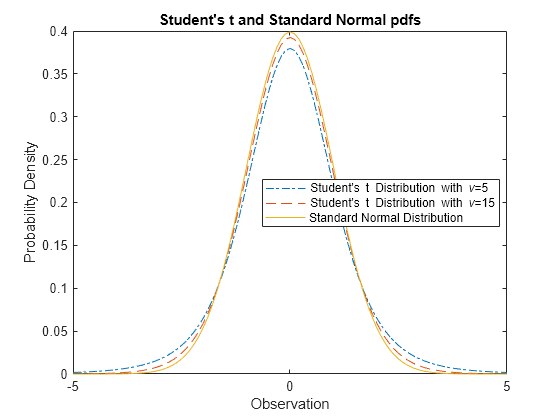
La pdf normal estándar tiene colas más breves que las pdf de la distribución t de Student.
Distribuciones relacionadas
Distribución binomial — La distribución binomial modela el número total de éxitos en n pruebas repetidas con la probabilidad de éxito p. A medida que n aumenta, una distribución normal con µ = np y σ2 = np(1–p) puede aproximarse a la distribución binomial. Consulte Comparar las pdf de la distribución binomial y normal.
Birnbaum-Saunders Distribution — Si x tiene una distribución Birnbaum-Saunders con parámetros β y γ,
tiene una distribución estándar.
Distribución chi-cuadrado — La distribución chi-cuadrado es la distribución de la suma de las variables aleatorias, normales estándar, independientes y cuadradas. Si un conjunto de observaciones de n se distribuye normalmente con la varianza σ2 y s2 es la varianza de la muestra, (n–1)s2/σ2 tiene una distribución chi-cuadrado con grados de libertad de n–1. La función
normfitutiliza esta relación para calcular los intervalos de confianza para la estimación del parámetro normal σ2.Extreme Value Distribution — La distribución del valor extremo es apropiada para la modelización del valor más pequeño o más grande de una distribución cuyas colas decrecen exponencialmente más rápido, como por ejemplo, la distribución normal.
Distribución gamma — La distribución tiene el parámetro de forma a y el parámetro de ampliación b. Para un a grande, la distribución gamma se aproxima estrechamente a la distribución normal con la media μ = ab y la varianza σ2 = ab2. La distribución gamma tiene densidad solo para números reales positivos. Consulte Comparar las pdf de distribución normal y gamma.
Half-Normal Distribution — La distribución seminormal es un caso especial de las distribuciones normal plegada y normal truncada. Si una variable aleatoria de
Ztiene una distribución normal estándar, tiene una distribución seminormal con los parámetros μ y σ.Distribución logística — La distribución lógica se utiliza para los modelos de crecimiento y en una regresión lógica. Tiene colas más largas y una curtosis mayor que la distribución normal.
Distribución lognormal — Si X sigue la distribución lognormal con los parámetros µ y σ, log(X) sigue la distribución normal con la media µ y la desviación estándar σ. Consulte Relación entre las distribuciones normal y lognormal.
Distribución normal multivariante — La distribución normal multivariada es una generalización de la normal univariada a dos o más variables. Es una distribución para vectores aleatorios de variables correlacionadas, en la que cada elemento tiene una distribución normal univariada. En el caso más sencillo, no hay correlación entre las variables y los elementos de los vectores son variables aleatorias normales univariadas e independientes.
Distribución de Poisson — La distribución Poisson es una distribución discreta de un parámetro que toma valores enteros no negativos. El parámetro, λ, es la media y la varianza de la distribución. A medida que λ aumenta, una distribución Poisson con µ = λ y σ2 = λ puede aproximarse a la distribución normal.
Distribución de Rayleigh — La distribución de Rayleigh es un caso especial de la distribución de Weibull con aplicaciones en la teoría de las comunicaciones. Si las velocidades del componente de una partícula en las direcciones x e y son dos variables aleatorias normales independientes con varianzas iguales y medias de cero, la distancia que recorre la partícula por unidad de tiempo sigue la distribución de Rayleigh.
Stable Distribution — La distribución normal es un caso especial de distribución estable. La distribución estable con el primer parámetro de forma α = 2 se corresponde con la distribución normal.
Distribución t de Student — La distribución t de Student es una familia de curvas que depende de un solo parámetro ν (los grados de libertad). A medida que los grados de libertad de ν se acercan a infinito, la distribución t se acerca a la distribución normal estándar. Consulte Comparar las pdf de la distribución normal y t de Student.
Si x es una muestra aleatoria de tamaño n de una distribución normal con una media de μ, la estadística
en la que es la media de la muestra y s es la desviación estándar de la muestra, tiene la distribución t de Student con n–1 grados de libertad.
t Location-Scale Distribution — La distribución de escala y ubicación de t es útil para las distribuciones de datos de modelización con colas más pesadas (más propensas a valores atípicos) que la distribución normal. Se acerca a la distribución normal a medida que el parámetro de forma v se acerca a infinito.
Referencias
[1] Abramowitz, M., and I. A. Stegun. Handbook of Mathematical Functions. New York: Dover, 1964.
[2] Evans, M., N. Hastings, and B. Peacock. Statistical Distributions. 2nd ed. Hoboken, NJ: John Wiley & Sons, Inc., 1993.
[3] Lawless, J. F. Statistical Models and Methods for Lifetime Data. Hoboken, NJ: Wiley-Interscience, 1982.
[4] Marsaglia, G., and W. W. Tsang. “A Fast, Easily Implemented Method for Sampling from Decreasing or Symmetric Unimodal Density Functions.” SIAM Journal on Scientific and Statistical Computing. Vol. 5, Number 2, 1984, pp. 349–359.
[5] Meeker, W. Q., and L. A. Escobar. Statistical Methods for Reliability Data. Hoboken, NJ: John Wiley & Sons, Inc., 1998.
Consulte también
NormalDistribution | normcdf | normpdf | norminv | normlike | normstat | normfit | normrnd | erf