random
Números aleatorios
Sintaxis
Descripción
R = random(___,sz1,...,szN)sz1,...,szN indica el tamaño de cada dimensión.
Ejemplos
Genere un número aleatorio a partir de la distribución normal con la media igual a 1 y la desviación estándar igual a 5. Especifique el nombre de distribución 'Normal' y los parámetros de la distribución.
rng('default') % For reproducibility mu = 1; sigma = 5; r = random('Normal',mu,sigma)
r = 3.6883
Cree un objeto de distribución normal y genere un número aleatorio usando el objeto.
Cree un objeto de distribución normal con la media igual a 1 y la desviación estándar iguales a 5.
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
Genere un número aleatorio a partir de la distribución.
rng('default') % For reproducibility r = random(pd)
r = 3.6883
Guarde el estado actual del generador de números aleatorios. Luego genere un número aleatorio a partir de la distribución de Poisson con el parámetro de tasa 5.
s = rng;
r = random('Poisson',5)r = 5
Reinicie el estado del generador de números aleatorios a s y después cree un nuevo número aleatorio. El valor es el mismo que antes.
rng(s);
r1 = random('Poisson',5)r1 = 5
Cree una matriz de números aleatorios del mismo tamaño que un arreglo existente. Use la distribución estable con los parámetro de forma 2 y 0, el parámetro de escala 1 y el parámetro de localización 0.
A = [3 2; -2 1];
sz = size(A);
R = random('Stable',2,0,1,0,sz)R = 2×2
0.7604 -3.1945
2.5935 1.2193
Puede combinar las dos líneas de código anteriores en una sola línea.
R = random('Stable',2,0,1,0,size(A))R = 2×2
0.4508 -0.6132
-1.8494 0.4845
Cree un objeto de distribución de probabilidad de Weibull usando los valores predeterminados de los parámetros.
pd = makedist('Weibull')pd =
WeibullDistribution
Weibull distribution
A = 1
B = 1
Genere números aleatorios a partir de la distribución.
rng('default') % For reproducibility r = random(pd,10000,1);
Construya un histograma usando 100 bins con un ajuste de distribución de Weibull.
histfit(r,100,'weibull')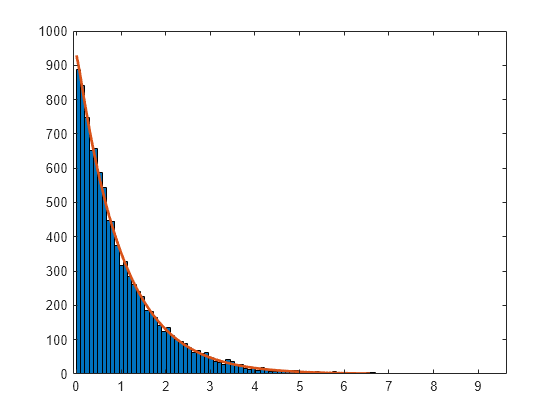
Cree un objeto de distribución de probabilidad normal estándar.
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
Genere un arreglo de números aleatorios de 2 por 3 por 2 a partir de la distribución.
r = random(pd,[2,3,2])
r =
r(:,:,1) =
0.5377 -2.2588 0.3188
1.8339 0.8622 -1.3077
r(:,:,2) =
-0.4336 3.5784 -1.3499
0.3426 2.7694 3.0349
Argumentos de entrada
Argumentos de salida
Funcionalidad alternativa
randomes una función genérica que acepta una distribución por su nombrenameo un objeto de distribución de probabilidadpd. Es más rápido usar una función específica de la distribución, comorandnynormrndpara la distribución normal ybinorndpara la distribución binomial. Para obtener una lista de las funciones específicas de las distribuciones, consulte Distribuciones admitidas.Para generar números aleatorios de forma interactiva, utilice
randtool, una interfaz de usuario para la generación de números aleatorios.